
Deep learning for NeuroImaging in Python.
Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the gallery for the big picture.
- class nidl.losses.yaware_infonce.YAwareInfoNCE(kernel: str = 'gaussian', bandwidth: float | list[float] | ndarray | KernelMetric = 1.0, temperature: float = 0.1)[source]¶
Bases:
ModuleImplementation of the y-Aware InfoNCE loss [R34].
Compute the y-Aware InfoNCE loss, which integrates auxiliary information into contrastive learning by weighting sample pairs.
Given a mini-batch of size
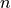 , two embeddings
, two embeddings 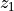 and
and
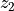 representing two views of the same samples and a weighting
matrix
representing two views of the same samples and a weighting
matrix 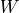 computed using auxiliary variables
computed using auxiliary variables 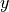 , the loss is:
, the loss is: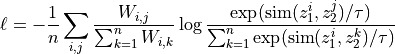
where
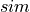 is the cosine similarity and
is the cosine similarity and 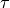 is the
temperature. is computed with a kernel
is the
temperature. is computed with a kernel 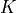 (e.g. Gaussian) and bandwidth
(e.g. Gaussian) and bandwidth
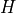 as:
as: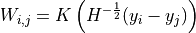
- Parameters:
kernel : str in {‘gaussian’, ‘epanechnikov’, ‘exponential’, ‘linear’, ‘cosine’}, default=’gaussian’
Kernel to compute the weighting matrix between auxiliary variables. See PhD thesis, Dufumier 2022 page 94-95.
bandwidth : Union[float, int, List[float], array, KernelMetric], default=1.0
The method used to calculate the bandwidth (
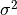 in [R34])
between auxiliary variables:
in [R34])
between auxiliary variables:If bandwidth is a scalar (int or float), it sets the bandwidth to a diagnonal matrix with equal values.
If bandwidth is a 1d array, it sets the bandwidth to a diagonal matrix and it must be of size equal to the number of features in y.
If bandwidth is a 2d array, it must be of shape (n_features, n_features) where n_features is the number of features in y.
If bandwidth is
KernelMetric, it uses the pairwise method to compute the similarity matrix between auxiliary variables.
temperature : float, default=0.1
Temperature used to scale the dot-product between embedded vectors
References
[R34] (1,2,3)Dufumier, B., et al., “Contrastive learning with continuous proxy meta-data for 3D MRI classification.” MICCAI, 2021. https://arxiv.org/abs/2106.08808
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- forward(z1: Tensor, z2: Tensor, labels: Tensor | None = None)[source]¶
- Parameters:
z1 : torch.Tensor of shape (batch_size, n_features)
First embedded view.
z2 : torch.Tensor of shape (batch_size, n_features)
Second embedded view.
labels : Optional[torch.Tensor] of shape (batch_size, n_labels)
Auxiliary variables associated to the input data. If None, the standard InfoNCE loss is returned.
- Returns:
loss : torch.Tensor
The y-Aware InfoNCE loss computed between z1 and z2.
Follow us