
Deep learning for NeuroImaging in Python.
Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the gallery for the big picture.
- class nidl.losses.beta_vae.BetaVAELoss(beta: float = 4.0, default_dist: str = 'normal')[source]¶
Bases:
objectCompute the Beta-VAE loss [R29].
See Also:
VAEThe Beta-VAE was introduced to learn disentangled representations and improve interpretability. The idea is to keep the distance between the real and estimated posterior distribution small (under a small constant delta) while maximizing the probability of generating real data:
![\underset{\phi, \theta}{\mathrm{max}}
\underset{x \sim D}{\mathbb{E}}\left[
\underset{z \sim q_\phi(z | x)}{\mathbb{E}}
log \ p_\theta(x|z)
\right] \\
\text{subject to} D_{KL}(q_\phi(z|x) | p_\theta(z)) < \delta](../_images/math/627e76dfaa0c1a30d2fcbf9bee4d07f8ebb91b96.png)
We can rewrite this equation as a Lagrangian with a Lagrangian multiplier
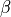 , which leads to the Beta-VAE loss function:
, which leads to the Beta-VAE loss function: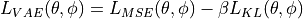
When
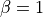 , it corresponds to a VAE loss. If
, it corresponds to a VAE loss. If 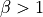 ,
this puts more weight on statistical independence than on reconstruction.
Note that such a stronger constraint on the latent bottleneck limits
the representation capacity of z.
,
this puts more weight on statistical independence than on reconstruction.
Note that such a stronger constraint on the latent bottleneck limits
the representation capacity of z.- Parameters:
beta : float, default=4.0
Weight of the KL divergence.
default_dist : {“normal”, “laplace”, “bernoulli”}, default=”normal”
Default decoder distribution. It defines the reconstruction loss (L2 for Normal, L1 for Laplace, cross-entropy for Bernoulli).
- Raises:
ValueError
If the input distribution is not supported.
References
- kl_normal_loss(q)[source]¶
Computes the KL divergence between a normal distribution with diagonal covariance and a unit normal distribution.
- Parameters:
q : torch.distributions
probabilistic encoder (or estimated posterior probability function).
- reconstruction_loss(p, data)[source]¶
Computes the per image reconstruction loss for a batch of data (i.e. negative log likelihood).
The distribution of the likelihood on the each pixel implicitely defines the loss. Bernoulli corresponds to a binary cross entropy. Gaussian distribution corresponds to MSE. Laplace distribution corresponds to L1.
- Parameters:
p : torch.distributions
probabilistic decoder (or likelihood of generating true data sample given the latent code).
data : torch.Tensor
The observed data.
- Returns:
loss : torch.Tensor
per image cross entropy (i.e. normalized per batch but not pixel and channel).
Follow us