Note
Go to the end to download the full example code.
Decoupled Contrastive Learning¶
This tutorial illustrates the use of Decoupled Contrastive Learning (DCL) [1] which introduces a reformulation of the InfoNCE loss used in SimCLR [2] that removes the negative-positive coupling in the loss. This modification stabilizes optimization and improves performance, especially when training with small batch sizes.
In this tutorial, we will use the CIFAR10 dataset to train models based on DCL and SimCLR and compare their performances for different batch sizes using the nidl library.
We will follow these steps:
Load the CIFAR10 dataset.
Define the data augmentations for self-supervised training.
Define the DCL and SimCLR models.
Train the models for different batch sizes.
Compare the obtained representations on CIFAR10 test set with linear probing.
Setup¶
This notebook requires some packages besides nidl. Let’s first start with importing our standard libraries below:
import matplotlib.pyplot as plt
import numpy as np
import torch
from lightning_fabric import seed_everything
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from torch import nn
from torch.utils.data import DataLoader, Subset
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torchvision.models import resnet18
from nidl.estimators.ssl import DCL, SimCLR
from nidl.transforms.transforms import MultiViewsTransform
from nidl.utils.weights import Weights
We define some global parameters that will be used throughout the notebook. The parameter load_trained_models allows you to directly load the weights of the trained models from HuggingFace hub instead of training them directly in the notebook which takes time and resources (~3h on a NVIDIA RTX 4500 GPU).
Path where data should be downloaded
data_dir = "/tmp/cifar10"
# Whether to load the pretrained models or train them on your device
load_pretrained = True
# If loading model, directory where to save the weights
model_dir = "/tmp/nidl_example_dcl_vs_simclr"
# What accelerator to use: GPU if available, else CPU
accelerator = "gpu" if torch.cuda.is_available() else "cpu"
# Latent size of the representation
# /!\ If changing latent_size then you cannot load pretrained weights
latent_size = 128
# Number of workers (cpu cores) to use in dataloaders
num_workers = 4
# We fix the seed and generator for reproducibility
seed = 42
rd_generator = np.random.default_rng(seed=seed)
seed = seed_everything(seed)
Check parameters values
if latent_size != 128 and load_pretrained == True:
raise ValueError(
"Pretrained models have a latent size of 128 which can"
" not be modified. Set load_pretrained=True or"
" latent_size=128"
)
DCL Loss Function¶
The DCL loss function is based on InfoNCE and is defined as:
![\mathcal{L}_i^{(k)}
= - \big(\operatorname{sim}(z_i^{(1)}, z_i^{(2)})/\tau\big)
+ \log
\sum\limits_{l \in \{1,2\}, j \in \![1,N\!]}
\mathbf{1}_{[j \ne i]},
\exp\!\big(\operatorname{sim}(z_i^{(k)}, z_j^{(l)})/\tau\big)](../_images/math/b3ee4cfb31b08d23eb79b52e97c0f07fda0d7870.png)
Where:
- 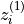 and
and 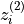 are embeddings of two different
augmented views of the same image
-
are embeddings of two different
augmented views of the same image
- 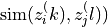 is the cosine similarity
between normalized embeddings
-
is the cosine similarity
between normalized embeddings
- 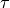 is a temperature parameter controlling the concentration of
the distribution
-
is a temperature parameter controlling the concentration of
the distribution
- ![\mathbf{1}_{[j \ne i]}](../_images/math/01c2cfb0d00fb1132ac748d4d5c272ecc6462ad0.png) is an indicator function that ensures
decoupling
is an indicator function that ensures
decoupling
The key idea in DCL is to remove the contribution of the positive pair from the log-sum-exp normalization term of the InfoNCE loss. In standard InfoNCE, this term creates an implicit coupling between positive and negative similarities, which can bias gradient estimates when the batch size is small. By decoupling these terms, DCL reduces this bias and leads to more stable contrastive learning.
#
# Data Preparation
# -----------------
#
# We'll use the CIFAR10 dataset, which contains 50,000 training images and
# 10,000 test images of 10 different classes. We'll apply standard scaling
# transforms, the test dataset will be used to evaluate the model performance
# on the classification task. We subsample the dataset for faster inference.
#
# Load CIFAR10 dataset with standard scaling
#
# We subsample the test dataset to run the notebook faster.
scale_transforms = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
train_xy_dataset = CIFAR10(
data_dir, train=True, transform=scale_transforms, download=True
)
train_indices = rd_generator.choice(
np.arange(len(train_xy_dataset)), size=10000, replace=False
)
train_xy_dataset = Subset(train_xy_dataset, train_indices)
test_xy_dataset = CIFAR10(
data_dir, train=False, transform=scale_transforms, download=True
)
test_indices = rd_generator.choice(
np.arange(len(test_xy_dataset)), size=5000, replace=False
)
test_xy_dataset = Subset(test_xy_dataset, test_indices)
0%| | 0.00/170M [00:00<?, ?B/s]
0%| | 32.8k/170M [00:00<28:58, 98.1kB/s]
0%| | 65.5k/170M [00:00<25:33, 111kB/s]
0%| | 98.3k/170M [00:01<30:48, 92.2kB/s]
0%| | 131k/170M [00:01<28:18, 100kB/s]
0%| | 164k/170M [00:01<29:11, 97.3kB/s]
0%| | 197k/170M [00:01<27:57, 102kB/s]
0%| | 229k/170M [00:02<30:41, 92.4kB/s]
0%| | 262k/170M [00:02<26:55, 105kB/s]
0%| | 295k/170M [00:02<27:05, 105kB/s]
0%| | 328k/170M [00:03<25:20, 112kB/s]
0%| | 360k/170M [00:03<36:31, 77.6kB/s]
0%| | 393k/170M [00:04<38:44, 73.2kB/s]
0%| | 426k/170M [00:05<47:09, 60.1kB/s]
0%| | 459k/170M [00:05<41:19, 68.6kB/s]
0%| | 492k/170M [00:05<38:09, 74.3kB/s]
0%| | 524k/170M [00:06<40:53, 69.3kB/s]
0%| | 557k/170M [00:06<41:35, 68.1kB/s]
0%| | 590k/170M [00:07<36:21, 77.9kB/s]
0%| | 623k/170M [00:07<36:44, 77.1kB/s]
0%| | 655k/170M [00:07<34:05, 83.0kB/s]
0%| | 688k/170M [00:08<33:18, 85.0kB/s]
0%| | 721k/170M [00:08<28:24, 99.6kB/s]
0%| | 754k/170M [00:08<25:20, 112kB/s]
0%| | 786k/170M [00:08<23:21, 121kB/s]
0%| | 819k/170M [00:09<21:35, 131kB/s]
0%| | 852k/170M [00:09<20:13, 140kB/s]
1%| | 885k/170M [00:09<20:45, 136kB/s]
1%| | 918k/170M [00:09<21:10, 133kB/s]
1%| | 950k/170M [00:10<20:45, 136kB/s]
1%| | 983k/170M [00:10<19:05, 148kB/s]
1%| | 1.02M/170M [00:10<18:23, 154kB/s]
1%| | 1.05M/170M [00:10<19:56, 142kB/s]
1%| | 1.08M/170M [00:10<19:17, 146kB/s]
1%| | 1.11M/170M [00:11<18:49, 150kB/s]
1%| | 1.15M/170M [00:11<19:29, 145kB/s]
1%| | 1.18M/170M [00:11<18:32, 152kB/s]
1%| | 1.21M/170M [00:11<18:23, 153kB/s]
1%| | 1.25M/170M [00:11<18:28, 153kB/s]
1%| | 1.28M/170M [00:12<18:49, 150kB/s]
1%| | 1.31M/170M [00:12<18:14, 155kB/s]
1%| | 1.34M/170M [00:12<18:38, 151kB/s]
1%| | 1.38M/170M [00:12<19:22, 145kB/s]
1%| | 1.41M/170M [00:13<19:40, 143kB/s]
1%| | 1.44M/170M [00:13<18:51, 149kB/s]
1%| | 1.47M/170M [00:13<17:55, 157kB/s]
1%| | 1.51M/170M [00:13<18:37, 151kB/s]
1%| | 1.54M/170M [00:13<19:35, 144kB/s]
1%| | 1.57M/170M [00:14<17:22, 162kB/s]
1%| | 1.61M/170M [00:14<17:31, 161kB/s]
1%| | 1.64M/170M [00:14<17:32, 160kB/s]
1%| | 1.67M/170M [00:15<47:34, 59.2kB/s]
1%| | 1.70M/170M [00:16<43:37, 64.5kB/s]
1%| | 1.74M/170M [00:16<39:07, 71.9kB/s]
1%| | 1.77M/170M [00:16<36:21, 77.4kB/s]
1%| | 1.80M/170M [00:17<34:14, 82.1kB/s]
1%| | 1.84M/170M [00:17<32:10, 87.4kB/s]
1%| | 1.87M/170M [00:17<30:01, 93.6kB/s]
1%| | 1.90M/170M [00:18<30:40, 91.6kB/s]
1%| | 1.93M/170M [00:18<29:49, 94.2kB/s]
1%| | 1.97M/170M [00:18<28:44, 97.8kB/s]
1%| | 2.00M/170M [00:19<29:53, 94.0kB/s]
1%| | 2.03M/170M [00:19<26:25, 106kB/s]
1%| | 2.06M/170M [00:19<29:30, 95.1kB/s]
1%| | 2.10M/170M [00:20<26:26, 106kB/s]
1%| | 2.13M/170M [00:20<27:37, 102kB/s]
1%|▏ | 2.16M/170M [00:20<28:02, 100kB/s]
1%|▏ | 2.20M/170M [00:21<31:45, 88.3kB/s]
1%|▏ | 2.23M/170M [00:21<32:01, 87.6kB/s]
1%|▏ | 2.26M/170M [00:22<34:20, 81.6kB/s]
1%|▏ | 2.29M/170M [00:22<36:01, 77.8kB/s]
1%|▏ | 2.33M/170M [00:23<38:04, 73.6kB/s]
1%|▏ | 2.36M/170M [00:23<41:18, 67.9kB/s]
1%|▏ | 2.39M/170M [00:24<41:18, 67.8kB/s]
1%|▏ | 2.42M/170M [00:24<38:00, 73.7kB/s]
1%|▏ | 2.46M/170M [00:24<36:59, 75.7kB/s]
1%|▏ | 2.49M/170M [00:25<35:03, 79.9kB/s]
1%|▏ | 2.52M/170M [00:25<38:38, 72.5kB/s]
1%|▏ | 2.56M/170M [00:26<36:56, 75.8kB/s]
2%|▏ | 2.59M/170M [00:26<36:09, 77.4kB/s]
2%|▏ | 2.62M/170M [00:27<37:15, 75.1kB/s]
2%|▏ | 2.65M/170M [00:27<44:27, 62.9kB/s]
2%|▏ | 2.69M/170M [00:28<39:39, 70.5kB/s]
2%|▏ | 2.72M/170M [00:28<33:58, 82.3kB/s]
2%|▏ | 2.75M/170M [00:28<30:28, 91.7kB/s]
2%|▏ | 2.79M/170M [00:28<26:46, 104kB/s]
2%|▏ | 2.82M/170M [00:29<23:34, 119kB/s]
2%|▏ | 2.85M/170M [00:29<21:58, 127kB/s]
2%|▏ | 2.88M/170M [00:29<25:23, 110kB/s]
2%|▏ | 2.92M/170M [00:30<33:10, 84.2kB/s]
2%|▏ | 2.95M/170M [00:30<28:40, 97.4kB/s]
2%|▏ | 2.98M/170M [00:30<24:41, 113kB/s]
2%|▏ | 3.01M/170M [00:30<23:24, 119kB/s]
2%|▏ | 3.05M/170M [00:31<20:39, 135kB/s]
2%|▏ | 3.08M/170M [00:31<22:02, 127kB/s]
2%|▏ | 3.11M/170M [00:31<24:53, 112kB/s]
2%|▏ | 3.15M/170M [00:32<25:07, 111kB/s]
2%|▏ | 3.18M/170M [00:32<23:38, 118kB/s]
2%|▏ | 3.21M/170M [00:32<21:36, 129kB/s]
2%|▏ | 3.24M/170M [00:32<21:25, 130kB/s]
2%|▏ | 3.28M/170M [00:33<21:18, 131kB/s]
2%|▏ | 3.31M/170M [00:33<19:27, 143kB/s]
2%|▏ | 3.34M/170M [00:33<19:37, 142kB/s]
2%|▏ | 3.38M/170M [00:33<18:43, 149kB/s]
2%|▏ | 3.41M/170M [00:33<18:50, 148kB/s]
2%|▏ | 3.44M/170M [00:34<19:30, 143kB/s]
2%|▏ | 3.47M/170M [00:34<18:48, 148kB/s]
2%|▏ | 3.51M/170M [00:34<20:07, 138kB/s]
2%|▏ | 3.54M/170M [00:34<18:58, 147kB/s]
2%|▏ | 3.57M/170M [00:35<19:36, 142kB/s]
2%|▏ | 3.60M/170M [00:35<18:20, 152kB/s]
2%|▏ | 3.64M/170M [00:35<19:03, 146kB/s]
2%|▏ | 3.67M/170M [00:35<18:35, 149kB/s]
2%|▏ | 3.70M/170M [00:35<18:48, 148kB/s]
2%|▏ | 3.74M/170M [00:36<17:46, 156kB/s]
2%|▏ | 3.77M/170M [00:36<19:38, 142kB/s]
2%|▏ | 3.80M/170M [00:36<18:15, 152kB/s]
2%|▏ | 3.83M/170M [00:36<18:56, 147kB/s]
2%|▏ | 3.87M/170M [00:36<17:29, 159kB/s]
2%|▏ | 3.90M/170M [00:37<20:08, 138kB/s]
2%|▏ | 3.93M/170M [00:37<21:59, 126kB/s]
2%|▏ | 3.96M/170M [00:37<20:18, 137kB/s]
2%|▏ | 4.00M/170M [00:37<20:40, 134kB/s]
2%|▏ | 4.03M/170M [00:38<19:55, 139kB/s]
2%|▏ | 4.06M/170M [00:38<19:27, 143kB/s]
2%|▏ | 4.10M/170M [00:38<20:44, 134kB/s]
2%|▏ | 4.13M/170M [00:38<20:59, 132kB/s]
2%|▏ | 4.16M/170M [00:39<21:18, 130kB/s]
2%|▏ | 4.19M/170M [00:39<20:03, 138kB/s]
2%|▏ | 4.23M/170M [00:39<20:18, 136kB/s]
2%|▏ | 4.26M/170M [00:39<19:24, 143kB/s]
3%|▎ | 4.29M/170M [00:40<18:27, 150kB/s]
3%|▎ | 4.33M/170M [00:40<18:06, 153kB/s]
3%|▎ | 4.36M/170M [00:40<19:59, 138kB/s]
3%|▎ | 4.39M/170M [00:40<20:00, 138kB/s]
3%|▎ | 4.42M/170M [00:41<19:08, 145kB/s]
3%|▎ | 4.46M/170M [00:41<20:10, 137kB/s]
3%|▎ | 4.49M/170M [00:41<18:52, 147kB/s]
3%|▎ | 4.52M/170M [00:41<19:05, 145kB/s]
3%|▎ | 4.55M/170M [00:41<18:22, 150kB/s]
3%|▎ | 4.59M/170M [00:42<18:09, 152kB/s]
3%|▎ | 4.62M/170M [00:42<17:16, 160kB/s]
3%|▎ | 4.65M/170M [00:42<17:42, 156kB/s]
3%|▎ | 4.69M/170M [00:42<19:00, 145kB/s]
3%|▎ | 4.72M/170M [00:42<17:57, 154kB/s]
3%|▎ | 4.75M/170M [00:43<18:25, 150kB/s]
3%|▎ | 4.78M/170M [00:43<19:24, 142kB/s]
3%|▎ | 4.82M/170M [00:43<19:15, 143kB/s]
3%|▎ | 4.85M/170M [00:43<17:51, 155kB/s]
3%|▎ | 4.88M/170M [00:44<18:05, 153kB/s]
3%|▎ | 4.92M/170M [00:44<18:30, 149kB/s]
3%|▎ | 4.95M/170M [00:44<18:00, 153kB/s]
3%|▎ | 4.98M/170M [00:44<17:02, 162kB/s]
3%|▎ | 5.01M/170M [00:44<17:30, 158kB/s]
3%|▎ | 5.05M/170M [00:45<18:04, 153kB/s]
3%|▎ | 5.08M/170M [00:45<18:17, 151kB/s]
3%|▎ | 5.11M/170M [00:45<17:07, 161kB/s]
3%|▎ | 5.14M/170M [00:45<18:26, 150kB/s]
3%|▎ | 5.18M/170M [00:45<18:31, 149kB/s]
3%|▎ | 5.21M/170M [00:46<18:11, 151kB/s]
3%|▎ | 5.24M/170M [00:46<19:08, 144kB/s]
3%|▎ | 5.28M/170M [00:46<18:04, 152kB/s]
3%|▎ | 5.31M/170M [00:46<17:13, 160kB/s]
3%|▎ | 5.34M/170M [00:47<17:08, 161kB/s]
3%|▎ | 5.37M/170M [00:47<18:45, 147kB/s]
3%|▎ | 5.41M/170M [00:47<18:08, 152kB/s]
3%|▎ | 5.44M/170M [00:47<20:20, 135kB/s]
3%|▎ | 5.47M/170M [00:48<24:02, 114kB/s]
3%|▎ | 5.51M/170M [00:48<24:05, 114kB/s]
3%|▎ | 5.54M/170M [00:48<24:21, 113kB/s]
3%|▎ | 5.57M/170M [00:49<24:57, 110kB/s]
3%|▎ | 5.60M/170M [00:49<29:18, 93.8kB/s]
3%|▎ | 5.64M/170M [00:50<37:41, 72.9kB/s]
3%|▎ | 5.67M/170M [00:50<41:34, 66.1kB/s]
3%|▎ | 5.70M/170M [00:51<35:01, 78.4kB/s]
3%|▎ | 5.73M/170M [00:51<29:43, 92.4kB/s]
3%|▎ | 5.77M/170M [00:51<25:37, 107kB/s]
3%|▎ | 5.80M/170M [00:51<24:17, 113kB/s]
3%|▎ | 5.83M/170M [00:51<22:59, 119kB/s]
3%|▎ | 5.87M/170M [00:52<21:42, 126kB/s]
3%|▎ | 5.90M/170M [00:52<21:37, 127kB/s]
3%|▎ | 5.93M/170M [00:52<20:50, 132kB/s]
3%|▎ | 5.96M/170M [00:53<22:58, 119kB/s]
4%|▎ | 6.00M/170M [00:53<25:43, 107kB/s]
4%|▎ | 6.03M/170M [00:53<26:07, 105kB/s]
4%|▎ | 6.06M/170M [00:54<28:17, 96.9kB/s]
4%|▎ | 6.09M/170M [00:54<40:30, 67.7kB/s]
4%|▎ | 6.13M/170M [00:55<43:34, 62.9kB/s]
4%|▎ | 6.16M/170M [00:56<44:41, 61.3kB/s]
4%|▎ | 6.19M/170M [00:56<41:39, 65.7kB/s]
4%|▎ | 6.23M/170M [00:56<37:47, 72.4kB/s]
4%|▎ | 6.26M/170M [00:57<36:36, 74.8kB/s]
4%|▎ | 6.29M/170M [00:58<50:01, 54.7kB/s]
4%|▎ | 6.32M/170M [00:58<41:56, 65.2kB/s]
4%|▎ | 6.36M/170M [00:58<36:07, 75.7kB/s]
4%|▎ | 6.39M/170M [00:59<33:36, 81.4kB/s]
4%|▍ | 6.42M/170M [00:59<30:49, 88.7kB/s]
4%|▍ | 6.46M/170M [00:59<32:16, 84.7kB/s]
4%|▍ | 6.49M/170M [01:00<37:44, 72.4kB/s]
4%|▍ | 6.52M/170M [01:01<51:39, 52.9kB/s]
4%|▍ | 6.55M/170M [01:01<43:26, 62.9kB/s]
4%|▍ | 6.59M/170M [01:02<39:07, 69.8kB/s]
4%|▍ | 6.62M/170M [01:02<38:01, 71.8kB/s]
4%|▍ | 6.65M/170M [01:02<33:05, 82.5kB/s]
4%|▍ | 6.68M/170M [01:03<30:19, 90.1kB/s]
4%|▍ | 6.72M/170M [01:03<28:21, 96.3kB/s]
4%|▍ | 6.75M/170M [01:03<25:28, 107kB/s]
4%|▍ | 6.78M/170M [01:03<25:25, 107kB/s]
4%|▍ | 6.82M/170M [01:04<26:46, 102kB/s]
4%|▍ | 6.85M/170M [01:04<26:12, 104kB/s]
4%|▍ | 6.88M/170M [01:04<25:46, 106kB/s]
4%|▍ | 6.91M/170M [01:05<27:04, 101kB/s]
4%|▍ | 6.95M/170M [01:05<28:20, 96.2kB/s]
4%|▍ | 6.98M/170M [01:05<27:41, 98.4kB/s]
4%|▍ | 7.01M/170M [01:06<27:56, 97.5kB/s]
4%|▍ | 7.05M/170M [01:06<28:27, 95.7kB/s]
4%|▍ | 7.08M/170M [01:06<28:19, 96.1kB/s]
4%|▍ | 7.11M/170M [01:07<28:59, 93.9kB/s]
4%|▍ | 7.14M/170M [01:07<27:08, 100kB/s]
4%|▍ | 7.18M/170M [01:07<27:00, 101kB/s]
4%|▍ | 7.21M/170M [01:08<26:17, 104kB/s]
4%|▍ | 7.24M/170M [01:08<22:49, 119kB/s]
4%|▍ | 7.27M/170M [01:08<22:09, 123kB/s]
4%|▍ | 7.31M/170M [01:08<21:20, 127kB/s]
4%|▍ | 7.34M/170M [01:09<23:02, 118kB/s]
4%|▍ | 7.37M/170M [01:09<22:40, 120kB/s]
4%|▍ | 7.41M/170M [01:09<22:46, 119kB/s]
4%|▍ | 7.44M/170M [01:10<24:09, 112kB/s]
4%|▍ | 7.47M/170M [01:10<23:56, 114kB/s]
4%|▍ | 7.50M/170M [01:10<23:44, 114kB/s]
4%|▍ | 7.54M/170M [01:11<26:18, 103kB/s]
4%|▍ | 7.57M/170M [01:11<24:31, 111kB/s]
4%|▍ | 7.60M/170M [01:11<22:57, 118kB/s]
4%|▍ | 7.63M/170M [01:11<22:10, 122kB/s]
4%|▍ | 7.67M/170M [01:11<20:20, 133kB/s]
5%|▍ | 7.70M/170M [01:12<20:29, 132kB/s]
5%|▍ | 7.73M/170M [01:12<19:51, 137kB/s]
5%|▍ | 7.77M/170M [01:12<19:41, 138kB/s]
5%|▍ | 7.80M/170M [01:12<20:47, 130kB/s]
5%|▍ | 7.83M/170M [01:13<21:01, 129kB/s]
5%|▍ | 7.86M/170M [01:13<21:35, 126kB/s]
5%|▍ | 7.90M/170M [01:13<22:01, 123kB/s]
5%|▍ | 7.93M/170M [01:13<20:41, 131kB/s]
5%|▍ | 7.96M/170M [01:14<20:41, 131kB/s]
5%|▍ | 8.00M/170M [01:14<20:53, 130kB/s]
5%|▍ | 8.03M/170M [01:14<20:02, 135kB/s]
5%|▍ | 8.06M/170M [01:14<20:50, 130kB/s]
5%|▍ | 8.09M/170M [01:15<24:10, 112kB/s]
5%|▍ | 8.13M/170M [01:16<33:58, 79.7kB/s]
5%|▍ | 8.16M/170M [01:16<32:56, 82.1kB/s]
5%|▍ | 8.19M/170M [01:16<34:27, 78.5kB/s]
5%|▍ | 8.22M/170M [01:17<30:36, 88.3kB/s]
5%|▍ | 8.26M/170M [01:17<29:01, 93.2kB/s]
5%|▍ | 8.29M/170M [01:17<27:42, 97.6kB/s]
5%|▍ | 8.32M/170M [01:17<24:51, 109kB/s]
5%|▍ | 8.36M/170M [01:18<23:47, 114kB/s]
5%|▍ | 8.39M/170M [01:18<22:34, 120kB/s]
5%|▍ | 8.42M/170M [01:18<22:08, 122kB/s]
5%|▍ | 8.45M/170M [01:18<21:51, 124kB/s]
5%|▍ | 8.49M/170M [01:19<21:51, 124kB/s]
5%|▍ | 8.52M/170M [01:19<21:19, 127kB/s]
5%|▌ | 8.55M/170M [01:19<25:02, 108kB/s]
5%|▌ | 8.59M/170M [01:20<23:27, 115kB/s]
5%|▌ | 8.62M/170M [01:20<22:22, 121kB/s]
5%|▌ | 8.65M/170M [01:20<22:52, 118kB/s]
5%|▌ | 8.68M/170M [01:20<22:27, 120kB/s]
5%|▌ | 8.72M/170M [01:21<21:18, 127kB/s]
5%|▌ | 8.75M/170M [01:21<21:17, 127kB/s]
5%|▌ | 8.78M/170M [01:21<21:31, 125kB/s]
5%|▌ | 8.81M/170M [01:22<23:50, 113kB/s]
5%|▌ | 8.85M/170M [01:22<22:54, 118kB/s]
5%|▌ | 8.88M/170M [01:22<26:33, 101kB/s]
5%|▌ | 8.91M/170M [01:22<25:07, 107kB/s]
5%|▌ | 8.95M/170M [01:23<25:04, 107kB/s]
5%|▌ | 8.98M/170M [01:23<22:04, 122kB/s]
5%|▌ | 9.01M/170M [01:23<22:53, 118kB/s]
5%|▌ | 9.04M/170M [01:23<21:14, 127kB/s]
5%|▌ | 9.08M/170M [01:24<22:49, 118kB/s]
5%|▌ | 9.11M/170M [01:24<21:40, 124kB/s]
5%|▌ | 9.14M/170M [01:24<21:38, 124kB/s]
5%|▌ | 9.18M/170M [01:24<19:51, 135kB/s]
5%|▌ | 9.21M/170M [01:25<19:53, 135kB/s]
5%|▌ | 9.24M/170M [01:25<22:03, 122kB/s]
5%|▌ | 9.27M/170M [01:25<22:33, 119kB/s]
5%|▌ | 9.31M/170M [01:26<21:43, 124kB/s]
5%|▌ | 9.34M/170M [01:26<20:44, 129kB/s]
5%|▌ | 9.37M/170M [01:26<21:09, 127kB/s]
6%|▌ | 9.40M/170M [01:26<21:56, 122kB/s]
6%|▌ | 9.44M/170M [01:27<22:35, 119kB/s]
6%|▌ | 9.47M/170M [01:27<22:30, 119kB/s]
6%|▌ | 9.50M/170M [01:27<22:19, 120kB/s]
6%|▌ | 9.54M/170M [01:27<22:54, 117kB/s]
6%|▌ | 9.57M/170M [01:28<23:02, 116kB/s]
6%|▌ | 9.60M/170M [01:28<22:00, 122kB/s]
6%|▌ | 9.63M/170M [01:28<21:23, 125kB/s]
6%|▌ | 9.67M/170M [01:29<21:04, 127kB/s]
6%|▌ | 9.70M/170M [01:29<21:17, 126kB/s]
6%|▌ | 9.73M/170M [01:29<19:42, 136kB/s]
6%|▌ | 9.76M/170M [01:29<21:08, 127kB/s]
6%|▌ | 9.80M/170M [01:29<19:54, 135kB/s]
6%|▌ | 9.83M/170M [01:30<20:22, 131kB/s]
6%|▌ | 9.86M/170M [01:30<21:01, 127kB/s]
6%|▌ | 9.90M/170M [01:30<21:56, 122kB/s]
6%|▌ | 9.93M/170M [01:31<22:27, 119kB/s]
6%|▌ | 9.96M/170M [01:31<23:43, 113kB/s]
6%|▌ | 9.99M/170M [01:31<22:58, 116kB/s]
6%|▌ | 10.0M/170M [01:31<23:29, 114kB/s]
6%|▌ | 10.1M/170M [01:32<23:24, 114kB/s]
6%|▌ | 10.1M/170M [01:32<21:20, 125kB/s]
6%|▌ | 10.1M/170M [01:32<21:36, 124kB/s]
6%|▌ | 10.2M/170M [01:33<22:03, 121kB/s]
6%|▌ | 10.2M/170M [01:33<21:37, 124kB/s]
6%|▌ | 10.2M/170M [01:33<23:05, 116kB/s]
6%|▌ | 10.3M/170M [01:34<26:22, 101kB/s]
6%|▌ | 10.3M/170M [01:34<24:54, 107kB/s]
6%|▌ | 10.3M/170M [01:34<24:15, 110kB/s]
6%|▌ | 10.4M/170M [01:34<23:43, 112kB/s]
6%|▌ | 10.4M/170M [01:35<21:26, 124kB/s]
6%|▌ | 10.4M/170M [01:35<21:02, 127kB/s]
6%|▌ | 10.5M/170M [01:35<20:54, 128kB/s]
6%|▌ | 10.5M/170M [01:35<20:19, 131kB/s]
6%|▌ | 10.5M/170M [01:36<20:27, 130kB/s]
6%|▌ | 10.6M/170M [01:36<20:02, 133kB/s]
6%|▌ | 10.6M/170M [01:36<20:31, 130kB/s]
6%|▌ | 10.6M/170M [01:36<20:25, 130kB/s]
6%|▌ | 10.6M/170M [01:37<21:43, 123kB/s]
6%|▋ | 10.7M/170M [01:37<20:40, 129kB/s]
6%|▋ | 10.7M/170M [01:37<23:17, 114kB/s]
6%|▋ | 10.7M/170M [01:37<22:58, 116kB/s]
6%|▋ | 10.8M/170M [01:38<21:49, 122kB/s]
6%|▋ | 10.8M/170M [01:38<21:36, 123kB/s]
6%|▋ | 10.8M/170M [01:38<21:39, 123kB/s]
6%|▋ | 10.9M/170M [01:38<21:43, 122kB/s]
6%|▋ | 10.9M/170M [01:39<20:52, 127kB/s]
6%|▋ | 10.9M/170M [01:39<21:26, 124kB/s]
6%|▋ | 11.0M/170M [01:39<21:56, 121kB/s]
6%|▋ | 11.0M/170M [01:40<21:03, 126kB/s]
6%|▋ | 11.0M/170M [01:40<23:14, 114kB/s]
6%|▋ | 11.1M/170M [01:40<23:10, 115kB/s]
7%|▋ | 11.1M/170M [01:40<23:30, 113kB/s]
7%|▋ | 11.1M/170M [01:41<24:58, 106kB/s]
7%|▋ | 11.2M/170M [01:41<27:37, 96.1kB/s]
7%|▋ | 11.2M/170M [01:41<26:05, 102kB/s]
7%|▋ | 11.2M/170M [01:42<27:32, 96.4kB/s]
7%|▋ | 11.3M/170M [01:42<29:26, 90.1kB/s]
7%|▋ | 11.3M/170M [01:43<29:01, 91.4kB/s]
7%|▋ | 11.3M/170M [01:43<27:35, 96.1kB/s]
7%|▋ | 11.4M/170M [01:43<26:33, 99.9kB/s]
7%|▋ | 11.4M/170M [01:43<24:37, 108kB/s]
7%|▋ | 11.4M/170M [01:44<24:07, 110kB/s]
7%|▋ | 11.5M/170M [01:44<22:28, 118kB/s]
7%|▋ | 11.5M/170M [01:44<21:13, 125kB/s]
7%|▋ | 11.5M/170M [01:44<20:19, 130kB/s]
7%|▋ | 11.6M/170M [01:45<19:59, 133kB/s]
7%|▋ | 11.6M/170M [01:45<21:41, 122kB/s]
7%|▋ | 11.6M/170M [01:45<26:30, 99.9kB/s]
7%|▋ | 11.7M/170M [01:46<25:46, 103kB/s]
7%|▋ | 11.7M/170M [01:46<25:12, 105kB/s]
7%|▋ | 11.7M/170M [01:46<24:00, 110kB/s]
7%|▋ | 11.8M/170M [01:47<23:17, 114kB/s]
7%|▋ | 11.8M/170M [01:47<24:17, 109kB/s]
7%|▋ | 11.8M/170M [01:47<26:40, 99.2kB/s]
7%|▋ | 11.9M/170M [01:48<25:46, 103kB/s]
7%|▋ | 11.9M/170M [01:48<26:01, 102kB/s]
7%|▋ | 11.9M/170M [01:48<25:06, 105kB/s]
7%|▋ | 12.0M/170M [01:49<26:21, 100kB/s]
7%|▋ | 12.0M/170M [01:49<24:34, 107kB/s]
7%|▋ | 12.0M/170M [01:49<24:57, 106kB/s]
7%|▋ | 12.1M/170M [01:49<22:53, 115kB/s]
7%|▋ | 12.1M/170M [01:50<22:34, 117kB/s]
7%|▋ | 12.1M/170M [01:50<22:34, 117kB/s]
7%|▋ | 12.2M/170M [01:50<22:59, 115kB/s]
7%|▋ | 12.2M/170M [01:51<22:46, 116kB/s]
7%|▋ | 12.2M/170M [01:51<22:23, 118kB/s]
7%|▋ | 12.3M/170M [01:51<22:21, 118kB/s]
7%|▋ | 12.3M/170M [01:51<24:03, 110kB/s]
7%|▋ | 12.3M/170M [01:52<24:20, 108kB/s]
7%|▋ | 12.4M/170M [01:52<24:36, 107kB/s]
7%|▋ | 12.4M/170M [01:52<22:56, 115kB/s]
7%|▋ | 12.4M/170M [01:53<22:41, 116kB/s]
7%|▋ | 12.5M/170M [01:53<22:55, 115kB/s]
7%|▋ | 12.5M/170M [01:53<24:07, 109kB/s]
7%|▋ | 12.5M/170M [01:53<22:03, 119kB/s]
7%|▋ | 12.6M/170M [01:54<23:22, 113kB/s]
7%|▋ | 12.6M/170M [01:54<22:55, 115kB/s]
7%|▋ | 12.6M/170M [01:54<24:29, 107kB/s]
7%|▋ | 12.6M/170M [01:55<25:10, 104kB/s]
7%|▋ | 12.7M/170M [01:55<24:15, 108kB/s]
7%|▋ | 12.7M/170M [01:55<24:00, 110kB/s]
7%|▋ | 12.7M/170M [01:56<24:08, 109kB/s]
7%|▋ | 12.8M/170M [01:56<21:26, 123kB/s]
8%|▊ | 12.8M/170M [01:56<20:50, 126kB/s]
8%|▊ | 12.8M/170M [01:56<21:23, 123kB/s]
8%|▊ | 12.9M/170M [01:56<20:00, 131kB/s]
8%|▊ | 12.9M/170M [01:57<19:55, 132kB/s]
8%|▊ | 12.9M/170M [01:57<20:11, 130kB/s]
8%|▊ | 13.0M/170M [01:57<20:05, 131kB/s]
8%|▊ | 13.0M/170M [01:57<19:18, 136kB/s]
8%|▊ | 13.0M/170M [01:58<19:11, 137kB/s]
8%|▊ | 13.1M/170M [01:58<22:52, 115kB/s]
8%|▊ | 13.1M/170M [01:58<23:05, 114kB/s]
8%|▊ | 13.1M/170M [01:59<22:06, 119kB/s]
8%|▊ | 13.2M/170M [01:59<22:12, 118kB/s]
8%|▊ | 13.2M/170M [01:59<21:56, 119kB/s]
8%|▊ | 13.2M/170M [01:59<20:07, 130kB/s]
8%|▊ | 13.3M/170M [02:00<21:29, 122kB/s]
8%|▊ | 13.3M/170M [02:00<19:51, 132kB/s]
8%|▊ | 13.3M/170M [02:00<21:44, 120kB/s]
8%|▊ | 13.4M/170M [02:00<20:08, 130kB/s]
8%|▊ | 13.4M/170M [02:01<20:51, 126kB/s]
8%|▊ | 13.4M/170M [02:01<21:54, 119kB/s]
8%|▊ | 13.5M/170M [02:01<21:07, 124kB/s]
8%|▊ | 13.5M/170M [02:01<20:36, 127kB/s]
8%|▊ | 13.5M/170M [02:02<20:59, 125kB/s]
8%|▊ | 13.6M/170M [02:02<19:22, 135kB/s]
8%|▊ | 13.6M/170M [02:02<20:02, 130kB/s]
8%|▊ | 13.6M/170M [02:02<20:16, 129kB/s]
8%|▊ | 13.7M/170M [02:03<21:28, 122kB/s]
8%|▊ | 13.7M/170M [02:03<22:30, 116kB/s]
8%|▊ | 13.7M/170M [02:03<21:10, 123kB/s]
8%|▊ | 13.8M/170M [02:04<20:54, 125kB/s]
8%|▊ | 13.8M/170M [02:04<20:17, 129kB/s]
8%|▊ | 13.8M/170M [02:04<21:23, 122kB/s]
8%|▊ | 13.9M/170M [02:04<21:43, 120kB/s]
8%|▊ | 13.9M/170M [02:05<20:06, 130kB/s]
8%|▊ | 13.9M/170M [02:05<19:41, 133kB/s]
8%|▊ | 14.0M/170M [02:05<19:46, 132kB/s]
8%|▊ | 14.0M/170M [02:05<22:36, 115kB/s]
8%|▊ | 14.0M/170M [02:06<21:09, 123kB/s]
8%|▊ | 14.1M/170M [02:06<21:26, 122kB/s]
8%|▊ | 14.1M/170M [02:06<21:08, 123kB/s]
8%|▊ | 14.1M/170M [02:06<20:24, 128kB/s]
8%|▊ | 14.2M/170M [02:07<20:32, 127kB/s]
8%|▊ | 14.2M/170M [02:07<21:06, 123kB/s]
8%|▊ | 14.2M/170M [02:07<21:48, 119kB/s]
8%|▊ | 14.3M/170M [02:08<22:54, 114kB/s]
8%|▊ | 14.3M/170M [02:08<21:15, 122kB/s]
8%|▊ | 14.3M/170M [02:08<21:10, 123kB/s]
8%|▊ | 14.4M/170M [02:08<22:22, 116kB/s]
8%|▊ | 14.4M/170M [02:09<22:39, 115kB/s]
8%|▊ | 14.4M/170M [02:09<21:35, 121kB/s]
8%|▊ | 14.5M/170M [02:09<22:22, 116kB/s]
8%|▊ | 14.5M/170M [02:09<21:20, 122kB/s]
9%|▊ | 14.5M/170M [02:10<21:02, 124kB/s]
9%|▊ | 14.5M/170M [02:10<19:56, 130kB/s]
9%|▊ | 14.6M/170M [02:10<19:08, 136kB/s]
9%|▊ | 14.6M/170M [02:10<18:42, 139kB/s]
9%|▊ | 14.6M/170M [02:11<19:01, 136kB/s]
9%|▊ | 14.7M/170M [02:11<22:10, 117kB/s]
9%|▊ | 14.7M/170M [02:11<23:02, 113kB/s]
9%|▊ | 14.7M/170M [02:12<25:37, 101kB/s]
9%|▊ | 14.8M/170M [02:12<34:31, 75.2kB/s]
9%|▊ | 14.8M/170M [02:13<38:20, 67.7kB/s]
9%|▊ | 14.8M/170M [02:14<41:02, 63.2kB/s]
9%|▊ | 14.9M/170M [02:14<41:47, 62.1kB/s]
9%|▊ | 14.9M/170M [02:15<42:01, 61.7kB/s]
9%|▉ | 14.9M/170M [02:15<38:56, 66.6kB/s]
9%|▉ | 15.0M/170M [02:16<46:24, 55.9kB/s]
9%|▉ | 15.0M/170M [02:16<37:56, 68.3kB/s]
9%|▉ | 15.0M/170M [02:16<33:33, 77.2kB/s]
9%|▉ | 15.1M/170M [02:17<28:22, 91.3kB/s]
9%|▉ | 15.1M/170M [02:17<25:17, 102kB/s]
9%|▉ | 15.1M/170M [02:17<23:59, 108kB/s]
9%|▉ | 15.2M/170M [02:17<22:44, 114kB/s]
9%|▉ | 15.2M/170M [02:18<21:09, 122kB/s]
9%|▉ | 15.2M/170M [02:18<19:21, 134kB/s]
9%|▉ | 15.3M/170M [02:18<19:04, 136kB/s]
9%|▉ | 15.3M/170M [02:18<19:16, 134kB/s]
9%|▉ | 15.3M/170M [02:19<18:10, 142kB/s]
9%|▉ | 15.4M/170M [02:19<19:17, 134kB/s]
9%|▉ | 15.4M/170M [02:19<19:40, 131kB/s]
9%|▉ | 15.4M/170M [02:19<18:46, 138kB/s]
9%|▉ | 15.5M/170M [02:20<22:14, 116kB/s]
9%|▉ | 15.5M/170M [02:20<31:45, 81.4kB/s]
9%|▉ | 15.5M/170M [02:21<30:30, 84.6kB/s]
9%|▉ | 15.6M/170M [02:21<28:29, 90.7kB/s]
9%|▉ | 15.6M/170M [02:21<26:20, 98.0kB/s]
9%|▉ | 15.6M/170M [02:22<27:21, 94.4kB/s]
9%|▉ | 15.7M/170M [02:22<26:05, 98.9kB/s]
9%|▉ | 15.7M/170M [02:22<26:34, 97.1kB/s]
9%|▉ | 15.7M/170M [02:23<32:29, 79.4kB/s]
9%|▉ | 15.8M/170M [02:24<42:57, 60.0kB/s]
9%|▉ | 15.8M/170M [02:25<50:08, 51.4kB/s]
9%|▉ | 15.8M/170M [02:27<1:35:20, 27.0kB/s]
9%|▉ | 15.9M/170M [02:28<1:20:43, 31.9kB/s]
9%|▉ | 15.9M/170M [02:28<1:05:55, 39.1kB/s]
9%|▉ | 15.9M/170M [02:28<54:27, 47.3kB/s]
9%|▉ | 16.0M/170M [02:29<45:35, 56.5kB/s]
9%|▉ | 16.0M/170M [02:29<38:43, 66.5kB/s]
9%|▉ | 16.0M/170M [02:29<34:43, 74.2kB/s]
9%|▉ | 16.1M/170M [02:30<34:52, 73.8kB/s]
9%|▉ | 16.1M/170M [02:30<30:49, 83.5kB/s]
9%|▉ | 16.1M/170M [02:30<29:12, 88.1kB/s]
9%|▉ | 16.2M/170M [02:31<26:52, 95.7kB/s]
9%|▉ | 16.2M/170M [02:31<29:52, 86.1kB/s]
10%|▉ | 16.2M/170M [02:31<27:36, 93.1kB/s]
10%|▉ | 16.3M/170M [02:32<29:33, 87.0kB/s]
10%|▉ | 16.3M/170M [02:32<29:35, 86.8kB/s]
10%|▉ | 16.3M/170M [02:33<29:34, 86.9kB/s]
10%|▉ | 16.4M/170M [02:33<29:30, 87.0kB/s]
10%|▉ | 16.4M/170M [02:33<31:04, 82.7kB/s]
10%|▉ | 16.4M/170M [02:34<30:03, 85.4kB/s]
10%|▉ | 16.4M/170M [02:34<30:07, 85.2kB/s]
10%|▉ | 16.5M/170M [02:35<29:55, 85.8kB/s]
10%|▉ | 16.5M/170M [02:35<31:04, 82.6kB/s]
10%|▉ | 16.5M/170M [02:35<28:35, 89.8kB/s]
10%|▉ | 16.6M/170M [02:36<25:49, 99.3kB/s]
10%|▉ | 16.6M/170M [02:36<24:57, 103kB/s]
10%|▉ | 16.6M/170M [02:36<24:01, 107kB/s]
10%|▉ | 16.7M/170M [02:36<21:38, 118kB/s]
10%|▉ | 16.7M/170M [02:37<22:55, 112kB/s]
10%|▉ | 16.7M/170M [02:37<23:26, 109kB/s]
10%|▉ | 16.8M/170M [02:37<24:19, 105kB/s]
10%|▉ | 16.8M/170M [02:38<22:13, 115kB/s]
10%|▉ | 16.8M/170M [02:38<21:02, 122kB/s]
10%|▉ | 16.9M/170M [02:38<22:18, 115kB/s]
10%|▉ | 16.9M/170M [02:38<24:23, 105kB/s]
10%|▉ | 16.9M/170M [02:39<23:17, 110kB/s]
10%|▉ | 17.0M/170M [02:39<22:58, 111kB/s]
10%|▉ | 17.0M/170M [02:39<22:58, 111kB/s]
10%|▉ | 17.0M/170M [02:40<21:53, 117kB/s]
10%|█ | 17.1M/170M [02:40<22:48, 112kB/s]
10%|█ | 17.1M/170M [02:40<24:30, 104kB/s]
10%|█ | 17.1M/170M [02:41<22:41, 113kB/s]
10%|█ | 17.2M/170M [02:41<23:48, 107kB/s]
10%|█ | 17.2M/170M [02:41<22:15, 115kB/s]
10%|█ | 17.2M/170M [02:41<23:54, 107kB/s]
10%|█ | 17.3M/170M [02:42<21:58, 116kB/s]
10%|█ | 17.3M/170M [02:42<33:09, 77.0kB/s]
10%|█ | 17.3M/170M [02:43<32:20, 78.9kB/s]
10%|█ | 17.4M/170M [02:44<42:03, 60.7kB/s]
10%|█ | 17.4M/170M [02:44<35:32, 71.8kB/s]
10%|█ | 17.4M/170M [02:44<32:44, 77.9kB/s]
10%|█ | 17.5M/170M [02:44<28:32, 89.3kB/s]
10%|█ | 17.5M/170M [02:45<37:23, 68.2kB/s]
10%|█ | 17.5M/170M [02:46<35:46, 71.3kB/s]
10%|█ | 17.6M/170M [02:46<32:42, 77.9kB/s]
10%|█ | 17.6M/170M [02:46<31:31, 80.8kB/s]
10%|█ | 17.6M/170M [02:47<29:32, 86.3kB/s]
10%|█ | 17.7M/170M [02:47<31:23, 81.2kB/s]
10%|█ | 17.7M/170M [02:47<27:18, 93.3kB/s]
10%|█ | 17.7M/170M [02:48<27:34, 92.3kB/s]
10%|█ | 17.8M/170M [02:48<27:52, 91.3kB/s]
10%|█ | 17.8M/170M [02:48<27:48, 91.5kB/s]
10%|█ | 17.8M/170M [02:49<27:07, 93.8kB/s]
10%|█ | 17.9M/170M [02:49<25:08, 101kB/s]
10%|█ | 17.9M/170M [02:49<23:54, 106kB/s]
11%|█ | 17.9M/170M [02:50<23:35, 108kB/s]
11%|█ | 18.0M/170M [02:50<21:31, 118kB/s]
11%|█ | 18.0M/170M [02:50<21:16, 119kB/s]
11%|█ | 18.0M/170M [02:50<19:17, 132kB/s]
11%|█ | 18.1M/170M [02:51<19:35, 130kB/s]
11%|█ | 18.1M/170M [02:51<19:42, 129kB/s]
11%|█ | 18.1M/170M [02:51<18:54, 134kB/s]
11%|█ | 18.2M/170M [02:51<18:45, 135kB/s]
11%|█ | 18.2M/170M [02:52<19:40, 129kB/s]
11%|█ | 18.2M/170M [02:52<18:57, 134kB/s]
11%|█ | 18.3M/170M [02:52<17:28, 145kB/s]
11%|█ | 18.3M/170M [02:52<18:12, 139kB/s]
11%|█ | 18.3M/170M [02:52<18:07, 140kB/s]
11%|█ | 18.4M/170M [02:53<17:16, 147kB/s]
11%|█ | 18.4M/170M [02:53<17:58, 141kB/s]
11%|█ | 18.4M/170M [02:53<17:32, 144kB/s]
11%|█ | 18.4M/170M [02:53<19:48, 128kB/s]
11%|█ | 18.5M/170M [02:54<18:42, 135kB/s]
11%|█ | 18.5M/170M [02:54<17:55, 141kB/s]
11%|█ | 18.5M/170M [02:54<17:31, 145kB/s]
11%|█ | 18.6M/170M [02:54<16:58, 149kB/s]
11%|█ | 18.6M/170M [02:54<16:33, 153kB/s]
11%|█ | 18.6M/170M [02:55<16:18, 155kB/s]
11%|█ | 18.7M/170M [02:55<17:11, 147kB/s]
11%|█ | 18.7M/170M [02:55<18:29, 137kB/s]
11%|█ | 18.7M/170M [02:55<17:10, 147kB/s]
11%|█ | 18.8M/170M [02:56<18:41, 135kB/s]
11%|█ | 18.8M/170M [02:56<17:55, 141kB/s]
11%|█ | 18.8M/170M [02:56<16:50, 150kB/s]
11%|█ | 18.9M/170M [02:56<19:13, 131kB/s]
11%|█ | 18.9M/170M [02:57<23:03, 110kB/s]
11%|█ | 18.9M/170M [02:57<22:48, 111kB/s]
11%|█ | 19.0M/170M [02:57<23:20, 108kB/s]
11%|█ | 19.0M/170M [02:58<24:18, 104kB/s]
11%|█ | 19.0M/170M [02:58<22:52, 110kB/s]
11%|█ | 19.1M/170M [02:58<22:29, 112kB/s]
11%|█ | 19.1M/170M [02:59<23:41, 106kB/s]
11%|█ | 19.1M/170M [02:59<26:27, 95.3kB/s]
11%|█ | 19.2M/170M [02:59<27:43, 91.0kB/s]
11%|█▏ | 19.2M/170M [03:00<29:04, 86.7kB/s]
11%|█▏ | 19.2M/170M [03:00<27:31, 91.6kB/s]
11%|█▏ | 19.3M/170M [03:01<33:05, 76.2kB/s]
11%|█▏ | 19.3M/170M [03:01<29:28, 85.5kB/s]
11%|█▏ | 19.3M/170M [03:01<30:50, 81.7kB/s]
11%|█▏ | 19.4M/170M [03:02<29:35, 85.1kB/s]
11%|█▏ | 19.4M/170M [03:02<27:06, 92.9kB/s]
11%|█▏ | 19.4M/170M [03:02<25:19, 99.4kB/s]
11%|█▏ | 19.5M/170M [03:03<27:53, 90.2kB/s]
11%|█▏ | 19.5M/170M [03:03<28:26, 88.5kB/s]
11%|█▏ | 19.5M/170M [03:03<26:13, 95.9kB/s]
11%|█▏ | 19.6M/170M [03:04<24:27, 103kB/s]
11%|█▏ | 19.6M/170M [03:04<26:31, 94.8kB/s]
12%|█▏ | 19.6M/170M [03:04<23:45, 106kB/s]
12%|█▏ | 19.7M/170M [03:05<24:16, 104kB/s]
12%|█▏ | 19.7M/170M [03:05<21:14, 118kB/s]
12%|█▏ | 19.7M/170M [03:05<23:13, 108kB/s]
12%|█▏ | 19.8M/170M [03:06<25:03, 100kB/s]
12%|█▏ | 19.8M/170M [03:06<27:34, 91.1kB/s]
12%|█▏ | 19.8M/170M [03:07<29:42, 84.6kB/s]
12%|█▏ | 19.9M/170M [03:07<29:41, 84.6kB/s]
12%|█▏ | 19.9M/170M [03:08<44:31, 56.4kB/s]
12%|█▏ | 19.9M/170M [03:08<39:50, 63.0kB/s]
12%|█▏ | 20.0M/170M [03:09<46:11, 54.3kB/s]
12%|█▏ | 20.0M/170M [03:09<38:07, 65.8kB/s]
12%|█▏ | 20.0M/170M [03:10<34:18, 73.1kB/s]
12%|█▏ | 20.1M/170M [03:10<34:13, 73.3kB/s]
12%|█▏ | 20.1M/170M [03:12<59:35, 42.1kB/s]
12%|█▏ | 20.1M/170M [03:12<57:31, 43.6kB/s]
12%|█▏ | 20.2M/170M [03:13<59:12, 42.3kB/s]
12%|█▏ | 20.2M/170M [03:14<51:26, 48.7kB/s]
12%|█▏ | 20.2M/170M [03:14<46:15, 54.1kB/s]
12%|█▏ | 20.3M/170M [03:15<41:11, 60.8kB/s]
12%|█▏ | 20.3M/170M [03:15<38:03, 65.8kB/s]
12%|█▏ | 20.3M/170M [03:15<37:17, 67.1kB/s]
12%|█▏ | 20.3M/170M [03:16<33:44, 74.2kB/s]
12%|█▏ | 20.4M/170M [03:16<35:00, 71.5kB/s]
12%|█▏ | 20.4M/170M [03:17<41:53, 59.7kB/s]
12%|█▏ | 20.4M/170M [03:18<42:03, 59.5kB/s]
12%|█▏ | 20.5M/170M [03:18<39:38, 63.1kB/s]
12%|█▏ | 20.5M/170M [03:18<33:46, 74.0kB/s]
12%|█▏ | 20.5M/170M [03:18<27:43, 90.2kB/s]
12%|█▏ | 20.6M/170M [03:19<24:48, 101kB/s]
12%|█▏ | 20.6M/170M [03:19<22:28, 111kB/s]
12%|█▏ | 20.6M/170M [03:19<21:52, 114kB/s]
12%|█▏ | 20.7M/170M [03:19<21:12, 118kB/s]
12%|█▏ | 20.7M/170M [03:20<22:37, 110kB/s]
12%|█▏ | 20.7M/170M [03:20<21:31, 116kB/s]
12%|█▏ | 20.8M/170M [03:20<20:54, 119kB/s]
12%|█▏ | 20.8M/170M [03:21<21:02, 119kB/s]
12%|█▏ | 20.8M/170M [03:21<24:29, 102kB/s]
12%|█▏ | 20.9M/170M [03:21<23:48, 105kB/s]
12%|█▏ | 20.9M/170M [03:22<24:24, 102kB/s]
12%|█▏ | 20.9M/170M [03:22<23:15, 107kB/s]
12%|█▏ | 21.0M/170M [03:22<23:35, 106kB/s]
12%|█▏ | 21.0M/170M [03:22<23:15, 107kB/s]
12%|█▏ | 21.0M/170M [03:23<22:11, 112kB/s]
12%|█▏ | 21.1M/170M [03:23<23:23, 106kB/s]
12%|█▏ | 21.1M/170M [03:23<22:54, 109kB/s]
12%|█▏ | 21.1M/170M [03:24<22:50, 109kB/s]
12%|█▏ | 21.2M/170M [03:24<25:14, 98.6kB/s]
12%|█▏ | 21.2M/170M [03:24<23:20, 107kB/s]
12%|█▏ | 21.2M/170M [03:25<22:18, 111kB/s]
12%|█▏ | 21.3M/170M [03:25<20:43, 120kB/s]
12%|█▏ | 21.3M/170M [03:25<21:22, 116kB/s]
13%|█▎ | 21.3M/170M [03:25<20:17, 123kB/s]
13%|█▎ | 21.4M/170M [03:26<20:36, 121kB/s]
13%|█▎ | 21.4M/170M [03:26<19:58, 124kB/s]
13%|█▎ | 21.4M/170M [03:26<20:24, 122kB/s]
13%|█▎ | 21.5M/170M [03:26<19:23, 128kB/s]
13%|█▎ | 21.5M/170M [03:27<19:27, 128kB/s]
13%|█▎ | 21.5M/170M [03:27<28:16, 87.8kB/s]
13%|█▎ | 21.6M/170M [03:28<27:24, 90.6kB/s]
13%|█▎ | 21.6M/170M [03:28<33:09, 74.8kB/s]
13%|█▎ | 21.6M/170M [03:29<38:06, 65.1kB/s]
13%|█▎ | 21.7M/170M [03:30<52:37, 47.1kB/s]
13%|█▎ | 21.7M/170M [03:31<48:38, 51.0kB/s]
13%|█▎ | 21.7M/170M [03:31<43:22, 57.2kB/s]
13%|█▎ | 21.8M/170M [03:31<42:42, 58.1kB/s]
13%|█▎ | 21.8M/170M [03:32<36:24, 68.1kB/s]
13%|█▎ | 21.8M/170M [03:32<33:42, 73.5kB/s]
13%|█▎ | 21.9M/170M [03:33<32:25, 76.4kB/s]
13%|█▎ | 21.9M/170M [03:33<32:28, 76.3kB/s]
13%|█▎ | 21.9M/170M [03:34<44:30, 55.6kB/s]
13%|█▎ | 22.0M/170M [03:35<48:40, 50.9kB/s]
13%|█▎ | 22.0M/170M [03:35<40:52, 60.6kB/s]
13%|█▎ | 22.0M/170M [03:35<34:47, 71.1kB/s]
13%|█▎ | 22.1M/170M [03:36<34:39, 71.4kB/s]
13%|█▎ | 22.1M/170M [03:36<34:47, 71.1kB/s]
13%|█▎ | 22.1M/170M [03:37<34:09, 72.4kB/s]
13%|█▎ | 22.2M/170M [03:37<36:26, 67.9kB/s]
13%|█▎ | 22.2M/170M [03:38<36:30, 67.7kB/s]
13%|█▎ | 22.2M/170M [03:38<32:35, 75.8kB/s]
13%|█▎ | 22.2M/170M [03:38<29:24, 84.0kB/s]
13%|█▎ | 22.3M/170M [03:39<30:03, 82.2kB/s]
13%|█▎ | 22.3M/170M [03:39<29:26, 83.9kB/s]
13%|█▎ | 22.3M/170M [03:39<27:48, 88.8kB/s]
13%|█▎ | 22.4M/170M [03:40<28:57, 85.2kB/s]
13%|█▎ | 22.4M/170M [03:40<25:46, 95.8kB/s]
13%|█▎ | 22.4M/170M [03:40<25:43, 95.9kB/s]
13%|█▎ | 22.5M/170M [03:41<23:52, 103kB/s]
13%|█▎ | 22.5M/170M [03:41<22:10, 111kB/s]
13%|█▎ | 22.5M/170M [03:41<22:08, 111kB/s]
13%|█▎ | 22.6M/170M [03:41<19:17, 128kB/s]
13%|█▎ | 22.6M/170M [03:42<19:50, 124kB/s]
13%|█▎ | 22.6M/170M [03:42<17:32, 140kB/s]
13%|█▎ | 22.7M/170M [03:42<18:36, 132kB/s]
13%|█▎ | 22.7M/170M [03:42<19:39, 125kB/s]
13%|█▎ | 22.7M/170M [03:43<30:14, 81.4kB/s]
13%|█▎ | 22.8M/170M [03:43<27:03, 91.0kB/s]
13%|█▎ | 22.8M/170M [03:44<25:45, 95.6kB/s]
13%|█▎ | 22.8M/170M [03:44<23:11, 106kB/s]
13%|█▎ | 22.9M/170M [03:44<22:08, 111kB/s]
13%|█▎ | 22.9M/170M [03:44<20:19, 121kB/s]
13%|█▎ | 22.9M/170M [03:45<19:02, 129kB/s]
13%|█▎ | 23.0M/170M [03:45<18:32, 133kB/s]
13%|█▎ | 23.0M/170M [03:45<16:40, 147kB/s]
14%|█▎ | 23.0M/170M [03:45<16:36, 148kB/s]
14%|█▎ | 23.1M/170M [03:45<16:48, 146kB/s]
14%|█▎ | 23.1M/170M [03:46<15:41, 156kB/s]
14%|█▎ | 23.1M/170M [03:46<15:45, 156kB/s]
14%|█▎ | 23.2M/170M [03:46<15:48, 155kB/s]
14%|█▎ | 23.2M/170M [03:46<20:35, 119kB/s]
14%|█▎ | 23.2M/170M [03:47<21:01, 117kB/s]
14%|█▎ | 23.3M/170M [03:47<18:37, 132kB/s]
14%|█▎ | 23.3M/170M [03:47<18:46, 131kB/s]
14%|█▎ | 23.3M/170M [03:47<18:28, 133kB/s]
14%|█▎ | 23.4M/170M [03:48<20:43, 118kB/s]
14%|█▎ | 23.4M/170M [03:48<25:33, 95.9kB/s]
14%|█▎ | 23.4M/170M [03:49<33:07, 74.0kB/s]
14%|█▍ | 23.5M/170M [03:49<31:18, 78.3kB/s]
14%|█▍ | 23.5M/170M [03:50<32:59, 74.3kB/s]
14%|█▍ | 23.5M/170M [03:50<30:09, 81.2kB/s]
14%|█▍ | 23.6M/170M [03:50<28:56, 84.6kB/s]
14%|█▍ | 23.6M/170M [03:55<1:51:52, 21.9kB/s]
14%|█▍ | 23.6M/170M [03:55<1:24:31, 29.0kB/s]
14%|█▍ | 23.7M/170M [03:55<1:05:12, 37.5kB/s]
14%|█▍ | 23.7M/170M [03:55<50:22, 48.6kB/s]
14%|█▍ | 23.7M/170M [03:56<40:12, 60.9kB/s]
14%|█▍ | 23.8M/170M [03:56<33:26, 73.1kB/s]
14%|█▍ | 23.8M/170M [03:56<27:29, 88.9kB/s]
14%|█▍ | 23.8M/170M [03:56<23:56, 102kB/s]
14%|█▍ | 23.9M/170M [03:56<22:14, 110kB/s]
14%|█▍ | 23.9M/170M [03:57<20:45, 118kB/s]
14%|█▍ | 23.9M/170M [03:57<21:49, 112kB/s]
14%|█▍ | 24.0M/170M [03:57<18:22, 133kB/s]
14%|█▍ | 24.0M/170M [03:57<17:29, 140kB/s]
14%|█▍ | 24.0M/170M [03:58<17:01, 143kB/s]
14%|█▍ | 24.1M/170M [03:58<16:56, 144kB/s]
14%|█▍ | 24.1M/170M [03:58<15:58, 153kB/s]
14%|█▍ | 24.1M/170M [03:58<16:24, 149kB/s]
14%|█▍ | 24.2M/170M [03:58<15:55, 153kB/s]
14%|█▍ | 24.2M/170M [03:59<16:01, 152kB/s]
14%|█▍ | 24.2M/170M [03:59<15:53, 153kB/s]
14%|█▍ | 24.2M/170M [03:59<17:20, 141kB/s]
14%|█▍ | 24.3M/170M [03:59<16:51, 144kB/s]
14%|█▍ | 24.3M/170M [03:59<16:46, 145kB/s]
14%|█▍ | 24.3M/170M [04:00<17:30, 139kB/s]
14%|█▍ | 24.4M/170M [04:00<16:52, 144kB/s]
14%|█▍ | 24.4M/170M [04:00<16:33, 147kB/s]
14%|█▍ | 24.4M/170M [04:00<17:05, 142kB/s]
14%|█▍ | 24.5M/170M [04:01<16:22, 149kB/s]
14%|█▍ | 24.5M/170M [04:01<16:08, 151kB/s]
14%|█▍ | 24.5M/170M [04:01<15:54, 153kB/s]
14%|█▍ | 24.6M/170M [04:01<17:58, 135kB/s]
14%|█▍ | 24.6M/170M [04:02<16:55, 144kB/s]
14%|█▍ | 24.6M/170M [04:02<17:01, 143kB/s]
14%|█▍ | 24.7M/170M [04:02<17:32, 139kB/s]
14%|█▍ | 24.7M/170M [04:02<17:17, 140kB/s]
15%|█▍ | 24.7M/170M [04:02<17:22, 140kB/s]
15%|█▍ | 24.8M/170M [04:03<16:53, 144kB/s]
15%|█▍ | 24.8M/170M [04:03<16:55, 143kB/s]
15%|█▍ | 24.8M/170M [04:03<16:34, 146kB/s]
15%|█▍ | 24.9M/170M [04:03<16:33, 147kB/s]
15%|█▍ | 24.9M/170M [04:04<16:29, 147kB/s]
15%|█▍ | 24.9M/170M [04:04<19:10, 127kB/s]
15%|█▍ | 25.0M/170M [04:04<17:37, 138kB/s]
15%|█▍ | 25.0M/170M [04:04<16:49, 144kB/s]
15%|█▍ | 25.0M/170M [04:05<16:39, 145kB/s]
15%|█▍ | 25.1M/170M [04:05<16:11, 150kB/s]
15%|█▍ | 25.1M/170M [04:05<16:38, 146kB/s]
15%|█▍ | 25.1M/170M [04:05<16:45, 145kB/s]
15%|█▍ | 25.2M/170M [04:05<15:45, 154kB/s]
15%|█▍ | 25.2M/170M [04:06<17:01, 142kB/s]
15%|█▍ | 25.2M/170M [04:06<15:17, 158kB/s]
15%|█▍ | 25.3M/170M [04:06<17:03, 142kB/s]
15%|█▍ | 25.3M/170M [04:06<16:47, 144kB/s]
15%|█▍ | 25.3M/170M [04:07<16:15, 149kB/s]
15%|█▍ | 25.4M/170M [04:07<15:49, 153kB/s]
15%|█▍ | 25.4M/170M [04:07<16:40, 145kB/s]
15%|█▍ | 25.4M/170M [04:07<15:15, 158kB/s]
15%|█▍ | 25.5M/170M [04:07<15:41, 154kB/s]
15%|█▍ | 25.5M/170M [04:08<15:01, 161kB/s]
15%|█▍ | 25.5M/170M [04:08<15:50, 153kB/s]
15%|█▍ | 25.6M/170M [04:08<15:02, 161kB/s]
15%|█▌ | 25.6M/170M [04:08<15:41, 154kB/s]
15%|█▌ | 25.6M/170M [04:08<17:05, 141kB/s]
15%|█▌ | 25.7M/170M [04:09<18:00, 134kB/s]
15%|█▌ | 25.7M/170M [04:09<17:27, 138kB/s]
15%|█▌ | 25.7M/170M [04:09<17:12, 140kB/s]
15%|█▌ | 25.8M/170M [04:09<16:33, 146kB/s]
15%|█▌ | 25.8M/170M [04:10<16:13, 149kB/s]
15%|█▌ | 25.8M/170M [04:10<16:11, 149kB/s]
15%|█▌ | 25.9M/170M [04:10<15:49, 152kB/s]
15%|█▌ | 25.9M/170M [04:10<16:48, 143kB/s]
15%|█▌ | 25.9M/170M [04:11<16:40, 144kB/s]
15%|█▌ | 26.0M/170M [04:11<17:40, 136kB/s]
15%|█▌ | 26.0M/170M [04:11<16:57, 142kB/s]
15%|█▌ | 26.0M/170M [04:11<17:02, 141kB/s]
15%|█▌ | 26.1M/170M [04:11<16:12, 148kB/s]
15%|█▌ | 26.1M/170M [04:12<17:39, 136kB/s]
15%|█▌ | 26.1M/170M [04:12<16:00, 150kB/s]
15%|█▌ | 26.1M/170M [04:12<15:58, 151kB/s]
15%|█▌ | 26.2M/170M [04:12<16:29, 146kB/s]
15%|█▌ | 26.2M/170M [04:13<16:26, 146kB/s]
15%|█▌ | 26.2M/170M [04:13<16:20, 147kB/s]
15%|█▌ | 26.3M/170M [04:13<17:15, 139kB/s]
15%|█▌ | 26.3M/170M [04:13<17:04, 141kB/s]
15%|█▌ | 26.3M/170M [04:13<16:19, 147kB/s]
15%|█▌ | 26.4M/170M [04:14<16:50, 143kB/s]
15%|█▌ | 26.4M/170M [04:14<16:09, 149kB/s]
16%|█▌ | 26.4M/170M [04:14<17:43, 135kB/s]
16%|█▌ | 26.5M/170M [04:14<16:03, 149kB/s]
16%|█▌ | 26.5M/170M [04:15<15:55, 151kB/s]
16%|█▌ | 26.5M/170M [04:15<16:06, 149kB/s]
16%|█▌ | 26.6M/170M [04:15<16:00, 150kB/s]
16%|█▌ | 26.6M/170M [04:15<15:53, 151kB/s]
16%|█▌ | 26.6M/170M [04:16<16:49, 142kB/s]
16%|█▌ | 26.7M/170M [04:16<16:38, 144kB/s]
16%|█▌ | 26.7M/170M [04:16<16:19, 147kB/s]
16%|█▌ | 26.7M/170M [04:16<16:29, 145kB/s]
16%|█▌ | 26.8M/170M [04:16<16:51, 142kB/s]
16%|█▌ | 26.8M/170M [04:17<17:25, 137kB/s]
16%|█▌ | 26.8M/170M [04:17<17:22, 138kB/s]
16%|█▌ | 26.9M/170M [04:17<16:21, 146kB/s]
16%|█▌ | 26.9M/170M [04:17<17:03, 140kB/s]
16%|█▌ | 26.9M/170M [04:18<17:08, 140kB/s]
16%|█▌ | 27.0M/170M [04:18<18:01, 133kB/s]
16%|█▌ | 27.0M/170M [04:18<17:22, 138kB/s]
16%|█▌ | 27.0M/170M [04:18<17:11, 139kB/s]
16%|█▌ | 27.1M/170M [04:19<16:26, 145kB/s]
16%|█▌ | 27.1M/170M [04:19<15:15, 157kB/s]
16%|█▌ | 27.1M/170M [04:19<17:48, 134kB/s]
16%|█▌ | 27.2M/170M [04:19<17:03, 140kB/s]
16%|█▌ | 27.2M/170M [04:19<16:45, 143kB/s]
16%|█▌ | 27.2M/170M [04:20<15:46, 151kB/s]
16%|█▌ | 27.3M/170M [04:20<15:46, 151kB/s]
16%|█▌ | 27.3M/170M [04:20<15:24, 155kB/s]
16%|█▌ | 27.3M/170M [04:20<19:51, 120kB/s]
16%|█▌ | 27.4M/170M [04:22<39:17, 60.7kB/s]
16%|█▌ | 27.4M/170M [04:22<36:01, 66.2kB/s]
16%|█▌ | 27.4M/170M [04:23<43:38, 54.6kB/s]
16%|█▌ | 27.5M/170M [04:23<38:17, 62.3kB/s]
16%|█▌ | 27.5M/170M [04:24<42:23, 56.2kB/s]
16%|█▌ | 27.5M/170M [04:24<38:58, 61.2kB/s]
16%|█▌ | 27.6M/170M [04:25<35:14, 67.6kB/s]
16%|█▌ | 27.6M/170M [04:25<31:29, 75.6kB/s]
16%|█▌ | 27.6M/170M [04:25<28:38, 83.2kB/s]
16%|█▌ | 27.7M/170M [04:26<40:30, 58.8kB/s]
16%|█▌ | 27.7M/170M [04:27<39:56, 59.6kB/s]
16%|█▋ | 27.7M/170M [04:27<37:22, 63.7kB/s]
16%|█▋ | 27.8M/170M [04:28<34:41, 68.6kB/s]
16%|█▋ | 27.8M/170M [04:28<32:20, 73.5kB/s]
16%|█▋ | 27.8M/170M [04:28<30:37, 77.7kB/s]
16%|█▋ | 27.9M/170M [04:29<38:52, 61.1kB/s]
16%|█▋ | 27.9M/170M [04:30<46:03, 51.6kB/s]
16%|█▋ | 27.9M/170M [04:31<50:46, 46.8kB/s]
16%|█▋ | 28.0M/170M [04:32<52:56, 44.9kB/s]
16%|█▋ | 28.0M/170M [04:32<46:28, 51.1kB/s]
16%|█▋ | 28.0M/170M [04:33<45:28, 52.2kB/s]
16%|█▋ | 28.0M/170M [04:33<46:04, 51.5kB/s]
16%|█▋ | 28.1M/170M [04:34<48:21, 49.1kB/s]
16%|█▋ | 28.1M/170M [04:35<48:28, 49.0kB/s]
17%|█▋ | 28.1M/170M [04:36<53:16, 44.5kB/s]
17%|█▋ | 28.2M/170M [04:36<53:38, 44.2kB/s]
17%|█▋ | 28.2M/170M [04:37<46:47, 50.7kB/s]
17%|█▋ | 28.2M/170M [04:37<42:31, 55.8kB/s]
17%|█▋ | 28.3M/170M [04:38<39:13, 60.4kB/s]
17%|█▋ | 28.3M/170M [04:38<32:08, 73.7kB/s]
17%|█▋ | 28.3M/170M [04:38<28:15, 83.9kB/s]
17%|█▋ | 28.4M/170M [04:38<24:26, 96.9kB/s]
17%|█▋ | 28.4M/170M [04:39<22:23, 106kB/s]
17%|█▋ | 28.4M/170M [04:39<20:17, 117kB/s]
17%|█▋ | 28.5M/170M [04:39<19:00, 124kB/s]
17%|█▋ | 28.5M/170M [04:39<19:24, 122kB/s]
17%|█▋ | 28.5M/170M [04:40<18:37, 127kB/s]
17%|█▋ | 28.6M/170M [04:40<18:27, 128kB/s]
17%|█▋ | 28.6M/170M [04:40<16:38, 142kB/s]
17%|█▋ | 28.6M/170M [04:40<16:56, 140kB/s]
17%|█▋ | 28.7M/170M [04:41<16:40, 142kB/s]
17%|█▋ | 28.7M/170M [04:41<16:51, 140kB/s]
17%|█▋ | 28.7M/170M [04:41<16:53, 140kB/s]
17%|█▋ | 28.8M/170M [04:41<16:03, 147kB/s]
17%|█▋ | 28.8M/170M [04:41<16:32, 143kB/s]
17%|█▋ | 28.8M/170M [04:42<15:28, 153kB/s]
17%|█▋ | 28.9M/170M [04:42<16:38, 142kB/s]
17%|█▋ | 28.9M/170M [04:42<16:18, 145kB/s]
17%|█▋ | 28.9M/170M [04:42<17:55, 132kB/s]
17%|█▋ | 29.0M/170M [04:43<17:53, 132kB/s]
17%|█▋ | 29.0M/170M [04:43<16:47, 141kB/s]
17%|█▋ | 29.0M/170M [04:43<17:47, 132kB/s]
17%|█▋ | 29.1M/170M [04:43<18:37, 127kB/s]
17%|█▋ | 29.1M/170M [04:44<18:04, 130kB/s]
17%|█▋ | 29.1M/170M [04:44<16:55, 139kB/s]
17%|█▋ | 29.2M/170M [04:44<23:05, 102kB/s]
17%|█▋ | 29.2M/170M [04:45<22:33, 104kB/s]
17%|█▋ | 29.2M/170M [04:45<25:37, 91.9kB/s]
17%|█▋ | 29.3M/170M [04:46<26:15, 89.7kB/s]
17%|█▋ | 29.3M/170M [04:46<24:26, 96.3kB/s]
17%|█▋ | 29.3M/170M [04:46<23:00, 102kB/s]
17%|█▋ | 29.4M/170M [04:46<24:02, 97.9kB/s]
17%|█▋ | 29.4M/170M [04:47<22:14, 106kB/s]
17%|█▋ | 29.4M/170M [04:47<20:03, 117kB/s]
17%|█▋ | 29.5M/170M [04:47<20:35, 114kB/s]
17%|█▋ | 29.5M/170M [04:47<20:21, 115kB/s]
17%|█▋ | 29.5M/170M [04:48<21:57, 107kB/s]
17%|█▋ | 29.6M/170M [04:49<29:59, 78.3kB/s]
17%|█▋ | 29.6M/170M [04:49<31:33, 74.4kB/s]
17%|█▋ | 29.6M/170M [04:50<37:26, 62.7kB/s]
17%|█▋ | 29.7M/170M [04:50<34:51, 67.3kB/s]
17%|█▋ | 29.7M/170M [04:50<32:01, 73.3kB/s]
17%|█▋ | 29.7M/170M [04:51<32:58, 71.2kB/s]
17%|█▋ | 29.8M/170M [04:51<31:25, 74.7kB/s]
17%|█▋ | 29.8M/170M [04:52<27:55, 84.0kB/s]
17%|█▋ | 29.8M/170M [04:52<25:16, 92.7kB/s]
18%|█▊ | 29.9M/170M [04:52<24:02, 97.5kB/s]
18%|█▊ | 29.9M/170M [04:53<23:33, 99.5kB/s]
18%|█▊ | 29.9M/170M [04:53<22:53, 102kB/s]
18%|█▊ | 29.9M/170M [04:53<24:13, 96.7kB/s]
18%|█▊ | 30.0M/170M [04:53<21:32, 109kB/s]
18%|█▊ | 30.0M/170M [04:54<19:48, 118kB/s]
18%|█▊ | 30.0M/170M [04:54<21:06, 111kB/s]
18%|█▊ | 30.1M/170M [04:54<19:52, 118kB/s]
18%|█▊ | 30.1M/170M [04:55<20:30, 114kB/s]
18%|█▊ | 30.1M/170M [04:55<20:21, 115kB/s]
18%|█▊ | 30.2M/170M [04:55<20:13, 116kB/s]
18%|█▊ | 30.2M/170M [04:55<18:58, 123kB/s]
18%|█▊ | 30.2M/170M [04:56<20:15, 115kB/s]
18%|█▊ | 30.3M/170M [04:56<19:24, 120kB/s]
18%|█▊ | 30.3M/170M [04:56<18:57, 123kB/s]
18%|█▊ | 30.3M/170M [04:56<18:46, 124kB/s]
18%|█▊ | 30.4M/170M [04:57<21:48, 107kB/s]
18%|█▊ | 30.4M/170M [04:57<22:24, 104kB/s]
18%|█▊ | 30.4M/170M [04:57<21:45, 107kB/s]
18%|█▊ | 30.5M/170M [04:58<21:07, 110kB/s]
18%|█▊ | 30.5M/170M [04:58<21:24, 109kB/s]
18%|█▊ | 30.5M/170M [04:58<21:58, 106kB/s]
18%|█▊ | 30.6M/170M [04:59<22:48, 102kB/s]
18%|█▊ | 30.6M/170M [04:59<20:18, 115kB/s]
18%|█▊ | 30.6M/170M [04:59<21:52, 107kB/s]
18%|█▊ | 30.7M/170M [05:00<23:29, 99.2kB/s]
18%|█▊ | 30.7M/170M [05:00<22:03, 106kB/s]
18%|█▊ | 30.7M/170M [05:00<21:59, 106kB/s]
18%|█▊ | 30.8M/170M [05:00<21:34, 108kB/s]
18%|█▊ | 30.8M/170M [05:01<20:51, 112kB/s]
18%|█▊ | 30.8M/170M [05:01<22:05, 105kB/s]
18%|█▊ | 30.9M/170M [05:02<42:14, 55.1kB/s]
18%|█▊ | 30.9M/170M [05:03<42:45, 54.4kB/s]
18%|█▊ | 30.9M/170M [05:03<38:13, 60.9kB/s]
18%|█▊ | 31.0M/170M [05:04<38:19, 60.7kB/s]
18%|█▊ | 31.0M/170M [05:04<35:52, 64.8kB/s]
18%|█▊ | 31.0M/170M [05:05<32:20, 71.9kB/s]
18%|█▊ | 31.1M/170M [05:05<32:29, 71.5kB/s]
18%|█▊ | 31.1M/170M [05:05<29:48, 77.9kB/s]
18%|█▊ | 31.1M/170M [05:06<31:31, 73.7kB/s]
18%|█▊ | 31.2M/170M [05:06<28:33, 81.3kB/s]
18%|█▊ | 31.2M/170M [05:07<26:03, 89.1kB/s]
18%|█▊ | 31.2M/170M [05:07<24:41, 94.0kB/s]
18%|█▊ | 31.3M/170M [05:07<24:01, 96.6kB/s]
18%|█▊ | 31.3M/170M [05:08<24:16, 95.6kB/s]
18%|█▊ | 31.3M/170M [05:08<26:19, 88.1kB/s]
18%|█▊ | 31.4M/170M [05:08<24:25, 94.9kB/s]
18%|█▊ | 31.4M/170M [05:09<25:53, 89.5kB/s]
18%|█▊ | 31.4M/170M [05:09<27:46, 83.5kB/s]
18%|█▊ | 31.5M/170M [05:10<27:40, 83.7kB/s]
18%|█▊ | 31.5M/170M [05:10<25:51, 89.6kB/s]
18%|█▊ | 31.5M/170M [05:10<25:44, 90.0kB/s]
19%|█▊ | 31.6M/170M [05:11<34:18, 67.5kB/s]
19%|█▊ | 31.6M/170M [05:11<30:22, 76.2kB/s]
19%|█▊ | 31.6M/170M [05:12<34:32, 67.0kB/s]
19%|█▊ | 31.7M/170M [05:12<32:47, 70.6kB/s]
19%|█▊ | 31.7M/170M [05:13<30:05, 76.9kB/s]
19%|█▊ | 31.7M/170M [05:13<26:11, 88.3kB/s]
19%|█▊ | 31.8M/170M [05:14<33:40, 68.7kB/s]
19%|█▊ | 31.8M/170M [05:14<36:04, 64.1kB/s]
19%|█▊ | 31.8M/170M [05:15<46:09, 50.1kB/s]
19%|█▊ | 31.9M/170M [05:16<49:13, 46.9kB/s]
19%|█▊ | 31.9M/170M [05:17<49:42, 46.5kB/s]
19%|█▊ | 31.9M/170M [05:17<45:58, 50.2kB/s]
19%|█▊ | 31.9M/170M [05:18<44:32, 51.8kB/s]
19%|█▉ | 32.0M/170M [05:18<45:17, 51.0kB/s]
19%|█▉ | 32.0M/170M [05:19<38:13, 60.4kB/s]
19%|█▉ | 32.0M/170M [05:19<40:17, 57.3kB/s]
19%|█▉ | 32.1M/170M [05:20<36:20, 63.5kB/s]
19%|█▉ | 32.1M/170M [05:20<33:38, 68.5kB/s]
19%|█▉ | 32.1M/170M [05:20<29:38, 77.8kB/s]
19%|█▉ | 32.2M/170M [05:21<25:01, 92.1kB/s]
19%|█▉ | 32.2M/170M [05:21<25:07, 91.7kB/s]
19%|█▉ | 32.2M/170M [05:21<22:32, 102kB/s]
19%|█▉ | 32.3M/170M [05:22<22:57, 100kB/s]
19%|█▉ | 32.3M/170M [05:22<24:04, 95.6kB/s]
19%|█▉ | 32.3M/170M [05:22<22:18, 103kB/s]
19%|█▉ | 32.4M/170M [05:23<21:32, 107kB/s]
19%|█▉ | 32.4M/170M [05:23<22:13, 104kB/s]
19%|█▉ | 32.4M/170M [05:23<22:35, 102kB/s]
19%|█▉ | 32.5M/170M [05:23<21:48, 105kB/s]
19%|█▉ | 32.5M/170M [05:24<21:38, 106kB/s]
19%|█▉ | 32.5M/170M [05:24<20:40, 111kB/s]
19%|█▉ | 32.6M/170M [05:24<20:26, 112kB/s]
19%|█▉ | 32.6M/170M [05:25<18:50, 122kB/s]
19%|█▉ | 32.6M/170M [05:25<19:36, 117kB/s]
19%|█▉ | 32.7M/170M [05:25<18:31, 124kB/s]
19%|█▉ | 32.7M/170M [05:25<19:42, 117kB/s]
19%|█▉ | 32.7M/170M [05:26<19:14, 119kB/s]
19%|█▉ | 32.8M/170M [05:26<21:03, 109kB/s]
19%|█▉ | 32.8M/170M [05:26<20:59, 109kB/s]
19%|█▉ | 32.8M/170M [05:27<21:28, 107kB/s]
19%|█▉ | 32.9M/170M [05:27<22:09, 104kB/s]
19%|█▉ | 32.9M/170M [05:27<21:54, 105kB/s]
19%|█▉ | 32.9M/170M [05:28<22:43, 101kB/s]
19%|█▉ | 33.0M/170M [05:28<23:07, 99.2kB/s]
19%|█▉ | 33.0M/170M [05:28<22:52, 100kB/s]
19%|█▉ | 33.0M/170M [05:29<24:36, 93.1kB/s]
19%|█▉ | 33.1M/170M [05:29<25:07, 91.2kB/s]
19%|█▉ | 33.1M/170M [05:29<25:00, 91.6kB/s]
19%|█▉ | 33.1M/170M [05:30<25:58, 88.2kB/s]
19%|█▉ | 33.2M/170M [05:30<24:59, 91.6kB/s]
19%|█▉ | 33.2M/170M [05:30<23:52, 95.8kB/s]
19%|█▉ | 33.2M/170M [05:31<22:22, 102kB/s]
20%|█▉ | 33.3M/170M [05:31<22:34, 101kB/s]
20%|█▉ | 33.3M/170M [05:31<21:41, 105kB/s]
20%|█▉ | 33.3M/170M [05:32<20:09, 113kB/s]
20%|█▉ | 33.4M/170M [05:32<21:58, 104kB/s]
20%|█▉ | 33.4M/170M [05:32<21:13, 108kB/s]
20%|█▉ | 33.4M/170M [05:32<19:17, 118kB/s]
20%|█▉ | 33.5M/170M [05:33<24:03, 94.9kB/s]
20%|█▉ | 33.5M/170M [05:33<21:56, 104kB/s]
20%|█▉ | 33.5M/170M [05:34<23:24, 97.5kB/s]
20%|█▉ | 33.6M/170M [05:34<22:25, 102kB/s]
20%|█▉ | 33.6M/170M [05:34<25:05, 90.9kB/s]
20%|█▉ | 33.6M/170M [05:35<24:07, 94.5kB/s]
20%|█▉ | 33.7M/170M [05:35<32:43, 69.7kB/s]
20%|█▉ | 33.7M/170M [05:36<30:30, 74.8kB/s]
20%|█▉ | 33.7M/170M [05:37<37:20, 61.0kB/s]
20%|█▉ | 33.8M/170M [05:37<45:04, 50.6kB/s]
20%|█▉ | 33.8M/170M [05:38<39:13, 58.1kB/s]
20%|█▉ | 33.8M/170M [05:38<33:55, 67.1kB/s]
20%|█▉ | 33.8M/170M [05:39<31:11, 73.0kB/s]
20%|█▉ | 33.9M/170M [05:39<27:37, 82.4kB/s]
20%|█▉ | 33.9M/170M [05:39<26:54, 84.6kB/s]
20%|█▉ | 33.9M/170M [05:39<25:16, 90.1kB/s]
20%|█▉ | 34.0M/170M [05:40<23:21, 97.4kB/s]
20%|█▉ | 34.0M/170M [05:40<22:59, 98.9kB/s]
20%|█▉ | 34.0M/170M [05:40<22:10, 103kB/s]
20%|█▉ | 34.1M/170M [05:41<21:31, 106kB/s]
20%|██ | 34.1M/170M [05:41<21:14, 107kB/s]
20%|██ | 34.1M/170M [05:41<22:08, 103kB/s]
20%|██ | 34.2M/170M [05:42<23:55, 94.9kB/s]
20%|██ | 34.2M/170M [05:42<32:45, 69.3kB/s]
20%|██ | 34.2M/170M [05:43<36:25, 62.3kB/s]
20%|██ | 34.3M/170M [05:44<35:23, 64.2kB/s]
20%|██ | 34.3M/170M [05:44<31:32, 71.9kB/s]
20%|██ | 34.3M/170M [05:44<29:18, 77.4kB/s]
20%|██ | 34.4M/170M [05:45<26:21, 86.1kB/s]
20%|██ | 34.4M/170M [05:45<25:33, 88.8kB/s]
20%|██ | 34.4M/170M [05:45<24:32, 92.4kB/s]
20%|██ | 34.5M/170M [05:46<28:45, 78.9kB/s]
20%|██ | 34.5M/170M [05:46<27:14, 83.2kB/s]
20%|██ | 34.5M/170M [05:46<24:22, 92.9kB/s]
20%|██ | 34.6M/170M [05:47<23:10, 97.8kB/s]
20%|██ | 34.6M/170M [05:47<24:18, 93.2kB/s]
20%|██ | 34.6M/170M [05:47<22:30, 101kB/s]
20%|██ | 34.7M/170M [05:48<21:58, 103kB/s]
20%|██ | 34.7M/170M [05:48<24:53, 90.9kB/s]
20%|██ | 34.7M/170M [05:48<26:33, 85.2kB/s]
20%|██ | 34.8M/170M [05:49<25:03, 90.3kB/s]
20%|██ | 34.8M/170M [05:49<23:53, 94.7kB/s]
20%|██ | 34.8M/170M [05:50<25:34, 88.4kB/s]
20%|██ | 34.9M/170M [05:50<25:15, 89.5kB/s]
20%|██ | 34.9M/170M [05:50<23:23, 96.6kB/s]
20%|██ | 34.9M/170M [05:50<22:17, 101kB/s]
21%|██ | 35.0M/170M [05:51<21:39, 104kB/s]
21%|██ | 35.0M/170M [05:51<21:48, 104kB/s]
21%|██ | 35.0M/170M [05:51<22:22, 101kB/s]
21%|██ | 35.1M/170M [05:52<28:51, 78.2kB/s]
21%|██ | 35.1M/170M [05:52<24:43, 91.2kB/s]
21%|██ | 35.1M/170M [05:52<21:40, 104kB/s]
21%|██ | 35.2M/170M [05:53<21:42, 104kB/s]
21%|██ | 35.2M/170M [05:53<29:11, 77.3kB/s]
21%|██ | 35.2M/170M [05:55<42:33, 53.0kB/s]
21%|██ | 35.3M/170M [05:55<48:48, 46.2kB/s]
21%|██ | 35.3M/170M [05:56<43:26, 51.9kB/s]
21%|██ | 35.3M/170M [05:57<44:29, 50.6kB/s]
21%|██ | 35.4M/170M [05:57<40:33, 55.5kB/s]
21%|██ | 35.4M/170M [05:57<36:35, 61.6kB/s]
21%|██ | 35.4M/170M [05:58<32:39, 68.9kB/s]
21%|██ | 35.5M/170M [05:58<31:48, 70.8kB/s]
21%|██ | 35.5M/170M [05:59<30:13, 74.4kB/s]
21%|██ | 35.5M/170M [05:59<31:57, 70.4kB/s]
21%|██ | 35.6M/170M [05:59<28:22, 79.3kB/s]
21%|██ | 35.6M/170M [06:00<28:40, 78.4kB/s]
21%|██ | 35.6M/170M [06:00<25:54, 86.7kB/s]
21%|██ | 35.7M/170M [06:00<24:25, 92.0kB/s]
21%|██ | 35.7M/170M [06:01<26:21, 85.3kB/s]
21%|██ | 35.7M/170M [06:02<30:33, 73.5kB/s]
21%|██ | 35.7M/170M [06:02<33:03, 67.9kB/s]
21%|██ | 35.8M/170M [06:02<31:22, 71.6kB/s]
21%|██ | 35.8M/170M [06:03<32:02, 70.1kB/s]
21%|██ | 35.8M/170M [06:03<32:45, 68.5kB/s]
21%|██ | 35.9M/170M [06:04<29:00, 77.4kB/s]
21%|██ | 35.9M/170M [06:04<26:06, 85.9kB/s]
21%|██ | 35.9M/170M [06:04<24:16, 92.4kB/s]
21%|██ | 36.0M/170M [06:05<21:53, 102kB/s]
21%|██ | 36.0M/170M [06:05<22:48, 98.3kB/s]
21%|██ | 36.0M/170M [06:05<23:39, 94.7kB/s]
21%|██ | 36.1M/170M [06:06<23:15, 96.3kB/s]
21%|██ | 36.1M/170M [06:06<22:54, 97.8kB/s]
21%|██ | 36.1M/170M [06:06<24:13, 92.5kB/s]
21%|██ | 36.2M/170M [06:07<24:14, 92.3kB/s]
21%|██ | 36.2M/170M [06:07<26:11, 85.4kB/s]
21%|██▏ | 36.2M/170M [06:07<22:57, 97.5kB/s]
21%|██▏ | 36.3M/170M [06:08<22:53, 97.7kB/s]
21%|██▏ | 36.3M/170M [06:08<22:36, 98.9kB/s]
21%|██▏ | 36.3M/170M [06:08<22:11, 101kB/s]
21%|██▏ | 36.4M/170M [06:09<20:18, 110kB/s]
21%|██▏ | 36.4M/170M [06:09<20:49, 107kB/s]
21%|██▏ | 36.4M/170M [06:09<21:49, 102kB/s]
21%|██▏ | 36.5M/170M [06:10<22:39, 98.6kB/s]
21%|██▏ | 36.5M/170M [06:10<21:27, 104kB/s]
21%|██▏ | 36.5M/170M [06:10<21:37, 103kB/s]
21%|██▏ | 36.6M/170M [06:10<19:56, 112kB/s]
21%|██▏ | 36.6M/170M [06:11<19:45, 113kB/s]
21%|██▏ | 36.6M/170M [06:11<19:25, 115kB/s]
22%|██▏ | 36.7M/170M [06:11<18:43, 119kB/s]
22%|██▏ | 36.7M/170M [06:12<18:58, 118kB/s]
22%|██▏ | 36.7M/170M [06:12<18:59, 117kB/s]
22%|██▏ | 36.8M/170M [06:12<20:05, 111kB/s]
22%|██▏ | 36.8M/170M [06:13<22:21, 99.7kB/s]
22%|██▏ | 36.8M/170M [06:13<22:09, 101kB/s]
22%|██▏ | 36.9M/170M [06:13<24:28, 91.0kB/s]
22%|██▏ | 36.9M/170M [06:14<22:52, 97.4kB/s]
22%|██▏ | 36.9M/170M [06:14<24:24, 91.2kB/s]
22%|██▏ | 37.0M/170M [06:14<24:49, 89.7kB/s]
22%|██▏ | 37.0M/170M [06:15<24:52, 89.4kB/s]
22%|██▏ | 37.0M/170M [06:15<24:27, 90.9kB/s]
22%|██▏ | 37.1M/170M [06:15<23:06, 96.3kB/s]
22%|██▏ | 37.1M/170M [06:16<21:55, 101kB/s]
22%|██▏ | 37.1M/170M [06:16<18:32, 120kB/s]
22%|██▏ | 37.2M/170M [06:16<18:07, 123kB/s]
22%|██▏ | 37.2M/170M [06:16<16:52, 132kB/s]
22%|██▏ | 37.2M/170M [06:17<18:10, 122kB/s]
22%|██▏ | 37.3M/170M [06:17<17:19, 128kB/s]
22%|██▏ | 37.3M/170M [06:17<17:12, 129kB/s]
22%|██▏ | 37.3M/170M [06:17<18:29, 120kB/s]
22%|██▏ | 37.4M/170M [06:18<17:10, 129kB/s]
22%|██▏ | 37.4M/170M [06:18<17:06, 130kB/s]
22%|██▏ | 37.4M/170M [06:18<16:12, 137kB/s]
22%|██▏ | 37.5M/170M [06:18<15:35, 142kB/s]
22%|██▏ | 37.5M/170M [06:19<15:48, 140kB/s]
22%|██▏ | 37.5M/170M [06:19<15:50, 140kB/s]
22%|██▏ | 37.6M/170M [06:19<17:57, 123kB/s]
22%|██▏ | 37.6M/170M [06:19<16:44, 132kB/s]
22%|██▏ | 37.6M/170M [06:20<16:56, 131kB/s]
22%|██▏ | 37.7M/170M [06:20<18:49, 118kB/s]
22%|██▏ | 37.7M/170M [06:20<18:11, 122kB/s]
22%|██▏ | 37.7M/170M [06:20<17:28, 127kB/s]
22%|██▏ | 37.7M/170M [06:21<17:40, 125kB/s]
22%|██▏ | 37.8M/170M [06:21<17:51, 124kB/s]
22%|██▏ | 37.8M/170M [06:21<17:23, 127kB/s]
22%|██▏ | 37.8M/170M [06:21<17:32, 126kB/s]
22%|██▏ | 37.9M/170M [06:22<16:05, 137kB/s]
22%|██▏ | 37.9M/170M [06:22<17:35, 126kB/s]
22%|██▏ | 37.9M/170M [06:22<16:42, 132kB/s]
22%|██▏ | 38.0M/170M [06:23<18:35, 119kB/s]
22%|██▏ | 38.0M/170M [06:23<17:23, 127kB/s]
22%|██▏ | 38.0M/170M [06:23<18:42, 118kB/s]
22%|██▏ | 38.1M/170M [06:23<17:14, 128kB/s]
22%|██▏ | 38.1M/170M [06:23<16:25, 134kB/s]
22%|██▏ | 38.1M/170M [06:24<16:47, 131kB/s]
22%|██▏ | 38.2M/170M [06:24<15:36, 141kB/s]
22%|██▏ | 38.2M/170M [06:24<16:36, 133kB/s]
22%|██▏ | 38.2M/170M [06:25<17:58, 123kB/s]
22%|██▏ | 38.3M/170M [06:25<20:20, 108kB/s]
22%|██▏ | 38.3M/170M [06:25<19:16, 114kB/s]
22%|██▏ | 38.3M/170M [06:25<19:22, 114kB/s]
23%|██▎ | 38.4M/170M [06:26<20:04, 110kB/s]
23%|██▎ | 38.4M/170M [06:26<20:16, 109kB/s]
23%|██▎ | 38.4M/170M [06:27<23:58, 91.8kB/s]
23%|██▎ | 38.5M/170M [06:27<21:19, 103kB/s]
23%|██▎ | 38.5M/170M [06:27<19:30, 113kB/s]
23%|██▎ | 38.5M/170M [06:27<19:45, 111kB/s]
23%|██▎ | 38.6M/170M [06:28<24:25, 90.0kB/s]
23%|██▎ | 38.6M/170M [06:28<22:14, 98.8kB/s]
23%|██▎ | 38.6M/170M [06:29<29:05, 75.6kB/s]
23%|██▎ | 38.7M/170M [06:29<33:42, 65.2kB/s]
23%|██▎ | 38.7M/170M [06:30<34:49, 63.1kB/s]
23%|██▎ | 38.7M/170M [06:30<32:52, 66.8kB/s]
23%|██▎ | 38.8M/170M [06:31<33:57, 64.6kB/s]
23%|██▎ | 38.8M/170M [06:32<42:40, 51.4kB/s]
23%|██▎ | 38.8M/170M [06:33<49:26, 44.4kB/s]
23%|██▎ | 38.9M/170M [06:33<45:44, 48.0kB/s]
23%|██▎ | 38.9M/170M [06:34<49:12, 44.6kB/s]
23%|██▎ | 38.9M/170M [06:35<44:41, 49.1kB/s]
23%|██▎ | 39.0M/170M [06:35<36:36, 59.9kB/s]
23%|██▎ | 39.0M/170M [06:36<34:19, 63.9kB/s]
23%|██▎ | 39.0M/170M [06:36<31:17, 70.0kB/s]
23%|██▎ | 39.1M/170M [06:36<27:42, 79.1kB/s]
23%|██▎ | 39.1M/170M [06:36<25:51, 84.7kB/s]
23%|██▎ | 39.1M/170M [06:37<25:29, 85.9kB/s]
23%|██▎ | 39.2M/170M [06:37<25:46, 84.9kB/s]
23%|██▎ | 39.2M/170M [06:38<25:49, 84.7kB/s]
23%|██▎ | 39.2M/170M [06:38<24:55, 87.8kB/s]
23%|██▎ | 39.3M/170M [06:38<26:19, 83.1kB/s]
23%|██▎ | 39.3M/170M [06:39<24:42, 88.5kB/s]
23%|██▎ | 39.3M/170M [06:39<26:13, 83.4kB/s]
23%|██▎ | 39.4M/170M [06:39<24:06, 90.6kB/s]
23%|██▎ | 39.4M/170M [06:40<24:47, 88.2kB/s]
23%|██▎ | 39.4M/170M [06:40<27:25, 79.6kB/s]
23%|██▎ | 39.5M/170M [06:41<26:00, 84.0kB/s]
23%|██▎ | 39.5M/170M [06:41<23:51, 91.5kB/s]
23%|██▎ | 39.5M/170M [06:41<22:03, 99.0kB/s]
23%|██▎ | 39.6M/170M [06:42<21:02, 104kB/s]
23%|██▎ | 39.6M/170M [06:42<21:36, 101kB/s]
23%|██▎ | 39.6M/170M [06:42<21:48, 100kB/s]
23%|██▎ | 39.6M/170M [06:43<22:10, 98.3kB/s]
23%|██▎ | 39.7M/170M [06:43<23:05, 94.4kB/s]
23%|██▎ | 39.7M/170M [06:43<23:14, 93.8kB/s]
23%|██▎ | 39.7M/170M [06:44<21:06, 103kB/s]
23%|██▎ | 39.8M/170M [06:44<20:37, 106kB/s]
23%|██▎ | 39.8M/170M [06:44<20:54, 104kB/s]
23%|██▎ | 39.8M/170M [06:44<21:03, 103kB/s]
23%|██▎ | 39.9M/170M [06:45<22:05, 98.6kB/s]
23%|██▎ | 39.9M/170M [06:45<21:09, 103kB/s]
23%|██▎ | 39.9M/170M [06:46<23:33, 92.4kB/s]
23%|██▎ | 40.0M/170M [06:46<23:30, 92.5kB/s]
23%|██▎ | 40.0M/170M [06:46<23:05, 94.2kB/s]
23%|██▎ | 40.0M/170M [06:47<22:14, 97.7kB/s]
24%|██▎ | 40.1M/170M [06:47<20:04, 108kB/s]
24%|██▎ | 40.1M/170M [06:47<20:38, 105kB/s]
24%|██▎ | 40.1M/170M [06:47<19:43, 110kB/s]
24%|██▎ | 40.2M/170M [06:48<20:25, 106kB/s]
24%|██▎ | 40.2M/170M [06:48<19:33, 111kB/s]
24%|██▎ | 40.2M/170M [06:48<18:34, 117kB/s]
24%|██▎ | 40.3M/170M [06:49<19:56, 109kB/s]
24%|██▎ | 40.3M/170M [06:49<21:08, 103kB/s]
24%|██▎ | 40.3M/170M [06:49<19:53, 109kB/s]
24%|██▎ | 40.4M/170M [06:49<19:30, 111kB/s]
24%|██▎ | 40.4M/170M [06:50<20:50, 104kB/s]
24%|██▎ | 40.4M/170M [06:50<20:29, 106kB/s]
24%|██▎ | 40.5M/170M [06:50<21:11, 102kB/s]
24%|██▍ | 40.5M/170M [06:51<20:52, 104kB/s]
24%|██▍ | 40.5M/170M [06:51<19:22, 112kB/s]
24%|██▍ | 40.6M/170M [06:51<19:50, 109kB/s]
24%|██▍ | 40.6M/170M [06:52<19:50, 109kB/s]
24%|██▍ | 40.6M/170M [06:52<21:01, 103kB/s]
24%|██▍ | 40.7M/170M [06:52<19:57, 108kB/s]
24%|██▍ | 40.7M/170M [06:53<19:35, 110kB/s]
24%|██▍ | 40.7M/170M [06:53<20:37, 105kB/s]
24%|██▍ | 40.8M/170M [06:53<19:34, 110kB/s]
24%|██▍ | 40.8M/170M [06:53<19:32, 111kB/s]
24%|██▍ | 40.8M/170M [06:54<22:23, 96.5kB/s]
24%|██▍ | 40.9M/170M [06:54<22:22, 96.6kB/s]
24%|██▍ | 40.9M/170M [06:55<20:58, 103kB/s]
24%|██▍ | 40.9M/170M [06:55<19:56, 108kB/s]
24%|██▍ | 41.0M/170M [06:55<21:18, 101kB/s]
24%|██▍ | 41.0M/170M [06:55<19:51, 109kB/s]
24%|██▍ | 41.0M/170M [06:56<19:14, 112kB/s]
24%|██▍ | 41.1M/170M [06:56<18:42, 115kB/s]
24%|██▍ | 41.1M/170M [06:56<18:42, 115kB/s]
24%|██▍ | 41.1M/170M [06:57<18:26, 117kB/s]
24%|██▍ | 41.2M/170M [06:57<18:02, 120kB/s]
24%|██▍ | 41.2M/170M [06:57<18:27, 117kB/s]
24%|██▍ | 41.2M/170M [06:57<17:29, 123kB/s]
24%|██▍ | 41.3M/170M [06:58<16:23, 131kB/s]
24%|██▍ | 41.3M/170M [06:58<16:38, 129kB/s]
24%|██▍ | 41.3M/170M [06:58<17:44, 121kB/s]
24%|██▍ | 41.4M/170M [06:58<16:39, 129kB/s]
24%|██▍ | 41.4M/170M [06:59<16:24, 131kB/s]
24%|██▍ | 41.4M/170M [06:59<16:55, 127kB/s]
24%|██▍ | 41.5M/170M [06:59<16:44, 128kB/s]
24%|██▍ | 41.5M/170M [06:59<16:24, 131kB/s]
24%|██▍ | 41.5M/170M [07:00<16:33, 130kB/s]
24%|██▍ | 41.5M/170M [07:00<16:15, 132kB/s]
24%|██▍ | 41.6M/170M [07:00<15:46, 136kB/s]
24%|██▍ | 41.6M/170M [07:00<15:51, 135kB/s]
24%|██▍ | 41.6M/170M [07:01<17:36, 122kB/s]
24%|██▍ | 41.7M/170M [07:01<19:45, 109kB/s]
24%|██▍ | 41.7M/170M [07:01<18:42, 115kB/s]
24%|██▍ | 41.7M/170M [07:02<19:07, 112kB/s]
25%|██▍ | 41.8M/170M [07:02<18:43, 115kB/s]
25%|██▍ | 41.8M/170M [07:02<18:16, 117kB/s]
25%|██▍ | 41.8M/170M [07:02<18:24, 117kB/s]
25%|██▍ | 41.9M/170M [07:03<16:41, 128kB/s]
25%|██▍ | 41.9M/170M [07:03<16:41, 128kB/s]
25%|██▍ | 41.9M/170M [07:03<17:20, 123kB/s]
25%|██▍ | 42.0M/170M [07:03<17:25, 123kB/s]
25%|██▍ | 42.0M/170M [07:04<18:02, 119kB/s]
25%|██▍ | 42.0M/170M [07:04<17:24, 123kB/s]
25%|██▍ | 42.1M/170M [07:04<16:49, 127kB/s]
25%|██▍ | 42.1M/170M [07:04<16:08, 133kB/s]
25%|██▍ | 42.1M/170M [07:05<17:33, 122kB/s]
25%|██▍ | 42.2M/170M [07:05<16:02, 133kB/s]
25%|██▍ | 42.2M/170M [07:05<15:27, 138kB/s]
25%|██▍ | 42.2M/170M [07:05<15:18, 140kB/s]
25%|██▍ | 42.3M/170M [07:06<14:55, 143kB/s]
25%|██▍ | 42.3M/170M [07:06<14:56, 143kB/s]
25%|██▍ | 42.3M/170M [07:06<16:19, 131kB/s]
25%|██▍ | 42.4M/170M [07:06<15:27, 138kB/s]
25%|██▍ | 42.4M/170M [07:06<15:20, 139kB/s]
25%|██▍ | 42.4M/170M [07:07<16:49, 127kB/s]
25%|██▍ | 42.5M/170M [07:07<17:20, 123kB/s]
25%|██▍ | 42.5M/170M [07:07<17:55, 119kB/s]
25%|██▍ | 42.5M/170M [07:08<17:02, 125kB/s]
25%|██▍ | 42.6M/170M [07:08<17:19, 123kB/s]
25%|██▍ | 42.6M/170M [07:08<18:30, 115kB/s]
25%|██▌ | 42.6M/170M [07:09<18:28, 115kB/s]
25%|██▌ | 42.7M/170M [07:09<19:02, 112kB/s]
25%|██▌ | 42.7M/170M [07:09<18:22, 116kB/s]
25%|██▌ | 42.7M/170M [07:09<17:11, 124kB/s]
25%|██▌ | 42.8M/170M [07:10<17:55, 119kB/s]
25%|██▌ | 42.8M/170M [07:10<16:41, 128kB/s]
25%|██▌ | 42.8M/170M [07:10<17:32, 121kB/s]
25%|██▌ | 42.9M/170M [07:10<16:24, 130kB/s]
25%|██▌ | 42.9M/170M [07:11<17:01, 125kB/s]
25%|██▌ | 42.9M/170M [07:11<17:09, 124kB/s]
25%|██▌ | 43.0M/170M [07:11<18:45, 113kB/s]
25%|██▌ | 43.0M/170M [07:11<17:51, 119kB/s]
25%|██▌ | 43.0M/170M [07:12<19:55, 107kB/s]
25%|██▌ | 43.1M/170M [07:12<18:23, 116kB/s]
25%|██▌ | 43.1M/170M [07:12<18:22, 116kB/s]
25%|██▌ | 43.1M/170M [07:13<18:48, 113kB/s]
25%|██▌ | 43.2M/170M [07:13<19:05, 111kB/s]
25%|██▌ | 43.2M/170M [07:13<18:47, 113kB/s]
25%|██▌ | 43.2M/170M [07:14<19:03, 111kB/s]
25%|██▌ | 43.3M/170M [07:14<18:35, 114kB/s]
25%|██▌ | 43.3M/170M [07:14<20:38, 103kB/s]
25%|██▌ | 43.3M/170M [07:14<16:45, 127kB/s]
25%|██▌ | 43.4M/170M [07:15<17:44, 119kB/s]
25%|██▌ | 43.4M/170M [07:15<17:17, 123kB/s]
25%|██▌ | 43.4M/170M [07:15<16:15, 130kB/s]
25%|██▌ | 43.5M/170M [07:15<16:14, 130kB/s]
26%|██▌ | 43.5M/170M [07:16<17:03, 124kB/s]
26%|██▌ | 43.5M/170M [07:16<20:01, 106kB/s]
26%|██▌ | 43.5M/170M [07:16<19:21, 109kB/s]
26%|██▌ | 43.6M/170M [07:17<17:54, 118kB/s]
26%|██▌ | 43.6M/170M [07:17<17:24, 121kB/s]
26%|██▌ | 43.6M/170M [07:17<17:28, 121kB/s]
26%|██▌ | 43.7M/170M [07:17<16:44, 126kB/s]
26%|██▌ | 43.7M/170M [07:18<18:43, 113kB/s]
26%|██▌ | 43.7M/170M [07:18<17:45, 119kB/s]
26%|██▌ | 43.8M/170M [07:18<17:20, 122kB/s]
26%|██▌ | 43.8M/170M [07:18<17:46, 119kB/s]
26%|██▌ | 43.8M/170M [07:19<17:04, 124kB/s]
26%|██▌ | 43.9M/170M [07:19<16:36, 127kB/s]
26%|██▌ | 43.9M/170M [07:19<16:15, 130kB/s]
26%|██▌ | 43.9M/170M [07:19<15:04, 140kB/s]
26%|██▌ | 44.0M/170M [07:20<15:43, 134kB/s]
26%|██▌ | 44.0M/170M [07:20<15:00, 140kB/s]
26%|██▌ | 44.0M/170M [07:20<15:31, 136kB/s]
26%|██▌ | 44.1M/170M [07:20<16:18, 129kB/s]
26%|██▌ | 44.1M/170M [07:21<14:53, 141kB/s]
26%|██▌ | 44.1M/170M [07:21<14:54, 141kB/s]
26%|██▌ | 44.2M/170M [07:21<14:59, 141kB/s]
26%|██▌ | 44.2M/170M [07:21<15:37, 135kB/s]
26%|██▌ | 44.2M/170M [07:22<15:32, 135kB/s]
26%|██▌ | 44.3M/170M [07:22<16:38, 126kB/s]
26%|██▌ | 44.3M/170M [07:22<17:13, 122kB/s]
26%|██▌ | 44.3M/170M [07:22<16:29, 127kB/s]
26%|██▌ | 44.4M/170M [07:23<16:05, 131kB/s]
26%|██▌ | 44.4M/170M [07:23<17:47, 118kB/s]
26%|██▌ | 44.4M/170M [07:23<17:10, 122kB/s]
26%|██▌ | 44.5M/170M [07:23<16:25, 128kB/s]
26%|██▌ | 44.5M/170M [07:24<17:15, 122kB/s]
26%|██▌ | 44.5M/170M [07:24<16:33, 127kB/s]
26%|██▌ | 44.6M/170M [07:24<18:00, 117kB/s]
26%|██▌ | 44.6M/170M [07:25<17:10, 122kB/s]
26%|██▌ | 44.6M/170M [07:25<17:35, 119kB/s]
26%|██▌ | 44.7M/170M [07:25<17:54, 117kB/s]
26%|██▌ | 44.7M/170M [07:26<24:50, 84.4kB/s]
26%|██▌ | 44.7M/170M [07:26<26:33, 78.9kB/s]
26%|██▋ | 44.8M/170M [07:27<24:22, 86.0kB/s]
26%|██▋ | 44.8M/170M [07:27<25:22, 82.6kB/s]
26%|██▋ | 44.8M/170M [07:27<27:32, 76.0kB/s]
26%|██▋ | 44.9M/170M [07:28<26:45, 78.2kB/s]
26%|██▋ | 44.9M/170M [07:28<23:11, 90.3kB/s]
26%|██▋ | 44.9M/170M [07:29<25:04, 83.5kB/s]
26%|██▋ | 45.0M/170M [07:29<24:20, 86.0kB/s]
26%|██▋ | 45.0M/170M [07:30<28:57, 72.3kB/s]
26%|██▋ | 45.0M/170M [07:30<32:13, 64.9kB/s]
26%|██▋ | 45.1M/170M [07:30<27:27, 76.1kB/s]
26%|██▋ | 45.1M/170M [07:31<23:19, 89.6kB/s]
26%|██▋ | 45.1M/170M [07:31<20:02, 104kB/s]
26%|██▋ | 45.2M/170M [07:31<17:44, 118kB/s]
27%|██▋ | 45.2M/170M [07:31<17:24, 120kB/s]
27%|██▋ | 45.2M/170M [07:31<15:00, 139kB/s]
27%|██▋ | 45.3M/170M [07:32<15:58, 131kB/s]
27%|██▋ | 45.3M/170M [07:32<14:30, 144kB/s]
27%|██▋ | 45.3M/170M [07:32<14:40, 142kB/s]
27%|██▋ | 45.4M/170M [07:32<14:53, 140kB/s]
27%|██▋ | 45.4M/170M [07:33<13:38, 153kB/s]
27%|██▋ | 45.4M/170M [07:33<14:49, 141kB/s]
27%|██▋ | 45.4M/170M [07:33<14:18, 146kB/s]
27%|██▋ | 45.5M/170M [07:33<14:27, 144kB/s]
27%|██▋ | 45.5M/170M [07:33<13:55, 150kB/s]
27%|██▋ | 45.5M/170M [07:34<13:58, 149kB/s]
27%|██▋ | 45.6M/170M [07:34<13:02, 160kB/s]
27%|██▋ | 45.6M/170M [07:34<14:05, 148kB/s]
27%|██▋ | 45.6M/170M [07:34<13:59, 149kB/s]
27%|██▋ | 45.7M/170M [07:35<14:11, 147kB/s]
27%|██▋ | 45.7M/170M [07:35<14:27, 144kB/s]
27%|██▋ | 45.7M/170M [07:35<19:43, 105kB/s]
27%|██▋ | 45.8M/170M [07:36<22:35, 92.0kB/s]
27%|██▋ | 45.8M/170M [07:36<24:06, 86.2kB/s]
27%|██▋ | 45.8M/170M [07:37<27:19, 76.1kB/s]
27%|██▋ | 45.9M/170M [07:38<34:47, 59.7kB/s]
27%|██▋ | 45.9M/170M [07:38<36:21, 57.1kB/s]
27%|██▋ | 45.9M/170M [07:39<41:27, 50.1kB/s]
27%|██▋ | 46.0M/170M [07:40<51:21, 40.4kB/s]
27%|██▋ | 46.0M/170M [07:41<49:45, 41.7kB/s]
27%|██▋ | 46.0M/170M [07:41<38:49, 53.4kB/s]
27%|██▋ | 46.1M/170M [07:41<31:05, 66.7kB/s]
27%|██▋ | 46.1M/170M [07:42<26:25, 78.4kB/s]
27%|██▋ | 46.1M/170M [07:42<22:53, 90.5kB/s]
27%|██▋ | 46.2M/170M [07:42<20:20, 102kB/s]
27%|██▋ | 46.2M/170M [07:42<17:37, 118kB/s]
27%|██▋ | 46.2M/170M [07:43<17:01, 122kB/s]
27%|██▋ | 46.3M/170M [07:43<14:59, 138kB/s]
27%|██▋ | 46.3M/170M [07:43<14:47, 140kB/s]
27%|██▋ | 46.3M/170M [07:43<14:34, 142kB/s]
27%|██▋ | 46.4M/170M [07:43<14:37, 141kB/s]
27%|██▋ | 46.4M/170M [07:44<14:16, 145kB/s]
27%|██▋ | 46.4M/170M [07:44<14:49, 139kB/s]
27%|██▋ | 46.5M/170M [07:44<14:46, 140kB/s]
27%|██▋ | 46.5M/170M [07:44<15:31, 133kB/s]
27%|██▋ | 46.5M/170M [07:45<14:22, 144kB/s]
27%|██▋ | 46.6M/170M [07:45<14:09, 146kB/s]
27%|██▋ | 46.6M/170M [07:45<14:29, 142kB/s]
27%|██▋ | 46.6M/170M [07:45<14:59, 138kB/s]
27%|██▋ | 46.7M/170M [07:45<14:48, 139kB/s]
27%|██▋ | 46.7M/170M [07:46<14:19, 144kB/s]
27%|██▋ | 46.7M/170M [07:46<14:12, 145kB/s]
27%|██▋ | 46.8M/170M [07:46<15:46, 131kB/s]
27%|██▋ | 46.8M/170M [07:46<14:29, 142kB/s]
27%|██▋ | 46.8M/170M [07:47<14:40, 140kB/s]
27%|██▋ | 46.9M/170M [07:47<14:45, 140kB/s]
28%|██▊ | 46.9M/170M [07:47<13:32, 152kB/s]
28%|██▊ | 46.9M/170M [07:47<12:50, 160kB/s]
28%|██▊ | 47.0M/170M [07:47<13:25, 153kB/s]
28%|██▊ | 47.0M/170M [07:48<13:29, 153kB/s]
28%|██▊ | 47.0M/170M [07:48<15:47, 130kB/s]
28%|██▊ | 47.1M/170M [07:48<15:42, 131kB/s]
28%|██▊ | 47.1M/170M [07:48<15:05, 136kB/s]
28%|██▊ | 47.1M/170M [07:49<14:57, 138kB/s]
28%|██▊ | 47.2M/170M [07:49<16:02, 128kB/s]
28%|██▊ | 47.2M/170M [07:49<16:27, 125kB/s]
28%|██▊ | 47.2M/170M [07:50<30:00, 68.5kB/s]
28%|██▊ | 47.3M/170M [07:51<26:28, 77.6kB/s]
28%|██▊ | 47.3M/170M [07:51<22:23, 91.7kB/s]
28%|██▊ | 47.3M/170M [07:51<20:20, 101kB/s]
28%|██▊ | 47.3M/170M [07:51<19:53, 103kB/s]
28%|██▊ | 47.4M/170M [07:52<18:45, 109kB/s]
28%|██▊ | 47.4M/170M [07:52<18:05, 113kB/s]
28%|██▊ | 47.4M/170M [07:52<19:09, 107kB/s]
28%|██▊ | 47.5M/170M [07:52<19:23, 106kB/s]
28%|██▊ | 47.5M/170M [07:53<18:43, 109kB/s]
28%|██▊ | 47.5M/170M [07:53<18:38, 110kB/s]
28%|██▊ | 47.6M/170M [07:53<18:02, 114kB/s]
28%|██▊ | 47.6M/170M [07:54<17:01, 120kB/s]
28%|██▊ | 47.6M/170M [07:54<16:42, 123kB/s]
28%|██▊ | 47.7M/170M [07:54<16:21, 125kB/s]
28%|██▊ | 47.7M/170M [07:54<16:11, 126kB/s]
28%|██▊ | 47.7M/170M [07:55<16:50, 121kB/s]
28%|██▊ | 47.8M/170M [07:55<16:06, 127kB/s]
28%|██▊ | 47.8M/170M [07:55<17:56, 114kB/s]
28%|██▊ | 47.8M/170M [07:55<17:20, 118kB/s]
28%|██▊ | 47.9M/170M [07:56<16:17, 126kB/s]
28%|██▊ | 47.9M/170M [07:56<15:06, 135kB/s]
28%|██▊ | 47.9M/170M [07:56<17:52, 114kB/s]
28%|██▊ | 48.0M/170M [07:57<18:58, 108kB/s]
28%|██▊ | 48.0M/170M [07:57<19:34, 104kB/s]
28%|██▊ | 48.0M/170M [07:58<24:02, 84.9kB/s]
28%|██▊ | 48.1M/170M [07:58<20:32, 99.3kB/s]
28%|██▊ | 48.1M/170M [07:58<19:06, 107kB/s]
28%|██▊ | 48.1M/170M [07:58<18:00, 113kB/s]
28%|██▊ | 48.2M/170M [07:58<16:20, 125kB/s]
28%|██▊ | 48.2M/170M [07:59<15:58, 128kB/s]
28%|██▊ | 48.2M/170M [07:59<14:57, 136kB/s]
28%|██▊ | 48.3M/170M [07:59<14:53, 137kB/s]
28%|██▊ | 48.3M/170M [07:59<13:57, 146kB/s]
28%|██▊ | 48.3M/170M [08:00<14:12, 143kB/s]
28%|██▊ | 48.4M/170M [08:00<15:32, 131kB/s]
28%|██▊ | 48.4M/170M [08:00<17:49, 114kB/s]
28%|██▊ | 48.4M/170M [08:00<16:28, 123kB/s]
28%|██▊ | 48.5M/170M [08:01<16:57, 120kB/s]
28%|██▊ | 48.5M/170M [08:02<28:21, 71.7kB/s]
28%|██▊ | 48.5M/170M [08:02<26:24, 77.0kB/s]
28%|██▊ | 48.6M/170M [08:02<23:50, 85.2kB/s]
29%|██▊ | 48.6M/170M [08:03<23:24, 86.8kB/s]
29%|██▊ | 48.6M/170M [08:03<21:47, 93.2kB/s]
29%|██▊ | 48.7M/170M [08:03<20:49, 97.5kB/s]
29%|██▊ | 48.7M/170M [08:03<19:58, 102kB/s]
29%|██▊ | 48.7M/170M [08:04<20:06, 101kB/s]
29%|██▊ | 48.8M/170M [08:04<20:24, 99.4kB/s]
29%|██▊ | 48.8M/170M [08:05<21:09, 95.9kB/s]
29%|██▊ | 48.8M/170M [08:05<22:39, 89.5kB/s]
29%|██▊ | 48.9M/170M [08:05<24:25, 83.0kB/s]
29%|██▊ | 48.9M/170M [08:06<30:14, 67.0kB/s]
29%|██▊ | 48.9M/170M [08:07<29:58, 67.6kB/s]
29%|██▊ | 49.0M/170M [08:07<26:15, 77.1kB/s]
29%|██▊ | 49.0M/170M [08:07<25:31, 79.3kB/s]
29%|██▉ | 49.0M/170M [08:08<33:46, 59.9kB/s]
29%|██▉ | 49.1M/170M [08:09<36:12, 55.9kB/s]
29%|██▉ | 49.1M/170M [08:09<30:37, 66.1kB/s]
29%|██▉ | 49.1M/170M [08:09<27:37, 73.2kB/s]
29%|██▉ | 49.2M/170M [08:10<28:50, 70.1kB/s]
29%|██▉ | 49.2M/170M [08:10<25:06, 80.5kB/s]
29%|██▉ | 49.2M/170M [08:11<24:09, 83.7kB/s]
29%|██▉ | 49.3M/170M [08:11<22:50, 88.5kB/s]
29%|██▉ | 49.3M/170M [08:11<22:00, 91.8kB/s]
29%|██▉ | 49.3M/170M [08:11<19:52, 102kB/s]
29%|██▉ | 49.3M/170M [08:12<18:13, 111kB/s]
29%|██▉ | 49.4M/170M [08:12<17:42, 114kB/s]
29%|██▉ | 49.4M/170M [08:12<19:53, 101kB/s]
29%|██▉ | 49.4M/170M [08:13<19:15, 105kB/s]
29%|██▉ | 49.5M/170M [08:13<20:19, 99.2kB/s]
29%|██▉ | 49.5M/170M [08:13<20:40, 97.5kB/s]
29%|██▉ | 49.5M/170M [08:14<19:06, 105kB/s]
29%|██▉ | 49.6M/170M [08:14<19:03, 106kB/s]
29%|██▉ | 49.6M/170M [08:14<20:03, 100kB/s]
29%|██▉ | 49.6M/170M [08:15<19:59, 101kB/s]
29%|██▉ | 49.7M/170M [08:15<20:54, 96.3kB/s]
29%|██▉ | 49.7M/170M [08:15<19:12, 105kB/s]
29%|██▉ | 49.7M/170M [08:16<20:25, 98.5kB/s]
29%|██▉ | 49.8M/170M [08:16<18:40, 108kB/s]
29%|██▉ | 49.8M/170M [08:16<18:10, 111kB/s]
29%|██▉ | 49.8M/170M [08:17<21:22, 94.1kB/s]
29%|██▉ | 49.9M/170M [08:17<22:40, 88.7kB/s]
29%|██▉ | 49.9M/170M [08:17<23:04, 87.1kB/s]
29%|██▉ | 49.9M/170M [08:18<25:30, 78.8kB/s]
29%|██▉ | 50.0M/170M [08:18<28:48, 69.7kB/s]
29%|██▉ | 50.0M/170M [08:19<28:23, 70.7kB/s]
29%|██▉ | 50.0M/170M [08:19<26:46, 75.0kB/s]
29%|██▉ | 50.1M/170M [08:20<30:47, 65.2kB/s]
29%|██▉ | 50.1M/170M [08:21<35:31, 56.5kB/s]
29%|██▉ | 50.1M/170M [08:21<28:37, 70.1kB/s]
29%|██▉ | 50.2M/170M [08:21<23:33, 85.1kB/s]
29%|██▉ | 50.2M/170M [08:21<21:36, 92.8kB/s]
29%|██▉ | 50.2M/170M [08:22<19:35, 102kB/s]
29%|██▉ | 50.3M/170M [08:22<16:45, 120kB/s]
30%|██▉ | 50.3M/170M [08:22<15:57, 125kB/s]
30%|██▉ | 50.3M/170M [08:22<15:19, 131kB/s]
30%|██▉ | 50.4M/170M [08:23<15:17, 131kB/s]
30%|██▉ | 50.4M/170M [08:23<13:30, 148kB/s]
30%|██▉ | 50.4M/170M [08:23<13:51, 144kB/s]
30%|██▉ | 50.5M/170M [08:23<13:45, 145kB/s]
30%|██▉ | 50.5M/170M [08:23<13:17, 150kB/s]
30%|██▉ | 50.5M/170M [08:24<14:10, 141kB/s]
30%|██▉ | 50.6M/170M [08:24<13:41, 146kB/s]
30%|██▉ | 50.6M/170M [08:24<13:40, 146kB/s]
30%|██▉ | 50.6M/170M [08:24<14:36, 137kB/s]
30%|██▉ | 50.7M/170M [08:25<13:39, 146kB/s]
30%|██▉ | 50.7M/170M [08:25<13:28, 148kB/s]
30%|██▉ | 50.7M/170M [08:25<13:43, 145kB/s]
30%|██▉ | 50.8M/170M [08:25<13:48, 145kB/s]
30%|██▉ | 50.8M/170M [08:25<13:45, 145kB/s]
30%|██▉ | 50.8M/170M [08:26<13:38, 146kB/s]
30%|██▉ | 50.9M/170M [08:26<13:25, 148kB/s]
30%|██▉ | 50.9M/170M [08:26<13:24, 149kB/s]
30%|██▉ | 50.9M/170M [08:26<12:36, 158kB/s]
30%|██▉ | 51.0M/170M [08:26<13:10, 151kB/s]
30%|██▉ | 51.0M/170M [08:27<13:08, 151kB/s]
30%|██▉ | 51.0M/170M [08:27<12:28, 160kB/s]
30%|██▉ | 51.1M/170M [08:27<14:43, 135kB/s]
30%|██▉ | 51.1M/170M [08:27<13:55, 143kB/s]
30%|██▉ | 51.1M/170M [08:28<13:29, 148kB/s]
30%|███ | 51.2M/170M [08:28<14:09, 140kB/s]
30%|███ | 51.2M/170M [08:28<12:51, 155kB/s]
30%|███ | 51.2M/170M [08:28<14:08, 141kB/s]
30%|███ | 51.2M/170M [08:29<13:30, 147kB/s]
30%|███ | 51.3M/170M [08:29<13:19, 149kB/s]
30%|███ | 51.3M/170M [08:29<13:33, 147kB/s]
30%|███ | 51.3M/170M [08:29<12:40, 157kB/s]
30%|███ | 51.4M/170M [08:29<13:15, 150kB/s]
30%|███ | 51.4M/170M [08:30<19:24, 102kB/s]
30%|███ | 51.4M/170M [08:30<23:17, 85.2kB/s]
30%|███ | 51.5M/170M [08:31<22:10, 89.4kB/s]
30%|███ | 51.5M/170M [08:31<19:53, 99.7kB/s]
30%|███ | 51.5M/170M [08:31<19:01, 104kB/s]
30%|███ | 51.6M/170M [08:32<18:16, 108kB/s]
30%|███ | 51.6M/170M [08:32<16:19, 121kB/s]
30%|███ | 51.6M/170M [08:32<20:24, 97.1kB/s]
30%|███ | 51.7M/170M [08:33<19:47, 100kB/s]
30%|███ | 51.7M/170M [08:33<20:20, 97.3kB/s]
30%|███ | 51.7M/170M [08:33<20:10, 98.1kB/s]
30%|███ | 51.8M/170M [08:34<19:26, 102kB/s]
30%|███ | 51.8M/170M [08:34<19:46, 100kB/s]
30%|███ | 51.8M/170M [08:34<19:41, 100kB/s]
30%|███ | 51.9M/170M [08:35<20:21, 97.1kB/s]
30%|███ | 51.9M/170M [08:35<19:48, 99.8kB/s]
30%|███ | 51.9M/170M [08:35<16:31, 120kB/s]
30%|███ | 52.0M/170M [08:35<15:53, 124kB/s]
31%|███ | 52.0M/170M [08:36<15:52, 124kB/s]
31%|███ | 52.0M/170M [08:36<14:48, 133kB/s]
31%|███ | 52.1M/170M [08:36<14:53, 133kB/s]
31%|███ | 52.1M/170M [08:36<14:08, 140kB/s]
31%|███ | 52.1M/170M [08:37<15:30, 127kB/s]
31%|███ | 52.2M/170M [08:37<13:20, 148kB/s]
31%|███ | 52.2M/170M [08:37<13:41, 144kB/s]
31%|███ | 52.2M/170M [08:37<15:07, 130kB/s]
31%|███ | 52.3M/170M [08:37<14:38, 135kB/s]
31%|███ | 52.3M/170M [08:38<15:02, 131kB/s]
31%|███ | 52.3M/170M [08:38<14:02, 140kB/s]
31%|███ | 52.4M/170M [08:38<13:46, 143kB/s]
31%|███ | 52.4M/170M [08:38<13:15, 148kB/s]
31%|███ | 52.4M/170M [08:39<13:49, 142kB/s]
31%|███ | 52.5M/170M [08:39<14:28, 136kB/s]
31%|███ | 52.5M/170M [08:39<15:06, 130kB/s]
31%|███ | 52.5M/170M [08:39<15:51, 124kB/s]
31%|███ | 52.6M/170M [08:40<14:44, 133kB/s]
31%|███ | 52.6M/170M [08:40<15:55, 123kB/s]
31%|███ | 52.6M/170M [08:40<17:16, 114kB/s]
31%|███ | 52.7M/170M [08:41<17:02, 115kB/s]
31%|███ | 52.7M/170M [08:41<16:19, 120kB/s]
31%|███ | 52.7M/170M [08:41<15:05, 130kB/s]
31%|███ | 52.8M/170M [08:41<14:52, 132kB/s]
31%|███ | 52.8M/170M [08:41<14:00, 140kB/s]
31%|███ | 52.8M/170M [08:42<16:59, 115kB/s]
31%|███ | 52.9M/170M [08:42<20:02, 97.8kB/s]
31%|███ | 52.9M/170M [08:43<27:09, 72.2kB/s]
31%|███ | 52.9M/170M [08:44<28:47, 68.1kB/s]
31%|███ | 53.0M/170M [08:44<27:14, 71.9kB/s]
31%|███ | 53.0M/170M [08:44<25:35, 76.5kB/s]
31%|███ | 53.0M/170M [08:45<23:27, 83.5kB/s]
31%|███ | 53.1M/170M [08:45<21:11, 92.4kB/s]
31%|███ | 53.1M/170M [08:45<20:45, 94.3kB/s]
31%|███ | 53.1M/170M [08:46<20:48, 94.0kB/s]
31%|███ | 53.1M/170M [08:46<18:42, 105kB/s]
31%|███ | 53.2M/170M [08:46<18:38, 105kB/s]
31%|███ | 53.2M/170M [08:46<17:48, 110kB/s]
31%|███ | 53.2M/170M [08:47<18:19, 107kB/s]
31%|███▏ | 53.3M/170M [08:47<17:48, 110kB/s]
31%|███▏ | 53.3M/170M [08:47<17:53, 109kB/s]
31%|███▏ | 53.3M/170M [08:48<16:38, 117kB/s]
31%|███▏ | 53.4M/170M [08:48<17:32, 111kB/s]
31%|███▏ | 53.4M/170M [08:48<16:33, 118kB/s]
31%|███▏ | 53.4M/170M [08:48<16:45, 116kB/s]
31%|███▏ | 53.5M/170M [08:49<16:28, 118kB/s]
31%|███▏ | 53.5M/170M [08:49<16:27, 118kB/s]
31%|███▏ | 53.5M/170M [08:49<15:38, 125kB/s]
31%|███▏ | 53.6M/170M [08:49<17:06, 114kB/s]
31%|███▏ | 53.6M/170M [08:50<18:18, 106kB/s]
31%|███▏ | 53.6M/170M [08:50<18:45, 104kB/s]
31%|███▏ | 53.7M/170M [08:50<18:22, 106kB/s]
31%|███▏ | 53.7M/170M [08:51<17:57, 108kB/s]
32%|███▏ | 53.7M/170M [08:51<19:03, 102kB/s]
32%|███▏ | 53.8M/170M [08:51<19:41, 98.8kB/s]
32%|███▏ | 53.8M/170M [08:52<18:50, 103kB/s]
32%|███▏ | 53.8M/170M [08:52<17:56, 108kB/s]
32%|███▏ | 53.9M/170M [08:52<16:40, 117kB/s]
32%|███▏ | 53.9M/170M [08:52<15:58, 122kB/s]
32%|███▏ | 53.9M/170M [08:53<16:23, 118kB/s]
32%|███▏ | 54.0M/170M [08:53<15:38, 124kB/s]
32%|███▏ | 54.0M/170M [08:53<15:47, 123kB/s]
32%|███▏ | 54.0M/170M [08:54<15:37, 124kB/s]
32%|███▏ | 54.1M/170M [08:54<15:15, 127kB/s]
32%|███▏ | 54.1M/170M [08:54<16:33, 117kB/s]
32%|███▏ | 54.1M/170M [08:54<16:19, 119kB/s]
32%|███▏ | 54.2M/170M [08:55<17:22, 112kB/s]
32%|███▏ | 54.2M/170M [08:55<16:48, 115kB/s]
32%|███▏ | 54.2M/170M [08:55<16:17, 119kB/s]
32%|███▏ | 54.3M/170M [08:56<17:06, 113kB/s]
32%|███▏ | 54.3M/170M [08:56<18:17, 106kB/s]
32%|███▏ | 54.3M/170M [08:56<18:56, 102kB/s]
32%|███▏ | 54.4M/170M [08:57<18:42, 103kB/s]
32%|███▏ | 54.4M/170M [08:57<19:24, 99.7kB/s]
32%|███▏ | 54.4M/170M [08:57<18:47, 103kB/s]
32%|███▏ | 54.5M/170M [08:58<18:40, 104kB/s]
32%|███▏ | 54.5M/170M [08:58<19:01, 102kB/s]
32%|███▏ | 54.5M/170M [08:59<28:14, 68.4kB/s]
32%|███▏ | 54.6M/170M [08:59<33:12, 58.2kB/s]
32%|███▏ | 54.6M/170M [09:00<31:44, 60.9kB/s]
32%|███▏ | 54.6M/170M [09:01<32:23, 59.6kB/s]
32%|███▏ | 54.7M/170M [09:02<49:15, 39.2kB/s]
32%|███▏ | 54.7M/170M [09:03<44:23, 43.5kB/s]
32%|███▏ | 54.7M/170M [09:03<40:32, 47.6kB/s]
32%|███▏ | 54.8M/170M [09:04<42:34, 45.3kB/s]
32%|███▏ | 54.8M/170M [09:04<34:44, 55.5kB/s]
32%|███▏ | 54.8M/170M [09:04<28:04, 68.7kB/s]
32%|███▏ | 54.9M/170M [09:05<24:54, 77.4kB/s]
32%|███▏ | 54.9M/170M [09:05<20:07, 95.8kB/s]
32%|███▏ | 54.9M/170M [09:05<17:58, 107kB/s]
32%|███▏ | 55.0M/170M [09:05<17:50, 108kB/s]
32%|███▏ | 55.0M/170M [09:06<16:49, 114kB/s]
32%|███▏ | 55.0M/170M [09:06<14:41, 131kB/s]
32%|███▏ | 55.1M/170M [09:06<13:54, 138kB/s]
32%|███▏ | 55.1M/170M [09:06<14:25, 133kB/s]
32%|███▏ | 55.1M/170M [09:07<13:55, 138kB/s]
32%|███▏ | 55.1M/170M [09:07<14:05, 136kB/s]
32%|███▏ | 55.2M/170M [09:07<13:27, 143kB/s]
32%|███▏ | 55.2M/170M [09:07<13:04, 147kB/s]
32%|███▏ | 55.2M/170M [09:07<12:40, 152kB/s]
32%|███▏ | 55.3M/170M [09:08<12:46, 150kB/s]
32%|███▏ | 55.3M/170M [09:08<14:50, 129kB/s]
32%|███▏ | 55.3M/170M [09:08<15:40, 122kB/s]
32%|███▏ | 55.4M/170M [09:08<14:50, 129kB/s]
32%|███▏ | 55.4M/170M [09:09<14:42, 130kB/s]
33%|███▎ | 55.4M/170M [09:09<14:29, 132kB/s]
33%|███▎ | 55.5M/170M [09:09<17:45, 108kB/s]
33%|███▎ | 55.5M/170M [09:10<18:58, 101kB/s]
33%|███▎ | 55.5M/170M [09:10<17:24, 110kB/s]
33%|███▎ | 55.6M/170M [09:10<15:20, 125kB/s]
33%|███▎ | 55.6M/170M [09:10<15:30, 124kB/s]
33%|███▎ | 55.6M/170M [09:11<14:59, 128kB/s]
33%|███▎ | 55.7M/170M [09:11<13:53, 138kB/s]
33%|███▎ | 55.7M/170M [09:11<13:45, 139kB/s]
33%|███▎ | 55.7M/170M [09:11<13:25, 143kB/s]
33%|███▎ | 55.8M/170M [09:12<12:54, 148kB/s]
33%|███▎ | 55.8M/170M [09:12<12:35, 152kB/s]
33%|███▎ | 55.8M/170M [09:12<12:24, 154kB/s]
33%|███▎ | 55.9M/170M [09:12<12:21, 155kB/s]
33%|███▎ | 55.9M/170M [09:12<12:45, 150kB/s]
33%|███▎ | 55.9M/170M [09:13<12:28, 153kB/s]
33%|███▎ | 56.0M/170M [09:13<12:35, 152kB/s]
33%|███▎ | 56.0M/170M [09:13<13:16, 144kB/s]
33%|███▎ | 56.0M/170M [09:13<13:11, 145kB/s]
33%|███▎ | 56.1M/170M [09:13<12:52, 148kB/s]
33%|███▎ | 56.1M/170M [09:14<12:31, 152kB/s]
33%|███▎ | 56.1M/170M [09:14<12:47, 149kB/s]
33%|███▎ | 56.2M/170M [09:14<12:37, 151kB/s]
33%|███▎ | 56.2M/170M [09:14<11:58, 159kB/s]
33%|███▎ | 56.2M/170M [09:15<12:12, 156kB/s]
33%|███▎ | 56.3M/170M [09:15<12:01, 158kB/s]
33%|███▎ | 56.3M/170M [09:15<12:14, 155kB/s]
33%|███▎ | 56.3M/170M [09:15<13:58, 136kB/s]
33%|███▎ | 56.4M/170M [09:15<12:15, 155kB/s]
33%|███▎ | 56.4M/170M [09:16<12:25, 153kB/s]
33%|███▎ | 56.4M/170M [09:16<13:14, 144kB/s]
33%|███▎ | 56.5M/170M [09:16<11:48, 161kB/s]
33%|███▎ | 56.5M/170M [09:16<11:44, 162kB/s]
33%|███▎ | 56.5M/170M [09:16<12:04, 157kB/s]
33%|███▎ | 56.6M/170M [09:17<11:36, 164kB/s]
33%|███▎ | 56.6M/170M [09:17<12:08, 156kB/s]
33%|███▎ | 56.6M/170M [09:17<11:57, 159kB/s]
33%|███▎ | 56.7M/170M [09:17<12:35, 151kB/s]
33%|███▎ | 56.7M/170M [09:18<13:18, 142kB/s]
33%|███▎ | 56.7M/170M [09:18<12:37, 150kB/s]
33%|███▎ | 56.8M/170M [09:18<12:25, 153kB/s]
33%|███▎ | 56.8M/170M [09:18<12:28, 152kB/s]
33%|███▎ | 56.8M/170M [09:18<12:16, 154kB/s]
33%|███▎ | 56.9M/170M [09:19<11:35, 163kB/s]
33%|███▎ | 56.9M/170M [09:19<12:12, 155kB/s]
33%|███▎ | 56.9M/170M [09:19<12:28, 152kB/s]
33%|███▎ | 57.0M/170M [09:19<11:58, 158kB/s]
33%|███▎ | 57.0M/170M [09:19<11:56, 158kB/s]
33%|███▎ | 57.0M/170M [09:20<13:43, 138kB/s]
33%|███▎ | 57.0M/170M [09:20<13:39, 138kB/s]
33%|███▎ | 57.1M/170M [09:20<13:01, 145kB/s]
33%|███▎ | 57.1M/170M [09:20<13:00, 145kB/s]
34%|███▎ | 57.1M/170M [09:21<11:52, 159kB/s]
34%|███▎ | 57.2M/170M [09:21<11:59, 158kB/s]
34%|███▎ | 57.2M/170M [09:21<12:22, 153kB/s]
34%|███▎ | 57.2M/170M [09:21<14:50, 127kB/s]
34%|███▎ | 57.3M/170M [09:22<14:05, 134kB/s]
34%|███▎ | 57.3M/170M [09:22<12:48, 147kB/s]
34%|███▎ | 57.3M/170M [09:22<13:30, 140kB/s]
34%|███▎ | 57.4M/170M [09:22<13:20, 141kB/s]
34%|███▎ | 57.4M/170M [09:23<19:16, 97.8kB/s]
34%|███▎ | 57.4M/170M [09:23<17:50, 106kB/s]
34%|███▎ | 57.5M/170M [09:23<16:12, 116kB/s]
34%|███▎ | 57.5M/170M [09:24<15:42, 120kB/s]
34%|███▎ | 57.5M/170M [09:24<14:32, 129kB/s]
34%|███▍ | 57.6M/170M [09:24<13:59, 135kB/s]
34%|███▍ | 57.6M/170M [09:24<13:54, 135kB/s]
34%|███▍ | 57.6M/170M [09:24<13:11, 143kB/s]
34%|███▍ | 57.7M/170M [09:25<12:44, 148kB/s]
34%|███▍ | 57.7M/170M [09:25<13:42, 137kB/s]
34%|███▍ | 57.7M/170M [09:25<13:35, 138kB/s]
34%|███▍ | 57.8M/170M [09:25<12:52, 146kB/s]
34%|███▍ | 57.8M/170M [09:25<12:31, 150kB/s]
34%|███▍ | 57.8M/170M [09:26<13:12, 142kB/s]
34%|███▍ | 57.9M/170M [09:26<12:02, 156kB/s]
34%|███▍ | 57.9M/170M [09:26<13:25, 140kB/s]
34%|███▍ | 57.9M/170M [09:26<13:36, 138kB/s]
34%|███▍ | 58.0M/170M [09:27<12:07, 155kB/s]
34%|███▍ | 58.0M/170M [09:27<12:16, 153kB/s]
34%|███▍ | 58.0M/170M [09:27<13:00, 144kB/s]
34%|███▍ | 58.1M/170M [09:27<12:54, 145kB/s]
34%|███▍ | 58.1M/170M [09:28<12:33, 149kB/s]
34%|███▍ | 58.1M/170M [09:28<12:36, 149kB/s]
34%|███▍ | 58.2M/170M [09:28<11:55, 157kB/s]
34%|███▍ | 58.2M/170M [09:28<12:57, 144kB/s]
34%|███▍ | 58.2M/170M [09:29<16:05, 116kB/s]
34%|███▍ | 58.3M/170M [09:29<15:49, 118kB/s]
34%|███▍ | 58.3M/170M [09:29<15:41, 119kB/s]
34%|███▍ | 58.3M/170M [09:29<17:18, 108kB/s]
34%|███▍ | 58.4M/170M [09:30<18:20, 102kB/s]
34%|███▍ | 58.4M/170M [09:31<24:15, 77.0kB/s]
34%|███▍ | 58.4M/170M [09:31<23:34, 79.3kB/s]
34%|███▍ | 58.5M/170M [09:31<23:49, 78.4kB/s]
34%|███▍ | 58.5M/170M [09:32<25:46, 72.4kB/s]
34%|███▍ | 58.5M/170M [09:32<23:26, 79.6kB/s]
34%|███▍ | 58.6M/170M [09:33<23:07, 80.7kB/s]
34%|███▍ | 58.6M/170M [09:33<21:13, 87.9kB/s]
34%|███▍ | 58.6M/170M [09:33<21:47, 85.6kB/s]
34%|███▍ | 58.7M/170M [09:34<24:45, 75.3kB/s]
34%|███▍ | 58.7M/170M [09:34<23:12, 80.3kB/s]
34%|███▍ | 58.7M/170M [09:35<24:29, 76.1kB/s]
34%|███▍ | 58.8M/170M [09:35<21:14, 87.7kB/s]
34%|███▍ | 58.8M/170M [09:35<19:56, 93.4kB/s]
34%|███▍ | 58.8M/170M [09:35<16:39, 112kB/s]
35%|███▍ | 58.9M/170M [09:36<15:47, 118kB/s]
35%|███▍ | 58.9M/170M [09:36<14:34, 128kB/s]
35%|███▍ | 58.9M/170M [09:36<15:26, 120kB/s]
35%|███▍ | 58.9M/170M [09:36<14:04, 132kB/s]
35%|███▍ | 59.0M/170M [09:37<14:06, 132kB/s]
35%|███▍ | 59.0M/170M [09:37<14:05, 132kB/s]
35%|███▍ | 59.0M/170M [09:37<15:17, 121kB/s]
35%|███▍ | 59.1M/170M [09:37<14:36, 127kB/s]
35%|███▍ | 59.1M/170M [09:38<14:54, 125kB/s]
35%|███▍ | 59.1M/170M [09:38<14:35, 127kB/s]
35%|███▍ | 59.2M/170M [09:38<14:09, 131kB/s]
35%|███▍ | 59.2M/170M [09:38<13:41, 135kB/s]
35%|███▍ | 59.2M/170M [09:39<13:30, 137kB/s]
35%|███▍ | 59.3M/170M [09:39<14:38, 127kB/s]
35%|███▍ | 59.3M/170M [09:39<12:43, 146kB/s]
35%|███▍ | 59.3M/170M [09:39<12:43, 146kB/s]
35%|███▍ | 59.4M/170M [09:39<13:11, 140kB/s]
35%|███▍ | 59.4M/170M [09:40<13:27, 138kB/s]
35%|███▍ | 59.4M/170M [09:40<13:14, 140kB/s]
35%|███▍ | 59.5M/170M [09:40<13:13, 140kB/s]
35%|███▍ | 59.5M/170M [09:40<12:19, 150kB/s]
35%|███▍ | 59.5M/170M [09:41<13:15, 140kB/s]
35%|███▍ | 59.6M/170M [09:41<12:45, 145kB/s]
35%|███▍ | 59.6M/170M [09:41<13:42, 135kB/s]
35%|███▍ | 59.6M/170M [09:41<12:54, 143kB/s]
35%|███▍ | 59.7M/170M [09:42<12:57, 143kB/s]
35%|███▌ | 59.7M/170M [09:42<12:45, 145kB/s]
35%|███▌ | 59.7M/170M [09:42<14:28, 128kB/s]
35%|███▌ | 59.8M/170M [09:42<14:10, 130kB/s]
35%|███▌ | 59.8M/170M [09:43<15:08, 122kB/s]
35%|███▌ | 59.8M/170M [09:43<14:10, 130kB/s]
35%|███▌ | 59.9M/170M [09:43<12:57, 142kB/s]
35%|███▌ | 59.9M/170M [09:43<12:59, 142kB/s]
35%|███▌ | 59.9M/170M [09:43<12:10, 151kB/s]
35%|███▌ | 60.0M/170M [09:44<12:24, 148kB/s]
35%|███▌ | 60.0M/170M [09:44<13:00, 142kB/s]
35%|███▌ | 60.0M/170M [09:44<12:02, 153kB/s]
35%|███▌ | 60.1M/170M [09:44<11:26, 161kB/s]
35%|███▌ | 60.1M/170M [09:45<13:32, 136kB/s]
35%|███▌ | 60.1M/170M [09:45<12:49, 143kB/s]
35%|███▌ | 60.2M/170M [09:45<12:29, 147kB/s]
35%|███▌ | 60.2M/170M [09:45<13:59, 131kB/s]
35%|███▌ | 60.2M/170M [09:46<16:49, 109kB/s]
35%|███▌ | 60.3M/170M [09:46<17:16, 106kB/s]
35%|███▌ | 60.3M/170M [09:46<17:38, 104kB/s]
35%|███▌ | 60.3M/170M [09:47<24:18, 75.5kB/s]
35%|███▌ | 60.4M/170M [09:48<25:36, 71.7kB/s]
35%|███▌ | 60.4M/170M [09:48<24:21, 75.3kB/s]
35%|███▌ | 60.4M/170M [09:48<22:35, 81.2kB/s]
35%|███▌ | 60.5M/170M [09:49<20:21, 90.1kB/s]
35%|███▌ | 60.5M/170M [09:49<18:41, 98.1kB/s]
35%|███▌ | 60.5M/170M [09:49<18:55, 96.8kB/s]
36%|███▌ | 60.6M/170M [09:50<17:22, 105kB/s]
36%|███▌ | 60.6M/170M [09:50<16:15, 113kB/s]
36%|███▌ | 60.6M/170M [09:50<15:09, 121kB/s]
36%|███▌ | 60.7M/170M [09:50<13:54, 132kB/s]
36%|███▌ | 60.7M/170M [09:50<13:17, 138kB/s]
36%|███▌ | 60.7M/170M [09:51<12:39, 145kB/s]
36%|███▌ | 60.8M/170M [09:51<12:35, 145kB/s]
36%|███▌ | 60.8M/170M [09:51<12:44, 143kB/s]
36%|███▌ | 60.8M/170M [09:51<12:42, 144kB/s]
36%|███▌ | 60.9M/170M [09:51<12:11, 150kB/s]
36%|███▌ | 60.9M/170M [09:52<12:25, 147kB/s]
36%|███▌ | 60.9M/170M [09:52<11:42, 156kB/s]
36%|███▌ | 60.9M/170M [09:52<12:31, 146kB/s]
36%|███▌ | 61.0M/170M [09:52<12:06, 151kB/s]
36%|███▌ | 61.0M/170M [09:53<12:33, 145kB/s]
36%|███▌ | 61.0M/170M [09:53<12:18, 148kB/s]
36%|███▌ | 61.1M/170M [09:53<12:32, 145kB/s]
36%|███▌ | 61.1M/170M [09:53<13:20, 137kB/s]
36%|███▌ | 61.1M/170M [09:54<13:23, 136kB/s]
36%|███▌ | 61.2M/170M [09:54<13:00, 140kB/s]
36%|███▌ | 61.2M/170M [09:54<12:18, 148kB/s]
36%|███▌ | 61.2M/170M [09:54<12:23, 147kB/s]
36%|███▌ | 61.3M/170M [09:54<12:01, 151kB/s]
36%|███▌ | 61.3M/170M [09:55<11:59, 152kB/s]
36%|███▌ | 61.3M/170M [09:55<12:03, 151kB/s]
36%|███▌ | 61.4M/170M [09:55<11:26, 159kB/s]
36%|███▌ | 61.4M/170M [09:55<12:03, 151kB/s]
36%|███▌ | 61.4M/170M [09:56<13:06, 139kB/s]
36%|███▌ | 61.5M/170M [09:56<12:09, 149kB/s]
36%|███▌ | 61.5M/170M [09:56<12:12, 149kB/s]
36%|███▌ | 61.5M/170M [09:56<11:55, 152kB/s]
36%|███▌ | 61.6M/170M [09:56<12:18, 147kB/s]
36%|███▌ | 61.6M/170M [09:57<12:01, 151kB/s]
36%|███▌ | 61.6M/170M [09:57<12:55, 140kB/s]
36%|███▌ | 61.7M/170M [09:57<12:10, 149kB/s]
36%|███▌ | 61.7M/170M [09:57<13:02, 139kB/s]
36%|███▌ | 61.7M/170M [09:58<14:00, 129kB/s]
36%|███▌ | 61.8M/170M [09:58<13:33, 134kB/s]
36%|███▌ | 61.8M/170M [09:58<13:32, 134kB/s]
36%|███▋ | 61.8M/170M [09:58<13:19, 136kB/s]
36%|███▋ | 61.9M/170M [09:58<12:04, 150kB/s]
36%|███▋ | 61.9M/170M [09:59<12:57, 140kB/s]
36%|███▋ | 61.9M/170M [09:59<12:48, 141kB/s]
36%|███▋ | 62.0M/170M [09:59<13:02, 139kB/s]
36%|███▋ | 62.0M/170M [09:59<13:09, 137kB/s]
36%|███▋ | 62.0M/170M [10:00<13:50, 131kB/s]
36%|███▋ | 62.1M/170M [10:00<11:59, 151kB/s]
36%|███▋ | 62.1M/170M [10:00<13:09, 137kB/s]
36%|███▋ | 62.1M/170M [10:00<13:12, 137kB/s]
36%|███▋ | 62.2M/170M [10:01<13:08, 137kB/s]
36%|███▋ | 62.2M/170M [10:01<12:53, 140kB/s]
36%|███▋ | 62.2M/170M [10:01<12:44, 142kB/s]
37%|███▋ | 62.3M/170M [10:01<12:26, 145kB/s]
37%|███▋ | 62.3M/170M [10:02<12:34, 143kB/s]
37%|███▋ | 62.3M/170M [10:02<12:57, 139kB/s]
37%|███▋ | 62.4M/170M [10:02<12:13, 147kB/s]
37%|███▋ | 62.4M/170M [10:02<12:42, 142kB/s]
37%|███▋ | 62.4M/170M [10:02<12:08, 148kB/s]
37%|███▋ | 62.5M/170M [10:03<12:14, 147kB/s]
37%|███▋ | 62.5M/170M [10:03<13:06, 137kB/s]
37%|███▋ | 62.5M/170M [10:03<12:24, 145kB/s]
37%|███▋ | 62.6M/170M [10:03<11:49, 152kB/s]
37%|███▋ | 62.6M/170M [10:04<11:50, 152kB/s]
37%|███▋ | 62.6M/170M [10:04<11:57, 150kB/s]
37%|███▋ | 62.7M/170M [10:04<12:38, 142kB/s]
37%|███▋ | 62.7M/170M [10:04<11:50, 152kB/s]
37%|███▋ | 62.7M/170M [10:04<11:54, 151kB/s]
37%|███▋ | 62.8M/170M [10:05<11:44, 153kB/s]
37%|███▋ | 62.8M/170M [10:05<12:32, 143kB/s]
37%|███▋ | 62.8M/170M [10:05<12:58, 138kB/s]
37%|███▋ | 62.8M/170M [10:05<12:42, 141kB/s]
37%|███▋ | 62.9M/170M [10:06<12:58, 138kB/s]
37%|███▋ | 62.9M/170M [10:06<12:57, 138kB/s]
37%|███▋ | 62.9M/170M [10:06<13:15, 135kB/s]
37%|███▋ | 63.0M/170M [10:06<12:29, 143kB/s]
37%|███▋ | 63.0M/170M [10:07<12:42, 141kB/s]
37%|███▋ | 63.0M/170M [10:07<20:49, 86.0kB/s]
37%|███▋ | 63.1M/170M [10:08<21:19, 84.0kB/s]
37%|███▋ | 63.1M/170M [10:08<22:33, 79.4kB/s]
37%|███▋ | 63.1M/170M [10:09<22:46, 78.5kB/s]
37%|███▋ | 63.2M/170M [10:09<22:52, 78.2kB/s]
37%|███▋ | 63.2M/170M [10:10<24:11, 73.9kB/s]
37%|███▋ | 63.2M/170M [10:10<24:35, 72.7kB/s]
37%|███▋ | 63.3M/170M [10:10<22:43, 78.6kB/s]
37%|███▋ | 63.3M/170M [10:11<20:29, 87.2kB/s]
37%|███▋ | 63.3M/170M [10:11<17:51, 100kB/s]
37%|███▋ | 63.4M/170M [10:11<16:02, 111kB/s]
37%|███▋ | 63.4M/170M [10:11<14:53, 120kB/s]
37%|███▋ | 63.4M/170M [10:11<14:25, 124kB/s]
37%|███▋ | 63.5M/170M [10:12<13:37, 131kB/s]
37%|███▋ | 63.5M/170M [10:12<15:02, 119kB/s]
37%|███▋ | 63.5M/170M [10:12<15:10, 117kB/s]
37%|███▋ | 63.6M/170M [10:13<15:01, 119kB/s]
37%|███▋ | 63.6M/170M [10:13<14:36, 122kB/s]
37%|███▋ | 63.6M/170M [10:13<15:02, 118kB/s]
37%|███▋ | 63.7M/170M [10:14<16:35, 107kB/s]
37%|███▋ | 63.7M/170M [10:14<15:16, 116kB/s]
37%|███▋ | 63.7M/170M [10:14<14:20, 124kB/s]
37%|███▋ | 63.8M/170M [10:14<15:01, 118kB/s]
37%|███▋ | 63.8M/170M [10:15<16:01, 111kB/s]
37%|███▋ | 63.8M/170M [10:15<17:53, 99.3kB/s]
37%|███▋ | 63.9M/170M [10:15<18:34, 95.7kB/s]
37%|███▋ | 63.9M/170M [10:16<17:03, 104kB/s]
37%|███▋ | 63.9M/170M [10:16<16:21, 109kB/s]
38%|███▊ | 64.0M/170M [10:16<16:00, 111kB/s]
38%|███▊ | 64.0M/170M [10:17<16:05, 110kB/s]
38%|███▊ | 64.0M/170M [10:17<15:55, 111kB/s]
38%|███▊ | 64.1M/170M [10:18<22:49, 77.7kB/s]
38%|███▊ | 64.1M/170M [10:18<22:08, 80.1kB/s]
38%|███▊ | 64.1M/170M [10:18<19:56, 88.9kB/s]
38%|███▊ | 64.2M/170M [10:18<18:37, 95.2kB/s]
38%|███▊ | 64.2M/170M [10:19<17:14, 103kB/s]
38%|███▊ | 64.2M/170M [10:19<16:21, 108kB/s]
38%|███▊ | 64.3M/170M [10:19<18:02, 98.2kB/s]
38%|███▊ | 64.3M/170M [10:20<16:45, 106kB/s]
38%|███▊ | 64.3M/170M [10:20<15:29, 114kB/s]
38%|███▊ | 64.4M/170M [10:20<14:55, 119kB/s]
38%|███▊ | 64.4M/170M [10:20<13:50, 128kB/s]
38%|███▊ | 64.4M/170M [10:21<13:47, 128kB/s]
38%|███▊ | 64.5M/170M [10:21<13:33, 130kB/s]
38%|███▊ | 64.5M/170M [10:21<13:38, 129kB/s]
38%|███▊ | 64.5M/170M [10:21<13:26, 131kB/s]
38%|███▊ | 64.6M/170M [10:22<13:05, 135kB/s]
38%|███▊ | 64.6M/170M [10:22<18:29, 95.5kB/s]
38%|███▊ | 64.6M/170M [10:22<17:09, 103kB/s]
38%|███▊ | 64.7M/170M [10:23<16:13, 109kB/s]
38%|███▊ | 64.7M/170M [10:23<14:31, 121kB/s]
38%|███▊ | 64.7M/170M [10:23<13:54, 127kB/s]
38%|███▊ | 64.7M/170M [10:23<13:21, 132kB/s]
38%|███▊ | 64.8M/170M [10:24<13:45, 128kB/s]
38%|███▊ | 64.8M/170M [10:24<13:02, 135kB/s]
38%|███▊ | 64.8M/170M [10:24<13:19, 132kB/s]
38%|███▊ | 64.9M/170M [10:24<14:01, 126kB/s]
38%|███▊ | 64.9M/170M [10:25<14:11, 124kB/s]
38%|███▊ | 64.9M/170M [10:25<14:18, 123kB/s]
38%|███▊ | 65.0M/170M [10:25<14:57, 118kB/s]
38%|███▊ | 65.0M/170M [10:25<13:57, 126kB/s]
38%|███▊ | 65.0M/170M [10:26<13:53, 127kB/s]
38%|███▊ | 65.1M/170M [10:26<13:39, 129kB/s]
38%|███▊ | 65.1M/170M [10:26<13:20, 132kB/s]
38%|███▊ | 65.1M/170M [10:26<13:31, 130kB/s]
38%|███▊ | 65.2M/170M [10:27<13:44, 128kB/s]
38%|███▊ | 65.2M/170M [10:27<15:14, 115kB/s]
38%|███▊ | 65.2M/170M [10:27<15:49, 111kB/s]
38%|███▊ | 65.3M/170M [10:28<15:34, 113kB/s]
38%|███▊ | 65.3M/170M [10:28<15:18, 115kB/s]
38%|███▊ | 65.3M/170M [10:28<15:35, 112kB/s]
38%|███▊ | 65.4M/170M [10:28<14:55, 117kB/s]
38%|███▊ | 65.4M/170M [10:29<15:11, 115kB/s]
38%|███▊ | 65.4M/170M [10:29<14:30, 121kB/s]
38%|███▊ | 65.5M/170M [10:29<14:41, 119kB/s]
38%|███▊ | 65.5M/170M [10:30<14:50, 118kB/s]
38%|███▊ | 65.5M/170M [10:30<15:43, 111kB/s]
38%|███▊ | 65.6M/170M [10:30<15:46, 111kB/s]
38%|███▊ | 65.6M/170M [10:30<13:59, 125kB/s]
38%|███▊ | 65.6M/170M [10:31<13:11, 133kB/s]
39%|███▊ | 65.7M/170M [10:31<12:36, 139kB/s]
39%|███▊ | 65.7M/170M [10:31<12:10, 143kB/s]
39%|███▊ | 65.7M/170M [10:31<12:27, 140kB/s]
39%|███▊ | 65.8M/170M [10:32<13:17, 131kB/s]
39%|███▊ | 65.8M/170M [10:32<13:04, 133kB/s]
39%|███▊ | 65.8M/170M [10:32<13:14, 132kB/s]
39%|███▊ | 65.9M/170M [10:32<13:30, 129kB/s]
39%|███▊ | 65.9M/170M [10:33<14:22, 121kB/s]
39%|███▊ | 65.9M/170M [10:33<13:45, 127kB/s]
39%|███▊ | 66.0M/170M [10:33<13:50, 126kB/s]
39%|███▊ | 66.0M/170M [10:33<13:10, 132kB/s]
39%|███▊ | 66.0M/170M [10:34<13:34, 128kB/s]
39%|███▊ | 66.1M/170M [10:34<12:20, 141kB/s]
39%|███▉ | 66.1M/170M [10:34<13:39, 127kB/s]
39%|███▉ | 66.1M/170M [10:34<13:28, 129kB/s]
39%|███▉ | 66.2M/170M [10:35<14:12, 122kB/s]
39%|███▉ | 66.2M/170M [10:35<14:41, 118kB/s]
39%|███▉ | 66.2M/170M [10:35<16:46, 104kB/s]
39%|███▉ | 66.3M/170M [10:36<17:35, 98.8kB/s]
39%|███▉ | 66.3M/170M [10:36<17:04, 102kB/s]
39%|███▉ | 66.3M/170M [10:36<17:26, 99.6kB/s]
39%|███▉ | 66.4M/170M [10:37<17:00, 102kB/s]
39%|███▉ | 66.4M/170M [10:37<16:02, 108kB/s]
39%|███▉ | 66.4M/170M [10:37<16:14, 107kB/s]
39%|███▉ | 66.5M/170M [10:38<15:45, 110kB/s]
39%|███▉ | 66.5M/170M [10:38<16:16, 106kB/s]
39%|███▉ | 66.5M/170M [10:38<15:17, 113kB/s]
39%|███▉ | 66.6M/170M [10:38<15:25, 112kB/s]
39%|███▉ | 66.6M/170M [10:39<16:46, 103kB/s]
39%|███▉ | 66.6M/170M [10:39<18:04, 95.8kB/s]
39%|███▉ | 66.7M/170M [10:39<17:45, 97.5kB/s]
39%|███▉ | 66.7M/170M [10:40<16:34, 104kB/s]
39%|███▉ | 66.7M/170M [10:40<16:24, 105kB/s]
39%|███▉ | 66.7M/170M [10:40<15:54, 109kB/s]
39%|███▉ | 66.8M/170M [10:41<16:26, 105kB/s]
39%|███▉ | 66.8M/170M [10:41<15:53, 109kB/s]
39%|███▉ | 66.8M/170M [10:41<16:06, 107kB/s]
39%|███▉ | 66.9M/170M [10:42<16:01, 108kB/s]
39%|███▉ | 66.9M/170M [10:42<17:46, 97.1kB/s]
39%|███▉ | 66.9M/170M [10:42<19:49, 87.1kB/s]
39%|███▉ | 67.0M/170M [10:43<19:01, 90.7kB/s]
39%|███▉ | 67.0M/170M [10:43<18:47, 91.8kB/s]
39%|███▉ | 67.0M/170M [10:43<17:23, 99.2kB/s]
39%|███▉ | 67.1M/170M [10:44<17:27, 98.7kB/s]
39%|███▉ | 67.1M/170M [10:44<17:48, 96.8kB/s]
39%|███▉ | 67.1M/170M [10:44<15:42, 110kB/s]
39%|███▉ | 67.2M/170M [10:45<15:45, 109kB/s]
39%|███▉ | 67.2M/170M [10:45<15:35, 110kB/s]
39%|███▉ | 67.2M/170M [10:45<16:21, 105kB/s]
39%|███▉ | 67.3M/170M [10:46<18:05, 95.1kB/s]
39%|███▉ | 67.3M/170M [10:46<19:06, 90.0kB/s]
39%|███▉ | 67.3M/170M [10:46<17:21, 99.0kB/s]
40%|███▉ | 67.4M/170M [10:47<17:17, 99.4kB/s]
40%|███▉ | 67.4M/170M [10:47<17:29, 98.2kB/s]
40%|███▉ | 67.4M/170M [10:47<16:26, 104kB/s]
40%|███▉ | 67.5M/170M [10:48<16:11, 106kB/s]
40%|███▉ | 67.5M/170M [10:48<15:03, 114kB/s]
40%|███▉ | 67.5M/170M [10:48<17:02, 101kB/s]
40%|███▉ | 67.6M/170M [10:48<15:05, 114kB/s]
40%|███▉ | 67.6M/170M [10:49<14:59, 114kB/s]
40%|███▉ | 67.6M/170M [10:49<14:19, 120kB/s]
40%|███▉ | 67.7M/170M [10:49<13:54, 123kB/s]
40%|███▉ | 67.7M/170M [10:49<12:32, 137kB/s]
40%|███▉ | 67.7M/170M [10:50<12:55, 133kB/s]
40%|███▉ | 67.8M/170M [10:50<12:29, 137kB/s]
40%|███▉ | 67.8M/170M [10:50<11:59, 143kB/s]
40%|███▉ | 67.8M/170M [10:50<12:26, 138kB/s]
40%|███▉ | 67.9M/170M [10:51<12:20, 139kB/s]
40%|███▉ | 67.9M/170M [10:51<13:11, 130kB/s]
40%|███▉ | 67.9M/170M [10:51<13:25, 127kB/s]
40%|███▉ | 68.0M/170M [10:51<12:55, 132kB/s]
40%|███▉ | 68.0M/170M [10:52<12:25, 137kB/s]
40%|███▉ | 68.0M/170M [10:52<12:38, 135kB/s]
40%|███▉ | 68.1M/170M [10:52<13:10, 130kB/s]
40%|███▉ | 68.1M/170M [10:52<12:18, 139kB/s]
40%|███▉ | 68.1M/170M [10:53<13:08, 130kB/s]
40%|███▉ | 68.2M/170M [10:53<13:57, 122kB/s]
40%|███▉ | 68.2M/170M [10:53<13:54, 123kB/s]
40%|████ | 68.2M/170M [10:53<13:09, 130kB/s]
40%|████ | 68.3M/170M [10:54<13:41, 125kB/s]
40%|████ | 68.3M/170M [10:54<14:37, 117kB/s]
40%|████ | 68.3M/170M [10:54<13:51, 123kB/s]
40%|████ | 68.4M/170M [10:54<14:06, 121kB/s]
40%|████ | 68.4M/170M [10:55<13:40, 124kB/s]
40%|████ | 68.4M/170M [10:55<14:41, 116kB/s]
40%|████ | 68.5M/170M [10:55<15:10, 112kB/s]
40%|████ | 68.5M/170M [10:56<16:08, 105kB/s]
40%|████ | 68.5M/170M [10:56<15:59, 106kB/s]
40%|████ | 68.6M/170M [10:56<15:13, 112kB/s]
40%|████ | 68.6M/170M [10:56<14:15, 119kB/s]
40%|████ | 68.6M/170M [10:57<15:45, 108kB/s]
40%|████ | 68.6M/170M [10:57<14:48, 115kB/s]
40%|████ | 68.7M/170M [10:57<15:12, 112kB/s]
40%|████ | 68.7M/170M [10:58<15:12, 112kB/s]
40%|████ | 68.7M/170M [10:58<14:48, 115kB/s]
40%|████ | 68.8M/170M [10:58<14:38, 116kB/s]
40%|████ | 68.8M/170M [10:59<14:21, 118kB/s]
40%|████ | 68.8M/170M [10:59<14:24, 118kB/s]
40%|████ | 68.9M/170M [10:59<15:44, 108kB/s]
40%|████ | 68.9M/170M [10:59<13:41, 124kB/s]
40%|████ | 68.9M/170M [11:00<14:12, 119kB/s]
40%|████ | 69.0M/170M [11:00<14:53, 114kB/s]
40%|████ | 69.0M/170M [11:00<14:25, 117kB/s]
40%|████ | 69.0M/170M [11:00<14:08, 120kB/s]
41%|████ | 69.1M/170M [11:01<13:34, 125kB/s]
41%|████ | 69.1M/170M [11:01<13:17, 127kB/s]
41%|████ | 69.1M/170M [11:01<13:13, 128kB/s]
41%|████ | 69.2M/170M [11:01<12:24, 136kB/s]
41%|████ | 69.2M/170M [11:02<13:45, 123kB/s]
41%|████ | 69.2M/170M [11:02<12:09, 139kB/s]
41%|████ | 69.3M/170M [11:02<12:13, 138kB/s]
41%|████ | 69.3M/170M [11:02<13:22, 126kB/s]
41%|████ | 69.3M/170M [11:03<13:18, 127kB/s]
41%|████ | 69.4M/170M [11:03<12:53, 131kB/s]
41%|████ | 69.4M/170M [11:03<12:16, 137kB/s]
41%|████ | 69.4M/170M [11:03<12:50, 131kB/s]
41%|████ | 69.5M/170M [11:04<12:05, 139kB/s]
41%|████ | 69.5M/170M [11:04<13:06, 128kB/s]
41%|████ | 69.5M/170M [11:04<12:36, 133kB/s]
41%|████ | 69.6M/170M [11:05<23:28, 71.7kB/s]
41%|████ | 69.6M/170M [11:05<21:25, 78.5kB/s]
41%|████ | 69.6M/170M [11:07<31:38, 53.1kB/s]
41%|████ | 69.7M/170M [11:07<29:07, 57.7kB/s]
41%|████ | 69.7M/170M [11:07<25:39, 65.5kB/s]
41%|████ | 69.7M/170M [11:08<24:24, 68.8kB/s]
41%|████ | 69.8M/170M [11:08<22:27, 74.8kB/s]
41%|████ | 69.8M/170M [11:08<21:15, 79.0kB/s]
41%|████ | 69.8M/170M [11:09<23:09, 72.5kB/s]
41%|████ | 69.9M/170M [11:10<25:40, 65.3kB/s]
41%|████ | 69.9M/170M [11:10<25:45, 65.1kB/s]
41%|████ | 69.9M/170M [11:11<25:23, 66.0kB/s]
41%|████ | 70.0M/170M [11:11<22:38, 74.0kB/s]
41%|████ | 70.0M/170M [11:11<23:40, 70.7kB/s]
41%|████ | 70.0M/170M [11:12<22:34, 74.2kB/s]
41%|████ | 70.1M/170M [11:12<20:32, 81.5kB/s]
41%|████ | 70.1M/170M [11:13<22:16, 75.1kB/s]
41%|████ | 70.1M/170M [11:13<22:32, 74.2kB/s]
41%|████ | 70.2M/170M [11:13<21:28, 77.9kB/s]
41%|████ | 70.2M/170M [11:14<20:08, 83.0kB/s]
41%|████ | 70.2M/170M [11:14<18:42, 89.3kB/s]
41%|████ | 70.3M/170M [11:14<17:44, 94.2kB/s]
41%|████ | 70.3M/170M [11:15<17:55, 93.2kB/s]
41%|████ | 70.3M/170M [11:15<20:56, 79.7kB/s]
41%|████▏ | 70.4M/170M [11:16<20:00, 83.4kB/s]
41%|████▏ | 70.4M/170M [11:16<19:17, 86.5kB/s]
41%|████▏ | 70.4M/170M [11:17<21:31, 77.5kB/s]
41%|████▏ | 70.5M/170M [11:17<24:39, 67.6kB/s]
41%|████▏ | 70.5M/170M [11:18<24:57, 66.8kB/s]
41%|████▏ | 70.5M/170M [11:18<24:43, 67.4kB/s]
41%|████▏ | 70.5M/170M [11:18<22:44, 73.3kB/s]
41%|████▏ | 70.6M/170M [11:19<19:49, 84.0kB/s]
41%|████▏ | 70.6M/170M [11:19<18:11, 91.5kB/s]
41%|████▏ | 70.6M/170M [11:19<16:22, 102kB/s]
41%|████▏ | 70.7M/170M [11:20<16:31, 101kB/s]
41%|████▏ | 70.7M/170M [11:20<15:49, 105kB/s]
41%|████▏ | 70.7M/170M [11:20<15:52, 105kB/s]
42%|████▏ | 70.8M/170M [11:21<16:24, 101kB/s]
42%|████▏ | 70.8M/170M [11:21<16:20, 102kB/s]
42%|████▏ | 70.8M/170M [11:21<15:49, 105kB/s]
42%|████▏ | 70.9M/170M [11:21<14:20, 116kB/s]
42%|████▏ | 70.9M/170M [11:22<14:26, 115kB/s]
42%|████▏ | 70.9M/170M [11:22<13:56, 119kB/s]
42%|████▏ | 71.0M/170M [11:22<14:07, 117kB/s]
42%|████▏ | 71.0M/170M [11:23<15:26, 107kB/s]
42%|████▏ | 71.0M/170M [11:23<14:44, 112kB/s]
42%|████▏ | 71.1M/170M [11:23<13:52, 119kB/s]
42%|████▏ | 71.1M/170M [11:23<13:37, 122kB/s]
42%|████▏ | 71.1M/170M [11:24<13:06, 126kB/s]
42%|████▏ | 71.2M/170M [11:24<13:36, 122kB/s]
42%|████▏ | 71.2M/170M [11:24<14:39, 113kB/s]
42%|████▏ | 71.2M/170M [11:25<14:55, 111kB/s]
42%|████▏ | 71.3M/170M [11:25<14:56, 111kB/s]
42%|████▏ | 71.3M/170M [11:25<15:58, 103kB/s]
42%|████▏ | 71.3M/170M [11:26<24:00, 68.8kB/s]
42%|████▏ | 71.4M/170M [11:26<23:52, 69.2kB/s]
42%|████▏ | 71.4M/170M [11:27<22:01, 75.0kB/s]
42%|████▏ | 71.4M/170M [11:27<20:51, 79.2kB/s]
42%|████▏ | 71.5M/170M [11:28<26:01, 63.4kB/s]
42%|████▏ | 71.5M/170M [11:28<22:08, 74.5kB/s]
42%|████▏ | 71.5M/170M [11:28<19:46, 83.4kB/s]
42%|████▏ | 71.6M/170M [11:29<18:05, 91.2kB/s]
42%|████▏ | 71.6M/170M [11:29<21:32, 76.5kB/s]
42%|████▏ | 71.6M/170M [11:30<24:09, 68.2kB/s]
42%|████▏ | 71.7M/170M [11:31<25:58, 63.4kB/s]
42%|████▏ | 71.7M/170M [11:31<29:51, 55.1kB/s]
42%|████▏ | 71.7M/170M [11:32<24:59, 65.9kB/s]
42%|████▏ | 71.8M/170M [11:32<22:22, 73.6kB/s]
42%|████▏ | 71.8M/170M [11:32<20:48, 79.1kB/s]
42%|████▏ | 71.8M/170M [11:33<27:05, 60.7kB/s]
42%|████▏ | 71.9M/170M [11:34<25:52, 63.5kB/s]
42%|████▏ | 71.9M/170M [11:34<22:34, 72.8kB/s]
42%|████▏ | 71.9M/170M [11:34<20:41, 79.4kB/s]
42%|████▏ | 72.0M/170M [11:34<18:50, 87.1kB/s]
42%|████▏ | 72.0M/170M [11:35<17:47, 92.3kB/s]
42%|████▏ | 72.0M/170M [11:35<17:24, 94.3kB/s]
42%|████▏ | 72.1M/170M [11:35<17:27, 93.9kB/s]
42%|████▏ | 72.1M/170M [11:36<17:02, 96.3kB/s]
42%|████▏ | 72.1M/170M [11:36<16:54, 97.0kB/s]
42%|████▏ | 72.2M/170M [11:37<19:35, 83.7kB/s]
42%|████▏ | 72.2M/170M [11:37<25:59, 63.1kB/s]
42%|████▏ | 72.2M/170M [11:38<23:48, 68.8kB/s]
42%|████▏ | 72.3M/170M [11:38<23:04, 71.0kB/s]
42%|████▏ | 72.3M/170M [11:39<23:25, 69.9kB/s]
42%|████▏ | 72.3M/170M [11:39<23:00, 71.1kB/s]
42%|████▏ | 72.4M/170M [11:40<23:57, 68.3kB/s]
42%|████▏ | 72.4M/170M [11:40<26:21, 62.0kB/s]
42%|████▏ | 72.4M/170M [11:41<31:59, 51.1kB/s]
42%|████▏ | 72.5M/170M [11:42<29:39, 55.1kB/s]
43%|████▎ | 72.5M/170M [11:42<31:09, 52.4kB/s]
43%|████▎ | 72.5M/170M [11:43<27:35, 59.2kB/s]
43%|████▎ | 72.5M/170M [11:43<23:15, 70.2kB/s]
43%|████▎ | 72.6M/170M [11:43<19:16, 84.7kB/s]
43%|████▎ | 72.6M/170M [11:43<16:29, 99.0kB/s]
43%|████▎ | 72.6M/170M [11:44<14:55, 109kB/s]
43%|████▎ | 72.7M/170M [11:44<13:30, 121kB/s]
43%|████▎ | 72.7M/170M [11:44<13:13, 123kB/s]
43%|████▎ | 72.7M/170M [11:44<12:31, 130kB/s]
43%|████▎ | 72.8M/170M [11:45<12:28, 131kB/s]
43%|████▎ | 72.8M/170M [11:45<11:26, 142kB/s]
43%|████▎ | 72.8M/170M [11:45<10:41, 152kB/s]
43%|████▎ | 72.9M/170M [11:45<10:32, 154kB/s]
43%|████▎ | 72.9M/170M [11:45<10:12, 159kB/s]
43%|████▎ | 72.9M/170M [11:46<11:06, 146kB/s]
43%|████▎ | 73.0M/170M [11:46<10:29, 155kB/s]
43%|████▎ | 73.0M/170M [11:46<10:35, 153kB/s]
43%|████▎ | 73.0M/170M [11:46<10:12, 159kB/s]
43%|████▎ | 73.1M/170M [11:47<10:55, 149kB/s]
43%|████▎ | 73.1M/170M [11:47<11:16, 144kB/s]
43%|████▎ | 73.1M/170M [11:47<10:34, 154kB/s]
43%|████▎ | 73.2M/170M [11:47<10:34, 153kB/s]
43%|████▎ | 73.2M/170M [11:47<11:17, 144kB/s]
43%|████▎ | 73.2M/170M [11:48<10:12, 159kB/s]
43%|████▎ | 73.3M/170M [11:48<10:22, 156kB/s]
43%|████▎ | 73.3M/170M [11:48<10:16, 158kB/s]
43%|████▎ | 73.3M/170M [11:48<10:33, 153kB/s]
43%|████▎ | 73.4M/170M [11:48<11:12, 144kB/s]
43%|████▎ | 73.4M/170M [11:49<11:28, 141kB/s]
43%|████▎ | 73.4M/170M [11:49<11:02, 146kB/s]
43%|████▎ | 73.5M/170M [11:49<10:40, 151kB/s]
43%|████▎ | 73.5M/170M [11:49<10:37, 152kB/s]
43%|████▎ | 73.5M/170M [11:50<11:20, 143kB/s]
43%|████▎ | 73.6M/170M [11:50<11:25, 141kB/s]
43%|████▎ | 73.6M/170M [11:50<11:07, 145kB/s]
43%|████▎ | 73.6M/170M [11:50<10:23, 155kB/s]
43%|████▎ | 73.7M/170M [11:50<10:36, 152kB/s]
43%|████▎ | 73.7M/170M [11:51<11:20, 142kB/s]
43%|████▎ | 73.7M/170M [11:51<11:34, 139kB/s]
43%|████▎ | 73.8M/170M [11:51<10:40, 151kB/s]
43%|████▎ | 73.8M/170M [11:51<11:13, 143kB/s]
43%|████▎ | 73.8M/170M [11:52<12:15, 131kB/s]
43%|████▎ | 73.9M/170M [11:52<11:09, 144kB/s]
43%|████▎ | 73.9M/170M [11:52<11:05, 145kB/s]
43%|████▎ | 73.9M/170M [11:52<10:16, 157kB/s]
43%|████▎ | 74.0M/170M [11:53<11:42, 137kB/s]
43%|████▎ | 74.0M/170M [11:53<11:19, 142kB/s]
43%|████▎ | 74.0M/170M [11:53<10:47, 149kB/s]
43%|████▎ | 74.1M/170M [11:53<10:33, 152kB/s]
43%|████▎ | 74.1M/170M [11:53<11:19, 142kB/s]
43%|████▎ | 74.1M/170M [11:54<10:59, 146kB/s]
43%|████▎ | 74.2M/170M [11:54<10:19, 156kB/s]
44%|████▎ | 74.2M/170M [11:54<10:27, 153kB/s]
44%|████▎ | 74.2M/170M [11:54<10:32, 152kB/s]
44%|████▎ | 74.3M/170M [11:54<09:50, 163kB/s]
44%|████▎ | 74.3M/170M [11:55<10:08, 158kB/s]
44%|████▎ | 74.3M/170M [11:55<10:41, 150kB/s]
44%|████▎ | 74.4M/170M [11:55<10:30, 153kB/s]
44%|████▎ | 74.4M/170M [11:55<10:31, 152kB/s]
44%|████▎ | 74.4M/170M [11:56<10:57, 146kB/s]
44%|████▎ | 74.4M/170M [11:56<10:41, 150kB/s]
44%|████▎ | 74.5M/170M [11:56<10:26, 153kB/s]
44%|████▎ | 74.5M/170M [11:56<10:34, 151kB/s]
44%|████▎ | 74.5M/170M [11:57<11:59, 133kB/s]
44%|████▎ | 74.6M/170M [11:57<13:43, 116kB/s]
44%|████▍ | 74.6M/170M [11:57<14:29, 110kB/s]
44%|████▍ | 74.6M/170M [11:58<15:34, 103kB/s]
44%|████▍ | 74.7M/170M [11:58<13:18, 120kB/s]
44%|████▍ | 74.7M/170M [11:58<12:14, 130kB/s]
44%|████▍ | 74.7M/170M [11:58<11:42, 136kB/s]
44%|████▍ | 74.8M/170M [11:58<11:30, 139kB/s]
44%|████▍ | 74.8M/170M [11:59<11:40, 137kB/s]
44%|████▍ | 74.8M/170M [11:59<10:52, 147kB/s]
44%|████▍ | 74.9M/170M [11:59<11:09, 143kB/s]
44%|████▍ | 74.9M/170M [11:59<10:50, 147kB/s]
44%|████▍ | 74.9M/170M [12:00<11:17, 141kB/s]
44%|████▍ | 75.0M/170M [12:00<11:25, 139kB/s]
44%|████▍ | 75.0M/170M [12:00<11:37, 137kB/s]
44%|████▍ | 75.0M/170M [12:00<11:17, 141kB/s]
44%|████▍ | 75.1M/170M [12:00<10:15, 155kB/s]
44%|████▍ | 75.1M/170M [12:01<11:13, 142kB/s]
44%|████▍ | 75.1M/170M [12:01<13:31, 118kB/s]
44%|████▍ | 75.2M/170M [12:02<15:48, 101kB/s]
44%|████▍ | 75.2M/170M [12:02<13:49, 115kB/s]
44%|████▍ | 75.2M/170M [12:02<13:14, 120kB/s]
44%|████▍ | 75.3M/170M [12:02<14:25, 110kB/s]
44%|████▍ | 75.3M/170M [12:03<14:04, 113kB/s]
44%|████▍ | 75.3M/170M [12:03<14:14, 111kB/s]
44%|████▍ | 75.4M/170M [12:03<12:47, 124kB/s]
44%|████▍ | 75.4M/170M [12:03<11:55, 133kB/s]
44%|████▍ | 75.4M/170M [12:04<13:40, 116kB/s]
44%|████▍ | 75.5M/170M [12:04<12:56, 122kB/s]
44%|████▍ | 75.5M/170M [12:04<12:06, 131kB/s]
44%|████▍ | 75.5M/170M [12:04<11:48, 134kB/s]
44%|████▍ | 75.6M/170M [12:05<11:38, 136kB/s]
44%|████▍ | 75.6M/170M [12:05<11:46, 134kB/s]
44%|████▍ | 75.6M/170M [12:05<11:29, 138kB/s]
44%|████▍ | 75.7M/170M [12:05<11:29, 138kB/s]
44%|████▍ | 75.7M/170M [12:06<11:46, 134kB/s]
44%|████▍ | 75.7M/170M [12:06<12:06, 130kB/s]
44%|████▍ | 75.8M/170M [12:06<12:19, 128kB/s]
44%|████▍ | 75.8M/170M [12:06<14:06, 112kB/s]
44%|████▍ | 75.8M/170M [12:07<14:02, 112kB/s]
44%|████▍ | 75.9M/170M [12:07<17:02, 92.5kB/s]
45%|████▍ | 75.9M/170M [12:08<16:39, 94.6kB/s]
45%|████▍ | 75.9M/170M [12:08<16:32, 95.3kB/s]
45%|████▍ | 76.0M/170M [12:08<15:18, 103kB/s]
45%|████▍ | 76.0M/170M [12:08<15:10, 104kB/s]
45%|████▍ | 76.0M/170M [12:09<14:44, 107kB/s]
45%|████▍ | 76.1M/170M [12:09<14:19, 110kB/s]
45%|████▍ | 76.1M/170M [12:09<13:35, 116kB/s]
45%|████▍ | 76.1M/170M [12:10<13:58, 113kB/s]
45%|████▍ | 76.2M/170M [12:10<13:54, 113kB/s]
45%|████▍ | 76.2M/170M [12:10<14:03, 112kB/s]
45%|████▍ | 76.2M/170M [12:10<14:13, 110kB/s]
45%|████▍ | 76.3M/170M [12:11<14:21, 109kB/s]
45%|████▍ | 76.3M/170M [12:11<16:31, 95.1kB/s]
45%|████▍ | 76.3M/170M [12:12<17:04, 91.9kB/s]
45%|████▍ | 76.3M/170M [12:12<16:10, 97.0kB/s]
45%|████▍ | 76.4M/170M [12:12<14:41, 107kB/s]
45%|████▍ | 76.4M/170M [12:12<13:34, 116kB/s]
45%|████▍ | 76.4M/170M [12:13<14:12, 110kB/s]
45%|████▍ | 76.5M/170M [12:13<16:00, 97.9kB/s]
45%|████▍ | 76.5M/170M [12:13<16:08, 97.0kB/s]
45%|████▍ | 76.5M/170M [12:15<27:58, 56.0kB/s]
45%|████▍ | 76.6M/170M [12:15<23:45, 65.9kB/s]
45%|████▍ | 76.6M/170M [12:15<19:54, 78.6kB/s]
45%|████▍ | 76.6M/170M [12:15<17:39, 88.6kB/s]
45%|████▍ | 76.7M/170M [12:16<16:19, 95.8kB/s]
45%|████▍ | 76.7M/170M [12:16<14:54, 105kB/s]
45%|████▌ | 76.7M/170M [12:16<14:43, 106kB/s]
45%|████▌ | 76.8M/170M [12:16<13:28, 116kB/s]
45%|████▌ | 76.8M/170M [12:17<15:12, 103kB/s]
45%|████▌ | 76.8M/170M [12:17<14:07, 110kB/s]
45%|████▌ | 76.9M/170M [12:17<14:05, 111kB/s]
45%|████▌ | 76.9M/170M [12:18<13:12, 118kB/s]
45%|████▌ | 76.9M/170M [12:18<13:20, 117kB/s]
45%|████▌ | 77.0M/170M [12:18<13:52, 112kB/s]
45%|████▌ | 77.0M/170M [12:18<12:29, 125kB/s]
45%|████▌ | 77.0M/170M [12:19<12:32, 124kB/s]
45%|████▌ | 77.1M/170M [12:19<12:54, 121kB/s]
45%|████▌ | 77.1M/170M [12:19<13:44, 113kB/s]
45%|████▌ | 77.1M/170M [12:20<12:40, 123kB/s]
45%|████▌ | 77.2M/170M [12:20<14:47, 105kB/s]
45%|████▌ | 77.2M/170M [12:20<14:59, 104kB/s]
45%|████▌ | 77.2M/170M [12:21<14:15, 109kB/s]
45%|████▌ | 77.3M/170M [12:21<13:44, 113kB/s]
45%|████▌ | 77.3M/170M [12:21<12:56, 120kB/s]
45%|████▌ | 77.3M/170M [12:21<12:31, 124kB/s]
45%|████▌ | 77.4M/170M [12:22<12:35, 123kB/s]
45%|████▌ | 77.4M/170M [12:22<11:47, 132kB/s]
45%|████▌ | 77.4M/170M [12:22<12:06, 128kB/s]
45%|████▌ | 77.5M/170M [12:22<11:17, 137kB/s]
45%|████▌ | 77.5M/170M [12:23<12:20, 126kB/s]
45%|████▌ | 77.5M/170M [12:23<12:14, 127kB/s]
45%|████▌ | 77.6M/170M [12:23<11:59, 129kB/s]
46%|████▌ | 77.6M/170M [12:23<11:54, 130kB/s]
46%|████▌ | 77.6M/170M [12:24<12:15, 126kB/s]
46%|████▌ | 77.7M/170M [12:24<11:07, 139kB/s]
46%|████▌ | 77.7M/170M [12:24<11:38, 133kB/s]
46%|████▌ | 77.7M/170M [12:24<11:53, 130kB/s]
46%|████▌ | 77.8M/170M [12:25<11:24, 136kB/s]
46%|████▌ | 77.8M/170M [12:25<11:36, 133kB/s]
46%|████▌ | 77.8M/170M [12:25<12:02, 128kB/s]
46%|████▌ | 77.9M/170M [12:25<12:02, 128kB/s]
46%|████▌ | 77.9M/170M [12:26<12:41, 122kB/s]
46%|████▌ | 77.9M/170M [12:26<12:11, 127kB/s]
46%|████▌ | 78.0M/170M [12:26<13:19, 116kB/s]
46%|████▌ | 78.0M/170M [12:26<13:30, 114kB/s]
46%|████▌ | 78.0M/170M [12:27<13:05, 118kB/s]
46%|████▌ | 78.1M/170M [12:27<12:16, 126kB/s]
46%|████▌ | 78.1M/170M [12:27<12:26, 124kB/s]
46%|████▌ | 78.1M/170M [12:27<12:24, 124kB/s]
46%|████▌ | 78.2M/170M [12:28<12:44, 121kB/s]
46%|████▌ | 78.2M/170M [12:28<13:35, 113kB/s]
46%|████▌ | 78.2M/170M [12:28<13:49, 111kB/s]
46%|████▌ | 78.2M/170M [12:29<13:26, 114kB/s]
46%|████▌ | 78.3M/170M [12:29<14:27, 106kB/s]
46%|████▌ | 78.3M/170M [12:29<16:00, 96.0kB/s]
46%|████▌ | 78.3M/170M [12:30<16:25, 93.5kB/s]
46%|████▌ | 78.4M/170M [12:30<15:44, 97.5kB/s]
46%|████▌ | 78.4M/170M [12:30<14:46, 104kB/s]
46%|████▌ | 78.4M/170M [12:31<13:54, 110kB/s]
46%|████▌ | 78.5M/170M [12:31<13:59, 110kB/s]
46%|████▌ | 78.5M/170M [12:31<14:08, 108kB/s]
46%|████▌ | 78.5M/170M [12:32<13:47, 111kB/s]
46%|████▌ | 78.6M/170M [12:32<13:04, 117kB/s]
46%|████▌ | 78.6M/170M [12:32<11:59, 128kB/s]
46%|████▌ | 78.6M/170M [12:32<12:59, 118kB/s]
46%|████▌ | 78.7M/170M [12:33<13:40, 112kB/s]
46%|████▌ | 78.7M/170M [12:33<13:08, 116kB/s]
46%|████▌ | 78.7M/170M [12:33<13:24, 114kB/s]
46%|████▌ | 78.8M/170M [12:33<12:03, 127kB/s]
46%|████▌ | 78.8M/170M [12:34<11:54, 128kB/s]
46%|████▌ | 78.8M/170M [12:34<11:40, 131kB/s]
46%|████▋ | 78.9M/170M [12:34<12:34, 121kB/s]
46%|████▋ | 78.9M/170M [12:34<12:05, 126kB/s]
46%|████▋ | 78.9M/170M [12:35<12:13, 125kB/s]
46%|████▋ | 79.0M/170M [12:35<12:21, 123kB/s]
46%|████▋ | 79.0M/170M [12:35<12:10, 125kB/s]
46%|████▋ | 79.0M/170M [12:35<12:11, 125kB/s]
46%|████▋ | 79.1M/170M [12:36<11:47, 129kB/s]
46%|████▋ | 79.1M/170M [12:36<11:51, 128kB/s]
46%|████▋ | 79.1M/170M [12:36<11:04, 137kB/s]
46%|████▋ | 79.2M/170M [12:36<11:27, 133kB/s]
46%|████▋ | 79.2M/170M [12:37<12:04, 126kB/s]
46%|████▋ | 79.2M/170M [12:37<12:10, 125kB/s]
46%|████▋ | 79.3M/170M [12:37<13:48, 110kB/s]
47%|████▋ | 79.3M/170M [12:38<13:50, 110kB/s]
47%|████▋ | 79.3M/170M [12:38<13:00, 117kB/s]
47%|████▋ | 79.4M/170M [12:38<12:35, 121kB/s]
47%|████▋ | 79.4M/170M [12:38<13:15, 115kB/s]
47%|████▋ | 79.4M/170M [12:39<13:04, 116kB/s]
47%|████▋ | 79.5M/170M [12:39<13:33, 112kB/s]
47%|████▋ | 79.5M/170M [12:39<13:27, 113kB/s]
47%|████▋ | 79.5M/170M [12:40<13:54, 109kB/s]
47%|████▋ | 79.6M/170M [12:40<14:09, 107kB/s]
47%|████▋ | 79.6M/170M [12:40<13:28, 112kB/s]
47%|████▋ | 79.6M/170M [12:40<11:56, 127kB/s]
47%|████▋ | 79.7M/170M [12:41<11:40, 130kB/s]
47%|████▋ | 79.7M/170M [12:41<11:10, 135kB/s]
47%|████▋ | 79.7M/170M [12:41<12:22, 122kB/s]
47%|████▋ | 79.8M/170M [12:41<11:56, 127kB/s]
47%|████▋ | 79.8M/170M [12:42<11:05, 136kB/s]
47%|████▋ | 79.8M/170M [12:42<11:16, 134kB/s]
47%|████▋ | 79.9M/170M [12:42<11:49, 128kB/s]
47%|████▋ | 79.9M/170M [12:43<12:49, 118kB/s]
47%|████▋ | 79.9M/170M [12:43<12:36, 120kB/s]
47%|████▋ | 80.0M/170M [12:43<12:33, 120kB/s]
47%|████▋ | 80.0M/170M [12:43<12:53, 117kB/s]
47%|████▋ | 80.0M/170M [12:44<12:06, 125kB/s]
47%|████▋ | 80.1M/170M [12:44<11:34, 130kB/s]
47%|████▋ | 80.1M/170M [12:44<13:26, 112kB/s]
47%|████▋ | 80.1M/170M [12:45<13:40, 110kB/s]
47%|████▋ | 80.2M/170M [12:45<13:47, 109kB/s]
47%|████▋ | 80.2M/170M [12:45<13:13, 114kB/s]
47%|████▋ | 80.2M/170M [12:45<13:36, 111kB/s]
47%|████▋ | 80.2M/170M [12:46<15:37, 96.3kB/s]
47%|████▋ | 80.3M/170M [12:46<14:29, 104kB/s]
47%|████▋ | 80.3M/170M [12:46<13:38, 110kB/s]
47%|████▋ | 80.3M/170M [12:47<12:49, 117kB/s]
47%|████▋ | 80.4M/170M [12:47<13:13, 114kB/s]
47%|████▋ | 80.4M/170M [12:47<12:32, 120kB/s]
47%|████▋ | 80.4M/170M [12:47<12:01, 125kB/s]
47%|████▋ | 80.5M/170M [12:48<11:29, 130kB/s]
47%|████▋ | 80.5M/170M [12:48<12:04, 124kB/s]
47%|████▋ | 80.5M/170M [12:48<11:42, 128kB/s]
47%|████▋ | 80.6M/170M [12:48<12:20, 121kB/s]
47%|████▋ | 80.6M/170M [12:49<12:17, 122kB/s]
47%|████▋ | 80.6M/170M [12:49<12:32, 119kB/s]
47%|████▋ | 80.7M/170M [12:50<16:42, 89.6kB/s]
47%|████▋ | 80.7M/170M [12:50<15:31, 96.4kB/s]
47%|████▋ | 80.7M/170M [12:50<14:42, 102kB/s]
47%|████▋ | 80.8M/170M [12:50<13:46, 109kB/s]
47%|████▋ | 80.8M/170M [12:51<15:06, 98.9kB/s]
47%|████▋ | 80.8M/170M [12:52<28:09, 53.1kB/s]
47%|████▋ | 80.9M/170M [12:53<26:18, 56.8kB/s]
47%|████▋ | 80.9M/170M [12:53<25:39, 58.2kB/s]
47%|████▋ | 80.9M/170M [12:53<23:15, 64.2kB/s]
47%|████▋ | 81.0M/170M [12:54<22:32, 66.2kB/s]
48%|████▊ | 81.0M/170M [12:54<20:53, 71.4kB/s]
48%|████▊ | 81.0M/170M [12:55<19:09, 77.8kB/s]
48%|████▊ | 81.1M/170M [12:55<18:52, 78.9kB/s]
48%|████▊ | 81.1M/170M [12:55<18:35, 80.1kB/s]
48%|████▊ | 81.1M/170M [12:56<24:07, 61.7kB/s]
48%|████▊ | 81.2M/170M [12:57<24:53, 59.8kB/s]
48%|████▊ | 81.2M/170M [12:57<22:30, 66.1kB/s]
48%|████▊ | 81.2M/170M [12:58<20:00, 74.3kB/s]
48%|████▊ | 81.3M/170M [12:58<23:23, 63.6kB/s]
48%|████▊ | 81.3M/170M [12:59<21:43, 68.4kB/s]
48%|████▊ | 81.3M/170M [12:59<19:30, 76.2kB/s]
48%|████▊ | 81.4M/170M [12:59<16:23, 90.6kB/s]
48%|████▊ | 81.4M/170M [12:59<15:27, 96.0kB/s]
48%|████▊ | 81.4M/170M [13:00<18:55, 78.5kB/s]
48%|████▊ | 81.5M/170M [13:01<21:15, 69.8kB/s]
48%|████▊ | 81.5M/170M [13:01<20:39, 71.8kB/s]
48%|████▊ | 81.5M/170M [13:01<18:16, 81.2kB/s]
48%|████▊ | 81.6M/170M [13:02<17:24, 85.1kB/s]
48%|████▊ | 81.6M/170M [13:02<19:59, 74.1kB/s]
48%|████▊ | 81.6M/170M [13:02<17:50, 83.0kB/s]
48%|████▊ | 81.7M/170M [13:03<15:27, 95.8kB/s]
48%|████▊ | 81.7M/170M [13:03<14:15, 104kB/s]
48%|████▊ | 81.7M/170M [13:03<12:52, 115kB/s]
48%|████▊ | 81.8M/170M [13:03<12:12, 121kB/s]
48%|████▊ | 81.8M/170M [13:04<11:35, 127kB/s]
48%|████▊ | 81.8M/170M [13:04<10:55, 135kB/s]
48%|████▊ | 81.9M/170M [13:04<10:29, 141kB/s]
48%|████▊ | 81.9M/170M [13:04<10:15, 144kB/s]
48%|████▊ | 81.9M/170M [13:05<10:32, 140kB/s]
48%|████▊ | 82.0M/170M [13:05<09:57, 148kB/s]
48%|████▊ | 82.0M/170M [13:05<11:09, 132kB/s]
48%|████▊ | 82.0M/170M [13:05<10:45, 137kB/s]
48%|████▊ | 82.1M/170M [13:05<10:22, 142kB/s]
48%|████▊ | 82.1M/170M [13:06<09:54, 149kB/s]
48%|████▊ | 82.1M/170M [13:06<09:25, 156kB/s]
48%|████▊ | 82.1M/170M [13:06<13:06, 112kB/s]
48%|████▊ | 82.2M/170M [13:07<11:47, 125kB/s]
48%|████▊ | 82.2M/170M [13:07<11:55, 123kB/s]
48%|████▊ | 82.2M/170M [13:07<11:19, 130kB/s]
48%|████▊ | 82.3M/170M [13:07<12:00, 122kB/s]
48%|████▊ | 82.3M/170M [13:08<10:57, 134kB/s]
48%|████▊ | 82.3M/170M [13:08<10:54, 135kB/s]
48%|████▊ | 82.4M/170M [13:08<10:35, 139kB/s]
48%|████▊ | 82.4M/170M [13:09<19:45, 74.3kB/s]
48%|████▊ | 82.4M/170M [13:09<21:38, 67.8kB/s]
48%|████▊ | 82.5M/170M [13:10<21:15, 69.0kB/s]
48%|████▊ | 82.5M/170M [13:11<24:22, 60.2kB/s]
48%|████▊ | 82.5M/170M [13:11<23:20, 62.8kB/s]
48%|████▊ | 82.6M/170M [13:11<19:08, 76.6kB/s]
48%|████▊ | 82.6M/170M [13:12<17:00, 86.1kB/s]
48%|████▊ | 82.6M/170M [13:12<15:07, 96.8kB/s]
48%|████▊ | 82.7M/170M [13:12<13:37, 107kB/s]
49%|████▊ | 82.7M/170M [13:12<12:55, 113kB/s]
49%|████▊ | 82.7M/170M [13:13<12:40, 115kB/s]
49%|████▊ | 82.8M/170M [13:13<11:49, 124kB/s]
49%|████▊ | 82.8M/170M [13:13<12:08, 120kB/s]
49%|████▊ | 82.8M/170M [13:13<12:05, 121kB/s]
49%|████▊ | 82.9M/170M [13:14<11:36, 126kB/s]
49%|████▊ | 82.9M/170M [13:14<11:16, 130kB/s]
49%|████▊ | 82.9M/170M [13:14<11:56, 122kB/s]
49%|████▊ | 83.0M/170M [13:15<18:18, 79.7kB/s]
49%|████▊ | 83.0M/170M [13:15<18:42, 78.0kB/s]
49%|████▊ | 83.0M/170M [13:16<21:09, 68.9kB/s]
49%|████▊ | 83.1M/170M [13:16<20:54, 69.7kB/s]
49%|████▊ | 83.1M/170M [13:17<20:15, 71.9kB/s]
49%|████▉ | 83.1M/170M [13:17<17:41, 82.3kB/s]
49%|████▉ | 83.2M/170M [13:17<16:06, 90.3kB/s]
49%|████▉ | 83.2M/170M [13:18<14:19, 102kB/s]
49%|████▉ | 83.2M/170M [13:18<13:44, 106kB/s]
49%|████▉ | 83.3M/170M [13:18<13:04, 111kB/s]
49%|████▉ | 83.3M/170M [13:19<14:55, 97.4kB/s]
49%|████▉ | 83.3M/170M [13:19<14:35, 99.6kB/s]
49%|████▉ | 83.4M/170M [13:19<13:19, 109kB/s]
49%|████▉ | 83.4M/170M [13:19<13:23, 108kB/s]
49%|████▉ | 83.4M/170M [13:20<12:47, 113kB/s]
49%|████▉ | 83.5M/170M [13:20<12:47, 113kB/s]
49%|████▉ | 83.5M/170M [13:20<13:25, 108kB/s]
49%|████▉ | 83.5M/170M [13:21<14:30, 99.9kB/s]
49%|████▉ | 83.6M/170M [13:21<12:39, 114kB/s]
49%|████▉ | 83.6M/170M [13:21<14:47, 97.9kB/s]
49%|████▉ | 83.6M/170M [13:22<16:43, 86.5kB/s]
49%|████▉ | 83.7M/170M [13:22<16:06, 89.9kB/s]
49%|████▉ | 83.7M/170M [13:22<16:17, 88.8kB/s]
49%|████▉ | 83.7M/170M [13:23<16:32, 87.4kB/s]
49%|████▉ | 83.8M/170M [13:23<16:36, 87.0kB/s]
49%|████▉ | 83.8M/170M [13:24<17:15, 83.7kB/s]
49%|████▉ | 83.8M/170M [13:24<16:39, 86.8kB/s]
49%|████▉ | 83.9M/170M [13:24<15:12, 95.0kB/s]
49%|████▉ | 83.9M/170M [13:25<15:17, 94.3kB/s]
49%|████▉ | 83.9M/170M [13:25<15:22, 93.8kB/s]
49%|████▉ | 84.0M/170M [13:25<15:45, 91.5kB/s]
49%|████▉ | 84.0M/170M [13:26<17:51, 80.7kB/s]
49%|████▉ | 84.0M/170M [13:26<16:55, 85.1kB/s]
49%|████▉ | 84.0M/170M [13:27<16:31, 87.2kB/s]
49%|████▉ | 84.1M/170M [13:27<17:34, 82.0kB/s]
49%|████▉ | 84.1M/170M [13:27<16:31, 87.1kB/s]
49%|████▉ | 84.1M/170M [13:28<15:55, 90.3kB/s]
49%|████▉ | 84.2M/170M [13:28<15:05, 95.3kB/s]
49%|████▉ | 84.2M/170M [13:28<15:26, 93.1kB/s]
49%|████▉ | 84.2M/170M [13:29<14:21, 100kB/s]
49%|████▉ | 84.3M/170M [13:29<13:29, 106kB/s]
49%|████▉ | 84.3M/170M [13:29<14:53, 96.4kB/s]
49%|████▉ | 84.3M/170M [13:30<15:15, 94.1kB/s]
49%|████▉ | 84.4M/170M [13:30<15:23, 93.3kB/s]
50%|████▉ | 84.4M/170M [13:30<15:09, 94.7kB/s]
50%|████▉ | 84.4M/170M [13:31<13:41, 105kB/s]
50%|████▉ | 84.5M/170M [13:31<12:48, 112kB/s]
50%|████▉ | 84.5M/170M [13:31<12:25, 115kB/s]
50%|████▉ | 84.5M/170M [13:32<14:10, 101kB/s]
50%|████▉ | 84.6M/170M [13:32<20:02, 71.4kB/s]
50%|████▉ | 84.6M/170M [13:33<18:47, 76.2kB/s]
50%|████▉ | 84.6M/170M [13:33<20:37, 69.4kB/s]
50%|████▉ | 84.7M/170M [13:34<19:35, 73.0kB/s]
50%|████▉ | 84.7M/170M [13:34<18:24, 77.7kB/s]
50%|████▉ | 84.7M/170M [13:34<18:17, 78.2kB/s]
50%|████▉ | 84.8M/170M [13:35<19:42, 72.5kB/s]
50%|████▉ | 84.8M/170M [13:36<21:05, 67.7kB/s]
50%|████▉ | 84.8M/170M [13:36<25:57, 55.0kB/s]
50%|████▉ | 84.9M/170M [13:37<28:16, 50.5kB/s]
50%|████▉ | 84.9M/170M [13:38<27:17, 52.3kB/s]
50%|████▉ | 84.9M/170M [13:38<23:21, 61.0kB/s]
50%|████▉ | 85.0M/170M [13:38<20:49, 68.5kB/s]
50%|████▉ | 85.0M/170M [13:39<19:24, 73.4kB/s]
50%|████▉ | 85.0M/170M [13:39<17:03, 83.5kB/s]
50%|████▉ | 85.1M/170M [13:39<16:54, 84.2kB/s]
50%|████▉ | 85.1M/170M [13:40<18:49, 75.6kB/s]
50%|████▉ | 85.1M/170M [13:40<18:37, 76.4kB/s]
50%|████▉ | 85.2M/170M [13:41<16:04, 88.5kB/s]
50%|████▉ | 85.2M/170M [13:41<16:33, 85.8kB/s]
50%|████▉ | 85.2M/170M [13:41<16:41, 85.2kB/s]
50%|█████ | 85.3M/170M [13:42<16:04, 88.4kB/s]
50%|█████ | 85.3M/170M [13:42<15:20, 92.6kB/s]
50%|█████ | 85.3M/170M [13:42<16:05, 88.2kB/s]
50%|█████ | 85.4M/170M [13:43<17:20, 81.8kB/s]
50%|█████ | 85.4M/170M [13:43<16:18, 86.9kB/s]
50%|█████ | 85.4M/170M [13:44<15:55, 89.0kB/s]
50%|█████ | 85.5M/170M [13:44<15:07, 93.7kB/s]
50%|█████ | 85.5M/170M [13:44<16:22, 86.5kB/s]
50%|█████ | 85.5M/170M [13:45<16:44, 84.6kB/s]
50%|█████ | 85.6M/170M [13:45<17:06, 82.8kB/s]
50%|█████ | 85.6M/170M [13:45<15:16, 92.7kB/s]
50%|█████ | 85.6M/170M [13:46<15:17, 92.5kB/s]
50%|█████ | 85.7M/170M [13:46<17:32, 80.6kB/s]
50%|█████ | 85.7M/170M [13:47<16:33, 85.4kB/s]
50%|█████ | 85.7M/170M [13:47<14:52, 94.9kB/s]
50%|█████ | 85.8M/170M [13:47<13:41, 103kB/s]
50%|█████ | 85.8M/170M [13:47<13:50, 102kB/s]
50%|█████ | 85.8M/170M [13:48<13:43, 103kB/s]
50%|█████ | 85.9M/170M [13:48<12:37, 112kB/s]
50%|█████ | 85.9M/170M [13:48<12:38, 111kB/s]
50%|█████ | 85.9M/170M [13:49<13:00, 108kB/s]
50%|█████ | 86.0M/170M [13:49<13:16, 106kB/s]
50%|█████ | 86.0M/170M [13:49<14:52, 94.6kB/s]
50%|█████ | 86.0M/170M [13:50<16:13, 86.8kB/s]
50%|█████ | 86.0M/170M [13:50<14:48, 95.1kB/s]
50%|█████ | 86.1M/170M [13:50<14:25, 97.6kB/s]
51%|█████ | 86.1M/170M [13:51<16:15, 86.5kB/s]
51%|█████ | 86.1M/170M [13:51<18:06, 77.7kB/s]
51%|█████ | 86.2M/170M [13:52<17:47, 79.0kB/s]
51%|█████ | 86.2M/170M [13:52<16:52, 83.2kB/s]
51%|█████ | 86.2M/170M [13:53<16:36, 84.5kB/s]
51%|█████ | 86.3M/170M [13:53<19:16, 72.8kB/s]
51%|█████ | 86.3M/170M [13:54<20:19, 69.1kB/s]
51%|█████ | 86.3M/170M [13:54<19:14, 72.9kB/s]
51%|█████ | 86.4M/170M [13:54<18:52, 74.3kB/s]
51%|█████ | 86.4M/170M [13:55<16:52, 83.0kB/s]
51%|█████ | 86.4M/170M [13:55<16:02, 87.3kB/s]
51%|█████ | 86.5M/170M [13:55<14:28, 96.7kB/s]
51%|█████ | 86.5M/170M [13:56<14:29, 96.6kB/s]
51%|█████ | 86.5M/170M [13:56<14:04, 99.4kB/s]
51%|█████ | 86.6M/170M [13:56<14:06, 99.2kB/s]
51%|█████ | 86.6M/170M [13:57<13:08, 106kB/s]
51%|█████ | 86.6M/170M [13:57<12:29, 112kB/s]
51%|█████ | 86.7M/170M [13:57<12:53, 108kB/s]
51%|█████ | 86.7M/170M [13:58<13:39, 102kB/s]
51%|█████ | 86.7M/170M [13:58<13:11, 106kB/s]
51%|█████ | 86.8M/170M [13:58<14:26, 96.6kB/s]
51%|█████ | 86.8M/170M [13:59<17:16, 80.8kB/s]
51%|█████ | 86.8M/170M [13:59<15:33, 89.6kB/s]
51%|█████ | 86.9M/170M [14:00<18:21, 75.9kB/s]
51%|█████ | 86.9M/170M [14:00<17:56, 77.7kB/s]
51%|█████ | 86.9M/170M [14:01<18:21, 75.8kB/s]
51%|█████ | 87.0M/170M [14:01<17:02, 81.7kB/s]
51%|█████ | 87.0M/170M [14:01<18:30, 75.2kB/s]
51%|█████ | 87.0M/170M [14:02<18:23, 75.6kB/s]
51%|█████ | 87.1M/170M [14:02<16:22, 84.9kB/s]
51%|█████ | 87.1M/170M [14:02<14:11, 98.0kB/s]
51%|█████ | 87.1M/170M [14:02<12:40, 110kB/s]
51%|█████ | 87.2M/170M [14:03<11:29, 121kB/s]
51%|█████ | 87.2M/170M [14:03<10:48, 128kB/s]
51%|█████ | 87.2M/170M [14:03<10:17, 135kB/s]
51%|█████ | 87.3M/170M [14:03<09:32, 146kB/s]
51%|█████ | 87.3M/170M [14:04<09:13, 150kB/s]
51%|█████ | 87.3M/170M [14:04<09:34, 145kB/s]
51%|█████ | 87.4M/170M [14:04<09:08, 152kB/s]
51%|█████▏ | 87.4M/170M [14:04<09:36, 144kB/s]
51%|█████▏ | 87.4M/170M [14:04<09:53, 140kB/s]
51%|█████▏ | 87.5M/170M [14:05<09:44, 142kB/s]
51%|█████▏ | 87.5M/170M [14:05<09:48, 141kB/s]
51%|█████▏ | 87.5M/170M [14:05<09:10, 151kB/s]
51%|█████▏ | 87.6M/170M [14:05<09:13, 150kB/s]
51%|█████▏ | 87.6M/170M [14:06<09:13, 150kB/s]
51%|█████▏ | 87.6M/170M [14:06<08:41, 159kB/s]
51%|█████▏ | 87.7M/170M [14:06<09:06, 151kB/s]
51%|█████▏ | 87.7M/170M [14:06<09:22, 147kB/s]
51%|█████▏ | 87.7M/170M [14:06<10:06, 136kB/s]
51%|█████▏ | 87.8M/170M [14:07<09:23, 147kB/s]
51%|█████▏ | 87.8M/170M [14:07<09:34, 144kB/s]
52%|█████▏ | 87.8M/170M [14:07<09:23, 147kB/s]
52%|█████▏ | 87.9M/170M [14:07<08:47, 157kB/s]
52%|█████▏ | 87.9M/170M [14:08<10:36, 130kB/s]
52%|█████▏ | 87.9M/170M [14:08<10:10, 135kB/s]
52%|█████▏ | 87.9M/170M [14:08<09:20, 147kB/s]
52%|█████▏ | 88.0M/170M [14:08<09:18, 148kB/s]
52%|█████▏ | 88.0M/170M [14:08<09:04, 151kB/s]
52%|█████▏ | 88.0M/170M [14:09<09:05, 151kB/s]
52%|█████▏ | 88.1M/170M [14:09<09:59, 138kB/s]
52%|█████▏ | 88.1M/170M [14:09<09:48, 140kB/s]
52%|█████▏ | 88.1M/170M [14:09<09:14, 149kB/s]
52%|█████▏ | 88.2M/170M [14:10<09:21, 147kB/s]
52%|█████▏ | 88.2M/170M [14:10<09:24, 146kB/s]
52%|█████▏ | 88.2M/170M [14:10<08:59, 153kB/s]
52%|█████▏ | 88.3M/170M [14:10<08:56, 153kB/s]
52%|█████▏ | 88.3M/170M [14:10<08:46, 156kB/s]
52%|█████▏ | 88.3M/170M [14:11<08:57, 153kB/s]
52%|█████▏ | 88.4M/170M [14:11<09:21, 146kB/s]
52%|█████▏ | 88.4M/170M [14:11<10:47, 127kB/s]
52%|█████▏ | 88.4M/170M [14:11<10:30, 130kB/s]
52%|█████▏ | 88.5M/170M [14:12<11:55, 115kB/s]
52%|█████▏ | 88.5M/170M [14:12<11:21, 120kB/s]
52%|█████▏ | 88.5M/170M [14:12<10:54, 125kB/s]
52%|█████▏ | 88.6M/170M [14:13<10:15, 133kB/s]
52%|█████▏ | 88.6M/170M [14:13<10:51, 126kB/s]
52%|█████▏ | 88.6M/170M [14:13<11:16, 121kB/s]
52%|█████▏ | 88.7M/170M [14:13<11:56, 114kB/s]
52%|█████▏ | 88.7M/170M [14:14<11:24, 120kB/s]
52%|█████▏ | 88.7M/170M [14:14<10:48, 126kB/s]
52%|█████▏ | 88.8M/170M [14:14<11:09, 122kB/s]
52%|█████▏ | 88.8M/170M [14:14<10:41, 127kB/s]
52%|█████▏ | 88.8M/170M [14:15<09:57, 137kB/s]
52%|█████▏ | 88.9M/170M [14:15<10:13, 133kB/s]
52%|█████▏ | 88.9M/170M [14:15<09:40, 141kB/s]
52%|█████▏ | 88.9M/170M [14:15<09:38, 141kB/s]
52%|█████▏ | 89.0M/170M [14:16<09:33, 142kB/s]
52%|█████▏ | 89.0M/170M [14:16<09:42, 140kB/s]
52%|█████▏ | 89.0M/170M [14:16<09:49, 138kB/s]
52%|█████▏ | 89.1M/170M [14:16<09:38, 141kB/s]
52%|█████▏ | 89.1M/170M [14:17<10:49, 125kB/s]
52%|█████▏ | 89.1M/170M [14:17<09:50, 138kB/s]
52%|█████▏ | 89.2M/170M [14:17<09:22, 145kB/s]
52%|█████▏ | 89.2M/170M [14:17<09:09, 148kB/s]
52%|█████▏ | 89.2M/170M [14:17<09:00, 150kB/s]
52%|█████▏ | 89.3M/170M [14:18<09:26, 143kB/s]
52%|█████▏ | 89.3M/170M [14:18<09:22, 144kB/s]
52%|█████▏ | 89.3M/170M [14:18<09:59, 135kB/s]
52%|█████▏ | 89.4M/170M [14:19<15:45, 85.8kB/s]
52%|█████▏ | 89.4M/170M [14:19<13:35, 99.4kB/s]
52%|█████▏ | 89.4M/170M [14:19<12:14, 110kB/s]
52%|█████▏ | 89.5M/170M [14:20<12:22, 109kB/s]
52%|█████▏ | 89.5M/170M [14:20<10:56, 123kB/s]
53%|█████▎ | 89.5M/170M [14:20<10:51, 124kB/s]
53%|█████▎ | 89.6M/170M [14:20<10:12, 132kB/s]
53%|█████▎ | 89.6M/170M [14:20<09:36, 140kB/s]
53%|█████▎ | 89.6M/170M [14:21<09:45, 138kB/s]
53%|█████▎ | 89.7M/170M [14:21<09:37, 140kB/s]
53%|█████▎ | 89.7M/170M [14:21<09:12, 146kB/s]
53%|█████▎ | 89.7M/170M [14:21<09:09, 147kB/s]
53%|█████▎ | 89.8M/170M [14:22<09:10, 147kB/s]
53%|█████▎ | 89.8M/170M [14:22<09:16, 145kB/s]
53%|█████▎ | 89.8M/170M [14:22<09:11, 146kB/s]
53%|█████▎ | 89.8M/170M [14:22<08:39, 155kB/s]
53%|█████▎ | 89.9M/170M [14:22<08:40, 155kB/s]
53%|█████▎ | 89.9M/170M [14:23<09:06, 147kB/s]
53%|█████▎ | 89.9M/170M [14:23<08:22, 160kB/s]
53%|█████▎ | 90.0M/170M [14:23<08:21, 161kB/s]
53%|█████▎ | 90.0M/170M [14:23<08:17, 162kB/s]
53%|█████▎ | 90.0M/170M [14:23<08:34, 156kB/s]
53%|█████▎ | 90.1M/170M [14:24<08:31, 157kB/s]
53%|█████▎ | 90.1M/170M [14:24<08:58, 149kB/s]
53%|█████▎ | 90.1M/170M [14:24<09:09, 146kB/s]
53%|█████▎ | 90.2M/170M [14:24<08:57, 149kB/s]
53%|█████▎ | 90.2M/170M [14:25<09:13, 145kB/s]
53%|█████▎ | 90.2M/170M [14:25<09:12, 145kB/s]
53%|█████▎ | 90.3M/170M [14:25<09:12, 145kB/s]
53%|█████▎ | 90.3M/170M [14:25<08:54, 150kB/s]
53%|█████▎ | 90.3M/170M [14:25<08:35, 155kB/s]
53%|█████▎ | 90.4M/170M [14:26<08:53, 150kB/s]
53%|█████▎ | 90.4M/170M [14:26<08:50, 151kB/s]
53%|█████▎ | 90.4M/170M [14:26<08:47, 152kB/s]
53%|█████▎ | 90.5M/170M [14:26<09:19, 143kB/s]
53%|█████▎ | 90.5M/170M [14:27<09:26, 141kB/s]
53%|█████▎ | 90.5M/170M [14:27<08:44, 152kB/s]
53%|█████▎ | 90.6M/170M [14:27<09:02, 147kB/s]
53%|█████▎ | 90.6M/170M [14:27<08:20, 160kB/s]
53%|█████▎ | 90.6M/170M [14:27<08:24, 158kB/s]
53%|█████▎ | 90.7M/170M [14:28<08:35, 155kB/s]
53%|█████▎ | 90.7M/170M [14:28<08:34, 155kB/s]
53%|█████▎ | 90.7M/170M [14:28<08:25, 158kB/s]
53%|█████▎ | 90.8M/170M [14:28<08:34, 155kB/s]
53%|█████▎ | 90.8M/170M [14:29<10:12, 130kB/s]
53%|█████▎ | 90.8M/170M [14:29<10:10, 130kB/s]
53%|█████▎ | 90.9M/170M [14:29<09:53, 134kB/s]
53%|█████▎ | 90.9M/170M [14:29<09:59, 133kB/s]
53%|█████▎ | 90.9M/170M [14:30<10:02, 132kB/s]
53%|█████▎ | 91.0M/170M [14:30<11:58, 111kB/s]
53%|█████▎ | 91.0M/170M [14:30<14:15, 92.9kB/s]
53%|█████▎ | 91.0M/170M [14:31<15:39, 84.5kB/s]
53%|█████▎ | 91.1M/170M [14:31<14:45, 89.7kB/s]
53%|█████▎ | 91.1M/170M [14:32<14:43, 89.9kB/s]
53%|█████▎ | 91.1M/170M [14:32<19:37, 67.4kB/s]
53%|█████▎ | 91.2M/170M [14:33<23:36, 56.0kB/s]
53%|█████▎ | 91.2M/170M [14:34<22:15, 59.4kB/s]
54%|█████▎ | 91.2M/170M [14:34<22:18, 59.2kB/s]
54%|█████▎ | 91.3M/170M [14:35<23:08, 57.1kB/s]
54%|█████▎ | 91.3M/170M [14:35<22:19, 59.1kB/s]
54%|█████▎ | 91.3M/170M [14:36<19:54, 66.3kB/s]
54%|█████▎ | 91.4M/170M [14:36<16:19, 80.8kB/s]
54%|█████▎ | 91.4M/170M [14:36<14:22, 91.7kB/s]
54%|█████▎ | 91.4M/170M [14:36<12:40, 104kB/s]
54%|█████▎ | 91.5M/170M [14:37<12:05, 109kB/s]
54%|█████▎ | 91.5M/170M [14:37<11:48, 112kB/s]
54%|█████▎ | 91.5M/170M [14:37<12:32, 105kB/s]
54%|█████▎ | 91.6M/170M [14:38<12:28, 106kB/s]
54%|█████▎ | 91.6M/170M [14:38<11:17, 116kB/s]
54%|█████▎ | 91.6M/170M [14:38<11:46, 112kB/s]
54%|█████▍ | 91.7M/170M [14:38<09:59, 131kB/s]
54%|█████▍ | 91.7M/170M [14:38<09:26, 139kB/s]
54%|█████▍ | 91.7M/170M [14:39<09:32, 138kB/s]
54%|█████▍ | 91.8M/170M [14:39<12:02, 109kB/s]
54%|█████▍ | 91.8M/170M [14:39<11:04, 119kB/s]
54%|█████▍ | 91.8M/170M [14:40<10:59, 119kB/s]
54%|█████▍ | 91.8M/170M [14:40<10:06, 130kB/s]
54%|█████▍ | 91.9M/170M [14:40<09:52, 133kB/s]
54%|█████▍ | 91.9M/170M [14:40<09:22, 140kB/s]
54%|█████▍ | 91.9M/170M [14:40<08:50, 148kB/s]
54%|█████▍ | 92.0M/170M [14:41<09:14, 142kB/s]
54%|█████▍ | 92.0M/170M [14:41<08:44, 150kB/s]
54%|█████▍ | 92.0M/170M [14:41<08:47, 149kB/s]
54%|█████▍ | 92.1M/170M [14:41<08:05, 162kB/s]
54%|█████▍ | 92.1M/170M [14:42<08:14, 159kB/s]
54%|█████▍ | 92.1M/170M [14:42<08:13, 159kB/s]
54%|█████▍ | 92.2M/170M [14:42<09:38, 135kB/s]
54%|█████▍ | 92.2M/170M [14:42<08:17, 157kB/s]
54%|█████▍ | 92.2M/170M [14:42<08:10, 159kB/s]
54%|█████▍ | 92.3M/170M [14:43<08:23, 155kB/s]
54%|█████▍ | 92.3M/170M [14:43<08:29, 153kB/s]
54%|█████▍ | 92.3M/170M [14:43<08:33, 152kB/s]
54%|█████▍ | 92.4M/170M [14:43<08:28, 154kB/s]
54%|█████▍ | 92.4M/170M [14:43<08:03, 161kB/s]
54%|█████▍ | 92.4M/170M [14:44<08:21, 156kB/s]
54%|█████▍ | 92.5M/170M [14:44<08:48, 148kB/s]
54%|█████▍ | 92.5M/170M [14:44<08:29, 153kB/s]
54%|█████▍ | 92.5M/170M [14:44<08:40, 150kB/s]
54%|█████▍ | 92.6M/170M [14:45<08:35, 151kB/s]
54%|█████▍ | 92.6M/170M [14:45<08:23, 155kB/s]
54%|█████▍ | 92.6M/170M [14:45<08:27, 153kB/s]
54%|█████▍ | 92.7M/170M [14:45<08:30, 152kB/s]
54%|█████▍ | 92.7M/170M [14:45<08:19, 156kB/s]
54%|█████▍ | 92.7M/170M [14:46<08:18, 156kB/s]
54%|█████▍ | 92.8M/170M [14:46<08:47, 147kB/s]
54%|█████▍ | 92.8M/170M [14:46<08:27, 153kB/s]
54%|█████▍ | 92.8M/170M [14:46<08:40, 149kB/s]
54%|█████▍ | 92.9M/170M [14:47<09:43, 133kB/s]
54%|█████▍ | 92.9M/170M [14:47<09:20, 139kB/s]
55%|█████▍ | 92.9M/170M [14:47<08:55, 145kB/s]
55%|█████▍ | 93.0M/170M [14:47<08:39, 149kB/s]
55%|█████▍ | 93.0M/170M [14:47<08:32, 151kB/s]
55%|█████▍ | 93.0M/170M [14:48<08:23, 154kB/s]
55%|█████▍ | 93.1M/170M [14:48<08:47, 147kB/s]
55%|█████▍ | 93.1M/170M [14:48<08:20, 155kB/s]
55%|█████▍ | 93.1M/170M [14:48<08:17, 156kB/s]
55%|█████▍ | 93.2M/170M [14:48<08:26, 153kB/s]
55%|█████▍ | 93.2M/170M [14:49<09:12, 140kB/s]
55%|█████▍ | 93.2M/170M [14:49<09:41, 133kB/s]
55%|█████▍ | 93.3M/170M [14:49<09:07, 141kB/s]
55%|█████▍ | 93.3M/170M [14:49<08:56, 144kB/s]
55%|█████▍ | 93.3M/170M [14:50<08:21, 154kB/s]
55%|█████▍ | 93.4M/170M [14:50<08:36, 149kB/s]
55%|█████▍ | 93.4M/170M [14:50<08:55, 144kB/s]
55%|█████▍ | 93.4M/170M [14:50<08:49, 146kB/s]
55%|█████▍ | 93.5M/170M [14:50<08:16, 155kB/s]
55%|█████▍ | 93.5M/170M [14:51<08:50, 145kB/s]
55%|█████▍ | 93.5M/170M [14:51<08:33, 150kB/s]
55%|█████▍ | 93.6M/170M [14:51<09:05, 141kB/s]
55%|█████▍ | 93.6M/170M [14:51<08:49, 145kB/s]
55%|█████▍ | 93.6M/170M [14:52<09:08, 140kB/s]
55%|█████▍ | 93.7M/170M [14:52<08:49, 145kB/s]
55%|█████▍ | 93.7M/170M [14:52<08:42, 147kB/s]
55%|█████▍ | 93.7M/170M [14:52<08:23, 153kB/s]
55%|█████▍ | 93.7M/170M [14:53<08:30, 150kB/s]
55%|█████▌ | 93.8M/170M [14:53<08:43, 147kB/s]
55%|█████▌ | 93.8M/170M [14:53<08:43, 147kB/s]
55%|█████▌ | 93.8M/170M [14:53<08:23, 152kB/s]
55%|█████▌ | 93.9M/170M [14:53<08:49, 145kB/s]
55%|█████▌ | 93.9M/170M [14:54<08:34, 149kB/s]
55%|█████▌ | 93.9M/170M [14:54<08:50, 144kB/s]
55%|█████▌ | 94.0M/170M [14:54<08:03, 158kB/s]
55%|█████▌ | 94.0M/170M [14:54<08:22, 152kB/s]
55%|█████▌ | 94.0M/170M [14:54<08:17, 154kB/s]
55%|█████▌ | 94.1M/170M [14:55<08:24, 152kB/s]
55%|█████▌ | 94.1M/170M [14:55<08:08, 156kB/s]
55%|█████▌ | 94.1M/170M [14:55<08:26, 151kB/s]
55%|█████▌ | 94.2M/170M [14:55<08:31, 149kB/s]
55%|█████▌ | 94.2M/170M [14:56<09:12, 138kB/s]
55%|█████▌ | 94.2M/170M [14:56<08:43, 146kB/s]
55%|█████▌ | 94.3M/170M [14:56<08:38, 147kB/s]
55%|█████▌ | 94.3M/170M [14:56<08:15, 154kB/s]
55%|█████▌ | 94.3M/170M [14:57<08:48, 144kB/s]
55%|█████▌ | 94.4M/170M [14:57<08:44, 145kB/s]
55%|█████▌ | 94.4M/170M [14:57<08:42, 146kB/s]
55%|█████▌ | 94.4M/170M [14:57<08:39, 146kB/s]
55%|█████▌ | 94.5M/170M [14:57<08:49, 144kB/s]
55%|█████▌ | 94.5M/170M [14:58<07:59, 159kB/s]
55%|█████▌ | 94.5M/170M [14:58<07:41, 165kB/s]
55%|█████▌ | 94.6M/170M [14:58<08:39, 146kB/s]
55%|█████▌ | 94.6M/170M [14:58<08:38, 146kB/s]
56%|█████▌ | 94.6M/170M [14:58<08:01, 158kB/s]
56%|█████▌ | 94.7M/170M [14:59<08:01, 157kB/s]
56%|█████▌ | 94.7M/170M [14:59<07:49, 162kB/s]
56%|█████▌ | 94.7M/170M [14:59<08:00, 158kB/s]
56%|█████▌ | 94.8M/170M [14:59<08:19, 151kB/s]
56%|█████▌ | 94.8M/170M [15:00<08:32, 148kB/s]
56%|█████▌ | 94.8M/170M [15:00<08:47, 143kB/s]
56%|█████▌ | 94.9M/170M [15:00<08:32, 148kB/s]
56%|█████▌ | 94.9M/170M [15:00<08:49, 143kB/s]
56%|█████▌ | 94.9M/170M [15:00<08:29, 148kB/s]
56%|█████▌ | 95.0M/170M [15:01<08:22, 150kB/s]
56%|█████▌ | 95.0M/170M [15:01<07:56, 158kB/s]
56%|█████▌ | 95.0M/170M [15:01<08:07, 155kB/s]
56%|█████▌ | 95.1M/170M [15:01<08:10, 154kB/s]
56%|█████▌ | 95.1M/170M [15:01<08:15, 152kB/s]
56%|█████▌ | 95.1M/170M [15:02<08:28, 148kB/s]
56%|█████▌ | 95.2M/170M [15:02<08:38, 145kB/s]
56%|█████▌ | 95.2M/170M [15:02<08:41, 144kB/s]
56%|█████▌ | 95.2M/170M [15:02<08:48, 142kB/s]
56%|█████▌ | 95.3M/170M [15:03<09:53, 127kB/s]
56%|█████▌ | 95.3M/170M [15:03<09:47, 128kB/s]
56%|█████▌ | 95.3M/170M [15:03<09:43, 129kB/s]
56%|█████▌ | 95.4M/170M [15:04<10:02, 125kB/s]
56%|█████▌ | 95.4M/170M [15:04<09:53, 127kB/s]
56%|█████▌ | 95.4M/170M [15:04<09:39, 130kB/s]
56%|█████▌ | 95.5M/170M [15:04<09:17, 135kB/s]
56%|█████▌ | 95.5M/170M [15:04<09:09, 137kB/s]
56%|█████▌ | 95.5M/170M [15:05<08:23, 149kB/s]
56%|█████▌ | 95.6M/170M [15:05<08:43, 143kB/s]
56%|█████▌ | 95.6M/170M [15:05<09:33, 131kB/s]
56%|█████▌ | 95.6M/170M [15:05<08:59, 139kB/s]
56%|█████▌ | 95.6M/170M [15:06<08:57, 139kB/s]
56%|█████▌ | 95.7M/170M [15:06<08:45, 142kB/s]
56%|█████▌ | 95.7M/170M [15:06<09:52, 126kB/s]
56%|█████▌ | 95.7M/170M [15:06<10:40, 117kB/s]
56%|█████▌ | 95.8M/170M [15:07<10:45, 116kB/s]
56%|█████▌ | 95.8M/170M [15:07<09:55, 125kB/s]
56%|█████▌ | 95.8M/170M [15:07<10:39, 117kB/s]
56%|█████▌ | 95.9M/170M [15:08<10:55, 114kB/s]
56%|█████▋ | 95.9M/170M [15:08<12:52, 96.6kB/s]
56%|█████▋ | 95.9M/170M [15:08<12:09, 102kB/s]
56%|█████▋ | 96.0M/170M [15:09<12:15, 101kB/s]
56%|█████▋ | 96.0M/170M [15:09<12:00, 103kB/s]
56%|█████▋ | 96.0M/170M [15:09<13:43, 90.4kB/s]
56%|█████▋ | 96.1M/170M [15:10<12:47, 96.9kB/s]
56%|█████▋ | 96.1M/170M [15:10<12:13, 101kB/s]
56%|█████▋ | 96.1M/170M [15:10<13:26, 92.2kB/s]
56%|█████▋ | 96.2M/170M [15:11<12:37, 98.1kB/s]
56%|█████▋ | 96.2M/170M [15:11<12:22, 100kB/s]
56%|█████▋ | 96.2M/170M [15:11<12:27, 99.3kB/s]
56%|█████▋ | 96.3M/170M [15:12<14:28, 85.4kB/s]
56%|█████▋ | 96.3M/170M [15:12<13:18, 93.0kB/s]
57%|█████▋ | 96.3M/170M [15:13<13:21, 92.5kB/s]
57%|█████▋ | 96.4M/170M [15:13<14:34, 84.8kB/s]
57%|█████▋ | 96.4M/170M [15:13<15:36, 79.1kB/s]
57%|█████▋ | 96.4M/170M [15:14<13:40, 90.3kB/s]
57%|█████▋ | 96.5M/170M [15:14<13:55, 88.6kB/s]
57%|█████▋ | 96.5M/170M [15:14<13:11, 93.5kB/s]
57%|█████▋ | 96.5M/170M [15:15<14:35, 84.5kB/s]
57%|█████▋ | 96.6M/170M [15:15<14:17, 86.2kB/s]
57%|█████▋ | 96.6M/170M [15:16<18:50, 65.4kB/s]
57%|█████▋ | 96.6M/170M [15:17<18:51, 65.3kB/s]
57%|█████▋ | 96.7M/170M [15:17<17:22, 70.8kB/s]
57%|█████▋ | 96.7M/170M [15:17<18:00, 68.3kB/s]
57%|█████▋ | 96.7M/170M [15:18<18:53, 65.1kB/s]
57%|█████▋ | 96.8M/170M [15:18<18:42, 65.7kB/s]
57%|█████▋ | 96.8M/170M [15:19<19:18, 63.6kB/s]
57%|█████▋ | 96.8M/170M [15:20<20:31, 59.8kB/s]
57%|█████▋ | 96.9M/170M [15:20<17:38, 69.6kB/s]
57%|█████▋ | 96.9M/170M [15:20<16:44, 73.3kB/s]
57%|█████▋ | 96.9M/170M [15:21<17:18, 70.8kB/s]
57%|█████▋ | 97.0M/170M [15:21<16:39, 73.6kB/s]
57%|█████▋ | 97.0M/170M [15:22<15:15, 80.2kB/s]
57%|█████▋ | 97.0M/170M [15:22<14:07, 86.7kB/s]
57%|█████▋ | 97.1M/170M [15:22<12:42, 96.3kB/s]
57%|█████▋ | 97.1M/170M [15:22<12:08, 101kB/s]
57%|█████▋ | 97.1M/170M [15:23<11:26, 107kB/s]
57%|█████▋ | 97.2M/170M [15:23<11:09, 110kB/s]
57%|█████▋ | 97.2M/170M [15:23<10:04, 121kB/s]
57%|█████▋ | 97.2M/170M [15:23<09:51, 124kB/s]
57%|█████▋ | 97.3M/170M [15:24<09:48, 124kB/s]
57%|█████▋ | 97.3M/170M [15:24<10:01, 122kB/s]
57%|█████▋ | 97.3M/170M [15:24<09:42, 126kB/s]
57%|█████▋ | 97.4M/170M [15:24<09:18, 131kB/s]
57%|█████▋ | 97.4M/170M [15:25<09:16, 131kB/s]
57%|█████▋ | 97.4M/170M [15:25<08:32, 143kB/s]
57%|█████▋ | 97.5M/170M [15:25<08:17, 147kB/s]
57%|█████▋ | 97.5M/170M [15:25<08:12, 148kB/s]
57%|█████▋ | 97.5M/170M [15:25<07:42, 158kB/s]
57%|█████▋ | 97.6M/170M [15:26<08:07, 150kB/s]
57%|█████▋ | 97.6M/170M [15:26<07:53, 154kB/s]
57%|█████▋ | 97.6M/170M [15:26<07:41, 158kB/s]
57%|█████▋ | 97.6M/170M [15:26<08:20, 146kB/s]
57%|█████▋ | 97.7M/170M [15:27<08:12, 148kB/s]
57%|█████▋ | 97.7M/170M [15:27<08:03, 151kB/s]
57%|█████▋ | 97.7M/170M [15:27<08:12, 148kB/s]
57%|█████▋ | 97.8M/170M [15:27<07:42, 157kB/s]
57%|█████▋ | 97.8M/170M [15:27<08:00, 151kB/s]
57%|█████▋ | 97.8M/170M [15:28<07:54, 153kB/s]
57%|█████▋ | 97.9M/170M [15:28<07:57, 152kB/s]
57%|█████▋ | 97.9M/170M [15:28<07:53, 153kB/s]
57%|█████▋ | 97.9M/170M [15:28<08:39, 140kB/s]
57%|█████▋ | 98.0M/170M [15:29<09:18, 130kB/s]
57%|█████▋ | 98.0M/170M [15:29<08:58, 135kB/s]
58%|█████▊ | 98.0M/170M [15:29<09:21, 129kB/s]
58%|█████▊ | 98.1M/170M [15:29<08:16, 146kB/s]
58%|█████▊ | 98.1M/170M [15:30<08:46, 137kB/s]
58%|█████▊ | 98.1M/170M [15:30<08:29, 142kB/s]
58%|█████▊ | 98.2M/170M [15:30<08:30, 142kB/s]
58%|█████▊ | 98.2M/170M [15:30<08:41, 139kB/s]
58%|█████▊ | 98.2M/170M [15:30<07:48, 154kB/s]
58%|█████▊ | 98.3M/170M [15:31<07:35, 158kB/s]
58%|█████▊ | 98.3M/170M [15:31<08:12, 147kB/s]
58%|█████▊ | 98.3M/170M [15:31<07:49, 154kB/s]
58%|█████▊ | 98.4M/170M [15:31<08:00, 150kB/s]
58%|█████▊ | 98.4M/170M [15:31<07:52, 152kB/s]
58%|█████▊ | 98.4M/170M [15:32<07:35, 158kB/s]
58%|█████▊ | 98.5M/170M [15:32<07:47, 154kB/s]
58%|█████▊ | 98.5M/170M [15:32<07:46, 154kB/s]
58%|█████▊ | 98.5M/170M [15:32<07:48, 154kB/s]
58%|█████▊ | 98.6M/170M [15:33<07:50, 153kB/s]
58%|█████▊ | 98.6M/170M [15:33<07:37, 157kB/s]
58%|█████▊ | 98.6M/170M [15:33<07:54, 151kB/s]
58%|█████▊ | 98.7M/170M [15:33<08:23, 143kB/s]
58%|█████▊ | 98.7M/170M [15:34<09:04, 132kB/s]
58%|█████▊ | 98.7M/170M [15:34<09:10, 130kB/s]
58%|█████▊ | 98.8M/170M [15:34<08:41, 138kB/s]
58%|█████▊ | 98.8M/170M [15:34<08:23, 142kB/s]
58%|█████▊ | 98.8M/170M [15:34<08:10, 146kB/s]
58%|█████▊ | 98.9M/170M [15:35<07:54, 151kB/s]
58%|█████▊ | 98.9M/170M [15:35<08:08, 147kB/s]
58%|█████▊ | 98.9M/170M [15:35<08:23, 142kB/s]
58%|█████▊ | 99.0M/170M [15:35<07:38, 156kB/s]
58%|█████▊ | 99.0M/170M [15:36<08:34, 139kB/s]
58%|█████▊ | 99.0M/170M [15:36<09:25, 126kB/s]
58%|█████▊ | 99.1M/170M [15:36<09:23, 127kB/s]
58%|█████▊ | 99.1M/170M [15:36<08:21, 142kB/s]
58%|█████▊ | 99.1M/170M [15:37<08:34, 139kB/s]
58%|█████▊ | 99.2M/170M [15:37<09:01, 132kB/s]
58%|█████▊ | 99.2M/170M [15:37<09:04, 131kB/s]
58%|█████▊ | 99.2M/170M [15:37<08:28, 140kB/s]
58%|█████▊ | 99.3M/170M [15:37<07:59, 148kB/s]
58%|█████▊ | 99.3M/170M [15:38<08:01, 148kB/s]
58%|█████▊ | 99.3M/170M [15:38<07:34, 157kB/s]
58%|█████▊ | 99.4M/170M [15:38<08:37, 138kB/s]
58%|█████▊ | 99.4M/170M [15:38<08:19, 142kB/s]
58%|█████▊ | 99.4M/170M [15:39<08:14, 144kB/s]
58%|█████▊ | 99.5M/170M [15:39<07:45, 153kB/s]
58%|█████▊ | 99.5M/170M [15:39<07:48, 151kB/s]
58%|█████▊ | 99.5M/170M [15:39<07:36, 156kB/s]
58%|█████▊ | 99.5M/170M [15:39<07:37, 155kB/s]
58%|█████▊ | 99.6M/170M [15:40<08:36, 137kB/s]
58%|█████▊ | 99.6M/170M [15:40<14:01, 84.2kB/s]
58%|█████▊ | 99.6M/170M [15:41<15:56, 74.1kB/s]
58%|█████▊ | 99.7M/170M [15:42<17:51, 66.1kB/s]
58%|█████▊ | 99.7M/170M [15:42<16:22, 72.1kB/s]
59%|█████▊ | 99.7M/170M [15:42<15:05, 78.1kB/s]
59%|█████▊ | 99.8M/170M [15:43<14:53, 79.2kB/s]
59%|█████▊ | 99.8M/170M [15:43<15:30, 76.0kB/s]
59%|█████▊ | 99.8M/170M [15:44<18:56, 62.2kB/s]
59%|█████▊ | 99.9M/170M [15:44<18:04, 65.1kB/s]
59%|█████▊ | 99.9M/170M [15:45<20:28, 57.4kB/s]
59%|█████▊ | 99.9M/170M [15:46<18:22, 64.0kB/s]
59%|█████▊ | 100M/170M [15:46<16:47, 70.0kB/s]
59%|█████▊ | 100M/170M [15:46<15:22, 76.4kB/s]
59%|█████▊ | 100M/170M [15:46<12:42, 92.4kB/s]
59%|█████▊ | 100M/170M [15:47<11:13, 105kB/s]
59%|█████▊ | 100M/170M [15:47<10:10, 115kB/s]
59%|█████▊ | 100M/170M [15:47<09:05, 129kB/s]
59%|█████▉ | 100M/170M [15:47<09:09, 128kB/s]
59%|█████▉ | 100M/170M [15:47<08:23, 140kB/s]
59%|█████▉ | 100M/170M [15:48<10:01, 117kB/s]
59%|█████▉ | 100M/170M [15:48<10:28, 112kB/s]
59%|█████▉ | 100M/170M [15:49<12:15, 95.4kB/s]
59%|█████▉ | 100M/170M [15:49<13:34, 86.2kB/s]
59%|█████▉ | 100M/170M [15:49<12:47, 91.4kB/s]
59%|█████▉ | 100M/170M [15:50<10:50, 108kB/s]
59%|█████▉ | 100M/170M [15:50<10:07, 115kB/s]
59%|█████▉ | 100M/170M [15:50<09:36, 121kB/s]
59%|█████▉ | 100M/170M [15:50<09:03, 129kB/s]
59%|█████▉ | 101M/170M [15:51<09:13, 126kB/s]
59%|█████▉ | 101M/170M [15:51<08:21, 140kB/s]
59%|█████▉ | 101M/170M [15:51<08:20, 140kB/s]
59%|█████▉ | 101M/170M [15:51<08:08, 143kB/s]
59%|█████▉ | 101M/170M [15:51<08:04, 144kB/s]
59%|█████▉ | 101M/170M [15:52<08:36, 135kB/s]
59%|█████▉ | 101M/170M [15:52<07:43, 150kB/s]
59%|█████▉ | 101M/170M [15:52<07:44, 150kB/s]
59%|█████▉ | 101M/170M [15:52<07:56, 146kB/s]
59%|█████▉ | 101M/170M [15:52<07:27, 156kB/s]
59%|█████▉ | 101M/170M [15:53<07:25, 156kB/s]
59%|█████▉ | 101M/170M [15:53<07:31, 154kB/s]
59%|█████▉ | 101M/170M [15:53<07:23, 157kB/s]
59%|█████▉ | 101M/170M [15:53<07:46, 149kB/s]
59%|█████▉ | 101M/170M [15:54<07:45, 149kB/s]
59%|█████▉ | 101M/170M [15:54<10:40, 108kB/s]
59%|█████▉ | 101M/170M [15:55<14:49, 78.1kB/s]
59%|█████▉ | 101M/170M [15:55<14:11, 81.5kB/s]
59%|█████▉ | 101M/170M [15:55<13:04, 88.5kB/s]
59%|█████▉ | 101M/170M [15:56<12:03, 95.9kB/s]
59%|█████▉ | 101M/170M [15:56<11:22, 102kB/s]
59%|█████▉ | 101M/170M [15:56<11:05, 104kB/s]
59%|█████▉ | 101M/170M [15:57<11:16, 102kB/s]
59%|█████▉ | 101M/170M [15:57<13:42, 84.2kB/s]
59%|█████▉ | 101M/170M [15:57<11:45, 98.1kB/s]
59%|█████▉ | 101M/170M [15:58<10:26, 110kB/s]
59%|█████▉ | 101M/170M [15:58<10:09, 113kB/s]
59%|█████▉ | 101M/170M [15:58<08:53, 129kB/s]
60%|█████▉ | 101M/170M [15:58<08:38, 133kB/s]
60%|█████▉ | 101M/170M [15:58<07:57, 145kB/s]
60%|█████▉ | 102M/170M [15:59<08:02, 143kB/s]
60%|█████▉ | 102M/170M [15:59<07:42, 149kB/s]
60%|█████▉ | 102M/170M [15:59<07:41, 149kB/s]
60%|█████▉ | 102M/170M [15:59<07:34, 152kB/s]
60%|█████▉ | 102M/170M [16:00<08:07, 141kB/s]
60%|█████▉ | 102M/170M [16:00<08:16, 139kB/s]
60%|█████▉ | 102M/170M [16:00<09:46, 117kB/s]
60%|█████▉ | 102M/170M [16:01<12:58, 88.3kB/s]
60%|█████▉ | 102M/170M [16:01<13:22, 85.7kB/s]
60%|█████▉ | 102M/170M [16:02<12:54, 88.6kB/s]
60%|█████▉ | 102M/170M [16:02<12:51, 89.0kB/s]
60%|█████▉ | 102M/170M [16:02<12:07, 94.3kB/s]
60%|█████▉ | 102M/170M [16:03<13:21, 85.5kB/s]
60%|█████▉ | 102M/170M [16:03<13:24, 85.2kB/s]
60%|█████▉ | 102M/170M [16:03<12:43, 89.7kB/s]
60%|█████▉ | 102M/170M [16:04<12:43, 89.7kB/s]
60%|█████▉ | 102M/170M [16:04<13:39, 83.5kB/s]
60%|█████▉ | 102M/170M [16:05<15:59, 71.3kB/s]
60%|█████▉ | 102M/170M [16:05<15:28, 73.7kB/s]
60%|█████▉ | 102M/170M [16:06<14:26, 78.9kB/s]
60%|█████▉ | 102M/170M [16:06<13:06, 86.9kB/s]
60%|█████▉ | 102M/170M [16:06<11:47, 96.6kB/s]
60%|█████▉ | 102M/170M [16:06<10:20, 110kB/s]
60%|█████▉ | 102M/170M [16:07<09:32, 119kB/s]
60%|██████ | 102M/170M [16:07<08:51, 128kB/s]
60%|██████ | 102M/170M [16:07<08:29, 134kB/s]
60%|██████ | 102M/170M [16:07<08:11, 138kB/s]
60%|██████ | 102M/170M [16:07<08:08, 139kB/s]
60%|██████ | 102M/170M [16:08<07:57, 143kB/s]
60%|██████ | 102M/170M [16:08<07:49, 145kB/s]
60%|██████ | 102M/170M [16:08<07:26, 152kB/s]
60%|██████ | 103M/170M [16:08<07:51, 144kB/s]
60%|██████ | 103M/170M [16:08<07:30, 151kB/s]
60%|██████ | 103M/170M [16:09<07:22, 153kB/s]
60%|██████ | 103M/170M [16:09<07:19, 154kB/s]
60%|██████ | 103M/170M [16:09<07:34, 149kB/s]
60%|██████ | 103M/170M [16:09<07:53, 143kB/s]
60%|██████ | 103M/170M [16:10<07:28, 151kB/s]
60%|██████ | 103M/170M [16:10<08:09, 138kB/s]
60%|██████ | 103M/170M [16:10<07:54, 143kB/s]
60%|██████ | 103M/170M [16:10<07:28, 151kB/s]
60%|██████ | 103M/170M [16:11<09:20, 121kB/s]
60%|██████ | 103M/170M [16:12<15:55, 70.7kB/s]
60%|██████ | 103M/170M [16:12<17:23, 64.7kB/s]
60%|██████ | 103M/170M [16:13<20:54, 53.8kB/s]
60%|██████ | 103M/170M [16:13<18:38, 60.4kB/s]
60%|██████ | 103M/170M [16:14<17:17, 65.1kB/s]
60%|██████ | 103M/170M [16:15<22:07, 50.8kB/s]
60%|██████ | 103M/170M [16:16<24:01, 46.8kB/s]
60%|██████ | 103M/170M [16:16<20:34, 54.6kB/s]
61%|██████ | 103M/170M [16:16<17:43, 63.3kB/s]
61%|██████ | 103M/170M [16:17<15:28, 72.5kB/s]
61%|██████ | 103M/170M [16:17<13:49, 81.1kB/s]
61%|██████ | 103M/170M [16:17<12:50, 87.2kB/s]
61%|██████ | 103M/170M [16:17<11:53, 94.2kB/s]
61%|██████ | 103M/170M [16:18<13:18, 84.1kB/s]
61%|██████ | 103M/170M [16:18<13:37, 82.1kB/s]
61%|██████ | 103M/170M [16:19<12:49, 87.2kB/s]
61%|██████ | 103M/170M [16:19<12:25, 90.0kB/s]
61%|██████ | 103M/170M [16:20<13:34, 82.3kB/s]
61%|██████ | 103M/170M [16:20<12:49, 87.1kB/s]
61%|██████ | 104M/170M [16:20<13:19, 83.7kB/s]
61%|██████ | 104M/170M [16:21<12:58, 86.0kB/s]
61%|██████ | 104M/170M [16:21<11:50, 94.1kB/s]
61%|██████ | 104M/170M [16:21<10:52, 102kB/s]
61%|██████ | 104M/170M [16:21<11:04, 101kB/s]
61%|██████ | 104M/170M [16:22<10:51, 103kB/s]
61%|██████ | 104M/170M [16:22<11:12, 99.3kB/s]
61%|██████ | 104M/170M [16:22<10:33, 105kB/s]
61%|██████ | 104M/170M [16:23<12:02, 92.4kB/s]
61%|██████ | 104M/170M [16:23<12:40, 87.7kB/s]
61%|██████ | 104M/170M [16:24<12:18, 90.3kB/s]
61%|██████ | 104M/170M [16:24<11:51, 93.6kB/s]
61%|██████ | 104M/170M [16:24<11:41, 95.0kB/s]
61%|██████ | 104M/170M [16:25<11:48, 93.9kB/s]
61%|██████ | 104M/170M [16:25<11:17, 98.2kB/s]
61%|██████ | 104M/170M [16:25<10:31, 105kB/s]
61%|██████ | 104M/170M [16:25<10:21, 107kB/s]
61%|██████ | 104M/170M [16:26<11:35, 95.4kB/s]
61%|██████ | 104M/170M [16:26<11:31, 96.0kB/s]
61%|██████ | 104M/170M [16:27<11:58, 92.4kB/s]
61%|██████ | 104M/170M [16:27<09:35, 115kB/s]
61%|██████ | 104M/170M [16:27<11:23, 96.9kB/s]
61%|██████ | 104M/170M [16:28<11:27, 96.4kB/s]
61%|██████ | 104M/170M [16:28<12:41, 86.9kB/s]
61%|██████ | 104M/170M [16:28<12:21, 89.3kB/s]
61%|██████ | 104M/170M [16:29<11:06, 99.2kB/s]
61%|██████ | 104M/170M [16:29<10:19, 107kB/s]
61%|██████ | 104M/170M [16:29<09:23, 117kB/s]
61%|██████▏ | 104M/170M [16:29<08:31, 129kB/s]
61%|██████▏ | 104M/170M [16:30<08:36, 128kB/s]
61%|██████▏ | 104M/170M [16:30<08:08, 135kB/s]
61%|██████▏ | 105M/170M [16:30<08:01, 137kB/s]
61%|██████▏ | 105M/170M [16:30<07:53, 139kB/s]
61%|██████▏ | 105M/170M [16:30<07:53, 139kB/s]
61%|██████▏ | 105M/170M [16:31<07:34, 145kB/s]
61%|██████▏ | 105M/170M [16:31<07:39, 143kB/s]
61%|██████▏ | 105M/170M [16:31<07:15, 151kB/s]
61%|██████▏ | 105M/170M [16:32<11:01, 99.5kB/s]
61%|██████▏ | 105M/170M [16:32<12:30, 87.6kB/s]
61%|██████▏ | 105M/170M [16:33<16:32, 66.2kB/s]
61%|██████▏ | 105M/170M [16:33<13:49, 79.2kB/s]
62%|██████▏ | 105M/170M [16:33<12:06, 90.4kB/s]
62%|██████▏ | 105M/170M [16:34<11:02, 99.1kB/s]
62%|██████▏ | 105M/170M [16:34<09:22, 117kB/s]
62%|██████▏ | 105M/170M [16:34<09:33, 114kB/s]
62%|██████▏ | 105M/170M [16:34<08:47, 124kB/s]
62%|██████▏ | 105M/170M [16:35<08:19, 131kB/s]
62%|██████▏ | 105M/170M [16:35<08:59, 121kB/s]
62%|██████▏ | 105M/170M [16:35<07:43, 141kB/s]
62%|██████▏ | 105M/170M [16:35<07:30, 145kB/s]
62%|██████▏ | 105M/170M [16:35<07:53, 138kB/s]
62%|██████▏ | 105M/170M [16:36<07:58, 137kB/s]
62%|██████▏ | 105M/170M [16:36<08:22, 130kB/s]
62%|██████▏ | 105M/170M [16:36<07:46, 140kB/s]
62%|██████▏ | 105M/170M [16:36<07:43, 141kB/s]
62%|██████▏ | 105M/170M [16:37<08:24, 129kB/s]
62%|██████▏ | 105M/170M [16:37<08:32, 127kB/s]
62%|██████▏ | 105M/170M [16:37<08:03, 135kB/s]
62%|██████▏ | 105M/170M [16:37<07:29, 145kB/s]
62%|██████▏ | 105M/170M [16:38<08:08, 133kB/s]
62%|██████▏ | 105M/170M [16:38<08:43, 124kB/s]
62%|██████▏ | 106M/170M [16:38<09:31, 114kB/s]
62%|██████▏ | 106M/170M [16:39<09:05, 119kB/s]
62%|██████▏ | 106M/170M [16:39<08:09, 133kB/s]
62%|██████▏ | 106M/170M [16:39<08:02, 134kB/s]
62%|██████▏ | 106M/170M [16:39<07:38, 141kB/s]
62%|██████▏ | 106M/170M [16:39<07:27, 145kB/s]
62%|██████▏ | 106M/170M [16:40<08:19, 130kB/s]
62%|██████▏ | 106M/170M [16:40<08:00, 135kB/s]
62%|██████▏ | 106M/170M [16:40<08:19, 130kB/s]
62%|██████▏ | 106M/170M [16:40<07:27, 145kB/s]
62%|██████▏ | 106M/170M [16:41<07:41, 140kB/s]
62%|██████▏ | 106M/170M [16:41<08:16, 130kB/s]
62%|██████▏ | 106M/170M [16:41<07:06, 152kB/s]
62%|██████▏ | 106M/170M [16:41<07:04, 152kB/s]
62%|██████▏ | 106M/170M [16:42<07:19, 147kB/s]
62%|██████▏ | 106M/170M [16:42<06:54, 156kB/s]
62%|██████▏ | 106M/170M [16:42<06:34, 164kB/s]
62%|██████▏ | 106M/170M [16:42<06:39, 161kB/s]
62%|██████▏ | 106M/170M [16:42<07:02, 152kB/s]
62%|██████▏ | 106M/170M [16:43<07:16, 147kB/s]
62%|██████▏ | 106M/170M [16:43<07:00, 153kB/s]
62%|██████▏ | 106M/170M [16:43<07:20, 146kB/s]
62%|██████▏ | 106M/170M [16:43<06:38, 161kB/s]
62%|██████▏ | 106M/170M [16:43<06:52, 156kB/s]
62%|██████▏ | 106M/170M [16:44<06:33, 163kB/s]
62%|██████▏ | 106M/170M [16:44<07:00, 153kB/s]
62%|██████▏ | 106M/170M [16:44<07:37, 140kB/s]
62%|██████▏ | 106M/170M [16:44<07:26, 144kB/s]
62%|██████▏ | 106M/170M [16:45<07:37, 140kB/s]
62%|██████▏ | 106M/170M [16:45<07:27, 143kB/s]
62%|██████▏ | 106M/170M [16:45<08:05, 132kB/s]
62%|██████▏ | 107M/170M [16:45<07:52, 135kB/s]
63%|██████▎ | 107M/170M [16:46<07:34, 141kB/s]
63%|██████▎ | 107M/170M [16:46<07:32, 141kB/s]
63%|██████▎ | 107M/170M [16:46<07:40, 139kB/s]
63%|██████▎ | 107M/170M [16:46<08:34, 124kB/s]
63%|██████▎ | 107M/170M [16:47<08:45, 121kB/s]
63%|██████▎ | 107M/170M [16:47<07:56, 134kB/s]
63%|██████▎ | 107M/170M [16:47<07:49, 136kB/s]
63%|██████▎ | 107M/170M [16:47<07:57, 133kB/s]
63%|██████▎ | 107M/170M [16:48<07:57, 133kB/s]
63%|██████▎ | 107M/170M [16:48<08:15, 128kB/s]
63%|██████▎ | 107M/170M [16:48<08:14, 129kB/s]
63%|██████▎ | 107M/170M [16:48<08:04, 131kB/s]
63%|██████▎ | 107M/170M [16:49<07:47, 136kB/s]
63%|██████▎ | 107M/170M [16:49<07:28, 142kB/s]
63%|██████▎ | 107M/170M [16:49<08:09, 130kB/s]
63%|██████▎ | 107M/170M [16:49<07:24, 143kB/s]
63%|██████▎ | 107M/170M [16:49<07:45, 136kB/s]
63%|██████▎ | 107M/170M [16:50<07:59, 132kB/s]
63%|██████▎ | 107M/170M [16:50<07:28, 141kB/s]
63%|██████▎ | 107M/170M [16:50<08:49, 120kB/s]
63%|██████▎ | 107M/170M [16:51<08:17, 127kB/s]
63%|██████▎ | 107M/170M [16:51<08:07, 130kB/s]
63%|██████▎ | 107M/170M [16:51<08:32, 123kB/s]
63%|██████▎ | 107M/170M [16:51<08:34, 123kB/s]
63%|██████▎ | 107M/170M [16:52<08:28, 124kB/s]
63%|██████▎ | 107M/170M [16:52<08:11, 128kB/s]
63%|██████▎ | 107M/170M [16:52<08:03, 131kB/s]
63%|██████▎ | 107M/170M [16:52<08:18, 127kB/s]
63%|██████▎ | 107M/170M [16:53<08:04, 130kB/s]
63%|██████▎ | 108M/170M [16:53<08:05, 130kB/s]
63%|██████▎ | 108M/170M [16:53<08:35, 122kB/s]
63%|██████▎ | 108M/170M [16:53<08:22, 125kB/s]
63%|██████▎ | 108M/170M [16:54<08:23, 125kB/s]
63%|██████▎ | 108M/170M [16:54<09:06, 115kB/s]
63%|██████▎ | 108M/170M [16:54<08:43, 120kB/s]
63%|██████▎ | 108M/170M [16:55<09:12, 114kB/s]
63%|██████▎ | 108M/170M [16:55<08:54, 117kB/s]
63%|██████▎ | 108M/170M [16:55<08:45, 119kB/s]
63%|██████▎ | 108M/170M [16:55<08:34, 122kB/s]
63%|██████▎ | 108M/170M [16:56<08:08, 128kB/s]
63%|██████▎ | 108M/170M [16:56<08:38, 121kB/s]
63%|██████▎ | 108M/170M [16:56<08:36, 121kB/s]
63%|██████▎ | 108M/170M [16:56<08:55, 117kB/s]
63%|██████▎ | 108M/170M [16:57<08:24, 124kB/s]
63%|██████▎ | 108M/170M [16:57<08:33, 122kB/s]
63%|██████▎ | 108M/170M [16:57<08:23, 124kB/s]
63%|██████▎ | 108M/170M [16:58<09:13, 113kB/s]
63%|██████▎ | 108M/170M [16:58<09:22, 111kB/s]
63%|██████▎ | 108M/170M [16:58<09:33, 109kB/s]
63%|██████▎ | 108M/170M [16:58<09:32, 109kB/s]
63%|██████▎ | 108M/170M [16:59<10:17, 101kB/s]
63%|██████▎ | 108M/170M [16:59<10:26, 99.4kB/s]
63%|██████▎ | 108M/170M [17:00<10:20, 100kB/s]
64%|██████▎ | 108M/170M [17:00<09:41, 107kB/s]
64%|██████▎ | 108M/170M [17:00<09:21, 111kB/s]
64%|██████▎ | 108M/170M [17:00<08:48, 118kB/s]
64%|██████▎ | 108M/170M [17:01<08:24, 123kB/s]
64%|██████▎ | 108M/170M [17:01<08:50, 117kB/s]
64%|██████▎ | 108M/170M [17:01<08:32, 121kB/s]
64%|██████▎ | 108M/170M [17:01<08:00, 129kB/s]
64%|██████▎ | 109M/170M [17:02<07:44, 133kB/s]
64%|██████▎ | 109M/170M [17:02<08:41, 119kB/s]
64%|██████▎ | 109M/170M [17:02<07:28, 138kB/s]
64%|██████▎ | 109M/170M [17:02<07:46, 133kB/s]
64%|██████▎ | 109M/170M [17:03<07:54, 130kB/s]
64%|██████▎ | 109M/170M [17:03<07:46, 132kB/s]
64%|██████▍ | 109M/170M [17:03<07:49, 132kB/s]
64%|██████▍ | 109M/170M [17:03<07:47, 132kB/s]
64%|██████▍ | 109M/170M [17:04<07:38, 135kB/s]
64%|██████▍ | 109M/170M [17:04<08:10, 126kB/s]
64%|██████▍ | 109M/170M [17:04<08:37, 119kB/s]
64%|██████▍ | 109M/170M [17:04<08:26, 122kB/s]
64%|██████▍ | 109M/170M [17:05<08:22, 122kB/s]
64%|██████▍ | 109M/170M [17:05<08:02, 127kB/s]
64%|██████▍ | 109M/170M [17:05<08:03, 127kB/s]
64%|██████▍ | 109M/170M [17:05<07:25, 138kB/s]
64%|██████▍ | 109M/170M [17:06<07:16, 141kB/s]
64%|██████▍ | 109M/170M [17:06<07:40, 133kB/s]
64%|██████▍ | 109M/170M [17:06<07:50, 130kB/s]
64%|██████▍ | 109M/170M [17:06<07:55, 129kB/s]
64%|██████▍ | 109M/170M [17:07<07:34, 135kB/s]
64%|██████▍ | 109M/170M [17:07<08:00, 128kB/s]
64%|██████▍ | 109M/170M [17:07<08:26, 121kB/s]
64%|██████▍ | 109M/170M [17:07<08:08, 125kB/s]
64%|██████▍ | 109M/170M [17:08<08:04, 126kB/s]
64%|██████▍ | 109M/170M [17:08<08:04, 126kB/s]
64%|██████▍ | 109M/170M [17:08<08:31, 119kB/s]
64%|██████▍ | 109M/170M [17:08<08:21, 122kB/s]
64%|██████▍ | 109M/170M [17:09<08:21, 122kB/s]
64%|██████▍ | 109M/170M [17:09<07:58, 127kB/s]
64%|██████▍ | 110M/170M [17:09<07:56, 128kB/s]
64%|██████▍ | 110M/170M [17:09<07:32, 135kB/s]
64%|██████▍ | 110M/170M [17:10<08:52, 114kB/s]
64%|██████▍ | 110M/170M [17:10<08:12, 124kB/s]
64%|██████▍ | 110M/170M [17:10<08:04, 126kB/s]
64%|██████▍ | 110M/170M [17:11<07:41, 132kB/s]
64%|██████▍ | 110M/170M [17:11<07:54, 128kB/s]
64%|██████▍ | 110M/170M [17:11<07:25, 136kB/s]
64%|██████▍ | 110M/170M [17:11<07:16, 139kB/s]
64%|██████▍ | 110M/170M [17:11<06:49, 148kB/s]
64%|██████▍ | 110M/170M [17:12<07:40, 132kB/s]
64%|██████▍ | 110M/170M [17:12<06:48, 148kB/s]
64%|██████▍ | 110M/170M [17:12<06:38, 152kB/s]
64%|██████▍ | 110M/170M [17:12<07:16, 139kB/s]
64%|██████▍ | 110M/170M [17:13<08:02, 125kB/s]
65%|██████▍ | 110M/170M [17:13<08:01, 126kB/s]
65%|██████▍ | 110M/170M [17:13<07:34, 133kB/s]
65%|██████▍ | 110M/170M [17:13<07:30, 134kB/s]
65%|██████▍ | 110M/170M [17:14<07:40, 131kB/s]
65%|██████▍ | 110M/170M [17:14<07:36, 132kB/s]
65%|██████▍ | 110M/170M [17:14<07:50, 128kB/s]
65%|██████▍ | 110M/170M [17:14<07:30, 134kB/s]
65%|██████▍ | 110M/170M [17:15<07:18, 137kB/s]
65%|██████▍ | 110M/170M [17:15<07:57, 126kB/s]
65%|██████▍ | 110M/170M [17:15<08:09, 123kB/s]
65%|██████▍ | 110M/170M [17:16<08:53, 113kB/s]
65%|██████▍ | 110M/170M [17:16<08:34, 117kB/s]
65%|██████▍ | 110M/170M [17:16<08:47, 114kB/s]
65%|██████▍ | 110M/170M [17:16<08:11, 122kB/s]
65%|██████▍ | 110M/170M [17:17<08:03, 124kB/s]
65%|██████▍ | 110M/170M [17:17<08:06, 123kB/s]
65%|██████▍ | 111M/170M [17:17<07:49, 128kB/s]
65%|██████▍ | 111M/170M [17:17<07:54, 126kB/s]
65%|██████▍ | 111M/170M [17:18<09:01, 111kB/s]
65%|██████▍ | 111M/170M [17:18<08:30, 117kB/s]
65%|██████▍ | 111M/170M [17:18<09:05, 110kB/s]
65%|██████▍ | 111M/170M [17:19<08:32, 117kB/s]
65%|██████▍ | 111M/170M [17:19<08:28, 118kB/s]
65%|██████▍ | 111M/170M [17:19<07:47, 128kB/s]
65%|██████▍ | 111M/170M [17:19<08:21, 119kB/s]
65%|██████▍ | 111M/170M [17:20<08:28, 117kB/s]
65%|██████▌ | 111M/170M [17:20<07:52, 126kB/s]
65%|██████▌ | 111M/170M [17:20<07:53, 126kB/s]
65%|██████▌ | 111M/170M [17:20<07:48, 127kB/s]
65%|██████▌ | 111M/170M [17:21<08:07, 122kB/s]
65%|██████▌ | 111M/170M [17:21<08:00, 124kB/s]
65%|██████▌ | 111M/170M [17:21<07:56, 125kB/s]
65%|██████▌ | 111M/170M [17:21<07:48, 127kB/s]
65%|██████▌ | 111M/170M [17:22<07:24, 134kB/s]
65%|██████▌ | 111M/170M [17:22<07:18, 135kB/s]
65%|██████▌ | 111M/170M [17:22<07:12, 137kB/s]
65%|██████▌ | 111M/170M [17:22<07:13, 137kB/s]
65%|██████▌ | 111M/170M [17:23<07:04, 140kB/s]
65%|██████▌ | 111M/170M [17:23<06:44, 147kB/s]
65%|██████▌ | 111M/170M [17:23<07:18, 135kB/s]
65%|██████▌ | 111M/170M [17:23<07:10, 138kB/s]
65%|██████▌ | 111M/170M [17:24<07:08, 138kB/s]
65%|██████▌ | 111M/170M [17:24<06:45, 146kB/s]
65%|██████▌ | 111M/170M [17:24<07:18, 135kB/s]
65%|██████▌ | 111M/170M [17:24<07:30, 131kB/s]
65%|██████▌ | 111M/170M [17:25<07:18, 135kB/s]
65%|██████▌ | 112M/170M [17:25<07:16, 135kB/s]
65%|██████▌ | 112M/170M [17:25<07:29, 131kB/s]
65%|██████▌ | 112M/170M [17:25<07:18, 134kB/s]
65%|██████▌ | 112M/170M [17:25<07:12, 136kB/s]
65%|██████▌ | 112M/170M [17:26<07:51, 125kB/s]
65%|██████▌ | 112M/170M [17:26<07:07, 138kB/s]
66%|██████▌ | 112M/170M [17:26<07:35, 129kB/s]
66%|██████▌ | 112M/170M [17:27<07:31, 130kB/s]
66%|██████▌ | 112M/170M [17:27<08:50, 111kB/s]
66%|██████▌ | 112M/170M [17:27<08:44, 112kB/s]
66%|██████▌ | 112M/170M [17:27<08:13, 119kB/s]
66%|██████▌ | 112M/170M [17:28<07:50, 125kB/s]
66%|██████▌ | 112M/170M [17:28<07:43, 127kB/s]
66%|██████▌ | 112M/170M [17:28<07:17, 134kB/s]
66%|██████▌ | 112M/170M [17:29<11:53, 82.0kB/s]
66%|██████▌ | 112M/170M [17:29<10:47, 90.4kB/s]
66%|██████▌ | 112M/170M [17:29<09:52, 98.7kB/s]
66%|██████▌ | 112M/170M [17:30<08:43, 112kB/s]
66%|██████▌ | 112M/170M [17:30<08:14, 118kB/s]
66%|██████▌ | 112M/170M [17:30<07:35, 128kB/s]
66%|██████▌ | 112M/170M [17:30<07:26, 131kB/s]
66%|██████▌ | 112M/170M [17:31<07:08, 136kB/s]
66%|██████▌ | 112M/170M [17:31<11:26, 84.8kB/s]
66%|██████▌ | 112M/170M [17:32<12:34, 77.2kB/s]
66%|██████▌ | 112M/170M [17:33<16:49, 57.6kB/s]
66%|██████▌ | 112M/170M [17:33<15:10, 63.9kB/s]
66%|██████▌ | 112M/170M [17:33<13:11, 73.4kB/s]
66%|██████▌ | 112M/170M [17:34<12:09, 79.6kB/s]
66%|██████▌ | 112M/170M [17:34<10:48, 89.5kB/s]
66%|██████▌ | 112M/170M [17:34<10:39, 90.7kB/s]
66%|██████▌ | 112M/170M [17:34<09:04, 106kB/s]
66%|██████▌ | 113M/170M [17:35<09:23, 103kB/s]
66%|██████▌ | 113M/170M [17:35<08:45, 110kB/s]
66%|██████▌ | 113M/170M [17:35<08:24, 115kB/s]
66%|██████▌ | 113M/170M [17:36<07:55, 122kB/s]
66%|██████▌ | 113M/170M [17:36<08:18, 116kB/s]
66%|██████▌ | 113M/170M [17:36<07:55, 122kB/s]
66%|██████▌ | 113M/170M [17:36<08:31, 113kB/s]
66%|██████▌ | 113M/170M [17:37<07:55, 122kB/s]
66%|██████▌ | 113M/170M [17:37<08:25, 114kB/s]
66%|██████▌ | 113M/170M [17:37<08:06, 119kB/s]
66%|██████▌ | 113M/170M [17:38<08:31, 113kB/s]
66%|██████▌ | 113M/170M [17:38<08:49, 109kB/s]
66%|██████▌ | 113M/170M [17:38<08:37, 111kB/s]
66%|██████▌ | 113M/170M [17:38<08:25, 114kB/s]
66%|██████▋ | 113M/170M [17:39<12:03, 79.5kB/s]
66%|██████▋ | 113M/170M [17:40<13:21, 71.7kB/s]
66%|██████▋ | 113M/170M [17:40<12:34, 76.1kB/s]
66%|██████▋ | 113M/170M [17:40<12:25, 77.0kB/s]
66%|██████▋ | 113M/170M [17:41<11:08, 85.9kB/s]
66%|██████▋ | 113M/170M [17:41<11:11, 85.4kB/s]
66%|██████▋ | 113M/170M [17:41<10:06, 94.5kB/s]
66%|██████▋ | 113M/170M [17:42<09:51, 96.9kB/s]
66%|██████▋ | 113M/170M [17:42<10:06, 94.3kB/s]
66%|██████▋ | 113M/170M [17:42<09:30, 100kB/s]
66%|██████▋ | 113M/170M [17:43<08:55, 107kB/s]
66%|██████▋ | 113M/170M [17:43<09:06, 105kB/s]
66%|██████▋ | 113M/170M [17:43<08:10, 116kB/s]
67%|██████▋ | 113M/170M [17:43<07:48, 122kB/s]
67%|██████▋ | 113M/170M [17:44<07:55, 120kB/s]
67%|██████▋ | 113M/170M [17:44<07:19, 130kB/s]
67%|██████▋ | 114M/170M [17:44<07:28, 127kB/s]
67%|██████▋ | 114M/170M [17:44<07:59, 119kB/s]
67%|██████▋ | 114M/170M [17:45<14:06, 67.2kB/s]
67%|██████▋ | 114M/170M [17:46<14:50, 63.9kB/s]
67%|██████▋ | 114M/170M [17:47<14:39, 64.6kB/s]
67%|██████▋ | 114M/170M [17:47<17:48, 53.2kB/s]
67%|██████▋ | 114M/170M [17:48<17:14, 54.9kB/s]
67%|██████▋ | 114M/170M [17:48<14:04, 67.2kB/s]
67%|██████▋ | 114M/170M [17:48<11:21, 83.2kB/s]
67%|██████▋ | 114M/170M [17:49<09:57, 94.9kB/s]
67%|██████▋ | 114M/170M [17:49<08:51, 107kB/s]
67%|██████▋ | 114M/170M [17:49<08:33, 110kB/s]
67%|██████▋ | 114M/170M [17:49<08:02, 117kB/s]
67%|██████▋ | 114M/170M [17:50<07:42, 122kB/s]
67%|██████▋ | 114M/170M [17:50<07:15, 130kB/s]
67%|██████▋ | 114M/170M [17:50<06:48, 138kB/s]
67%|██████▋ | 114M/170M [17:50<07:12, 131kB/s]
67%|██████▋ | 114M/170M [17:51<07:12, 130kB/s]
67%|██████▋ | 114M/170M [17:51<07:10, 131kB/s]
67%|██████▋ | 114M/170M [17:51<06:47, 138kB/s]
67%|██████▋ | 114M/170M [17:51<06:44, 139kB/s]
67%|██████▋ | 114M/170M [17:51<06:24, 147kB/s]
67%|██████▋ | 114M/170M [17:52<06:11, 151kB/s]
67%|██████▋ | 114M/170M [17:52<06:09, 152kB/s]
67%|██████▋ | 114M/170M [17:52<05:49, 161kB/s]
67%|██████▋ | 114M/170M [17:52<05:52, 159kB/s]
67%|██████▋ | 114M/170M [17:52<06:22, 147kB/s]
67%|██████▋ | 114M/170M [17:53<06:22, 147kB/s]
67%|██████▋ | 114M/170M [17:53<06:08, 152kB/s]
67%|██████▋ | 114M/170M [17:53<06:06, 153kB/s]
67%|██████▋ | 114M/170M [17:53<05:48, 160kB/s]
67%|██████▋ | 115M/170M [17:54<05:58, 156kB/s]
67%|██████▋ | 115M/170M [17:54<05:49, 160kB/s]
67%|██████▋ | 115M/170M [17:54<06:15, 149kB/s]
67%|██████▋ | 115M/170M [17:54<06:04, 153kB/s]
67%|██████▋ | 115M/170M [17:54<06:35, 141kB/s]
67%|██████▋ | 115M/170M [17:55<06:59, 133kB/s]
67%|██████▋ | 115M/170M [17:55<06:35, 141kB/s]
67%|██████▋ | 115M/170M [17:55<06:22, 146kB/s]
67%|██████▋ | 115M/170M [17:55<06:14, 149kB/s]
67%|██████▋ | 115M/170M [17:56<06:32, 142kB/s]
67%|██████▋ | 115M/170M [17:56<06:30, 142kB/s]
67%|██████▋ | 115M/170M [17:56<06:21, 146kB/s]
67%|██████▋ | 115M/170M [17:56<06:04, 153kB/s]
67%|██████▋ | 115M/170M [17:56<06:16, 148kB/s]
67%|██████▋ | 115M/170M [17:57<05:55, 156kB/s]
67%|██████▋ | 115M/170M [17:57<05:56, 156kB/s]
67%|██████▋ | 115M/170M [17:57<06:37, 139kB/s]
67%|██████▋ | 115M/170M [17:57<06:31, 142kB/s]
68%|██████▊ | 115M/170M [17:58<06:25, 144kB/s]
68%|██████▊ | 115M/170M [17:58<06:18, 146kB/s]
68%|██████▊ | 115M/170M [17:58<06:01, 153kB/s]
68%|██████▊ | 115M/170M [17:58<06:30, 142kB/s]
68%|██████▊ | 115M/170M [17:58<05:43, 161kB/s]
68%|██████▊ | 115M/170M [17:59<06:01, 153kB/s]
68%|██████▊ | 115M/170M [17:59<06:00, 153kB/s]
68%|██████▊ | 115M/170M [17:59<06:18, 146kB/s]
68%|██████▊ | 115M/170M [17:59<06:25, 143kB/s]
68%|██████▊ | 115M/170M [18:00<06:28, 142kB/s]
68%|██████▊ | 115M/170M [18:00<06:23, 144kB/s]
68%|██████▊ | 115M/170M [18:00<06:23, 144kB/s]
68%|██████▊ | 116M/170M [18:00<06:05, 150kB/s]
68%|██████▊ | 116M/170M [18:00<06:24, 143kB/s]
68%|██████▊ | 116M/170M [18:01<05:36, 163kB/s]
68%|██████▊ | 116M/170M [18:01<05:51, 156kB/s]
68%|██████▊ | 116M/170M [18:01<05:50, 157kB/s]
68%|██████▊ | 116M/170M [18:01<05:52, 156kB/s]
68%|██████▊ | 116M/170M [18:01<06:02, 151kB/s]
68%|██████▊ | 116M/170M [18:02<06:27, 141kB/s]
68%|██████▊ | 116M/170M [18:02<06:17, 145kB/s]
68%|██████▊ | 116M/170M [18:02<06:15, 146kB/s]
68%|██████▊ | 116M/170M [18:02<06:13, 146kB/s]
68%|██████▊ | 116M/170M [18:03<06:25, 142kB/s]
68%|██████▊ | 116M/170M [18:03<06:16, 145kB/s]
68%|██████▊ | 116M/170M [18:03<06:22, 143kB/s]
68%|██████▊ | 116M/170M [18:03<06:37, 137kB/s]
68%|██████▊ | 116M/170M [18:04<06:19, 144kB/s]
68%|██████▊ | 116M/170M [18:04<06:34, 138kB/s]
68%|██████▊ | 116M/170M [18:04<06:49, 133kB/s]
68%|██████▊ | 116M/170M [18:04<06:21, 143kB/s]
68%|██████▊ | 116M/170M [18:05<06:13, 146kB/s]
68%|██████▊ | 116M/170M [18:05<06:12, 146kB/s]
68%|██████▊ | 116M/170M [18:05<06:22, 142kB/s]
68%|██████▊ | 116M/170M [18:05<05:50, 155kB/s]
68%|██████▊ | 116M/170M [18:05<06:02, 150kB/s]
68%|██████▊ | 116M/170M [18:06<05:48, 156kB/s]
68%|██████▊ | 116M/170M [18:06<06:08, 147kB/s]
68%|██████▊ | 116M/170M [18:06<06:03, 149kB/s]
68%|██████▊ | 116M/170M [18:06<06:24, 141kB/s]
68%|██████▊ | 116M/170M [18:07<06:12, 145kB/s]
68%|██████▊ | 116M/170M [18:07<06:01, 150kB/s]
68%|██████▊ | 116M/170M [18:07<05:48, 155kB/s]
68%|██████▊ | 117M/170M [18:08<11:51, 75.8kB/s]
68%|██████▊ | 117M/170M [18:09<15:56, 56.4kB/s]
68%|██████▊ | 117M/170M [18:09<14:00, 64.2kB/s]
68%|██████▊ | 117M/170M [18:09<11:45, 76.4kB/s]
68%|██████▊ | 117M/170M [18:10<09:46, 91.8kB/s]
68%|██████▊ | 117M/170M [18:10<08:44, 103kB/s]
68%|██████▊ | 117M/170M [18:10<07:57, 113kB/s]
68%|██████▊ | 117M/170M [18:10<07:48, 115kB/s]
68%|██████▊ | 117M/170M [18:10<07:12, 124kB/s]
69%|██████▊ | 117M/170M [18:11<07:05, 126kB/s]
69%|██████▊ | 117M/170M [18:11<06:17, 142kB/s]
69%|██████▊ | 117M/170M [18:11<06:06, 146kB/s]
69%|██████▊ | 117M/170M [18:11<06:04, 147kB/s]
69%|██████▊ | 117M/170M [18:12<05:50, 153kB/s]
69%|██████▊ | 117M/170M [18:12<05:55, 151kB/s]
69%|██████▊ | 117M/170M [18:12<05:51, 152kB/s]
69%|██████▊ | 117M/170M [18:12<06:07, 145kB/s]
69%|██████▊ | 117M/170M [18:12<06:17, 142kB/s]
69%|██████▊ | 117M/170M [18:13<06:05, 146kB/s]
69%|██████▊ | 117M/170M [18:13<06:52, 129kB/s]
69%|██████▊ | 117M/170M [18:13<06:45, 132kB/s]
69%|██████▊ | 117M/170M [18:13<06:53, 129kB/s]
69%|██████▉ | 117M/170M [18:14<06:30, 136kB/s]
69%|██████▉ | 117M/170M [18:14<06:04, 146kB/s]
69%|██████▉ | 117M/170M [18:15<09:15, 95.7kB/s]
69%|██████▉ | 117M/170M [18:15<09:12, 96.3kB/s]
69%|██████▉ | 117M/170M [18:15<09:01, 98.2kB/s]
69%|██████▉ | 117M/170M [18:16<12:27, 71.0kB/s]
69%|██████▉ | 117M/170M [18:17<13:35, 65.1kB/s]
69%|██████▉ | 117M/170M [18:17<12:12, 72.3kB/s]
69%|██████▉ | 118M/170M [18:17<10:53, 81.1kB/s]
69%|██████▉ | 118M/170M [18:18<10:49, 81.6kB/s]
69%|██████▉ | 118M/170M [18:18<10:15, 86.0kB/s]
69%|██████▉ | 118M/170M [18:18<09:41, 90.9kB/s]
69%|██████▉ | 118M/170M [18:18<09:10, 96.0kB/s]
69%|██████▉ | 118M/170M [18:19<08:56, 98.5kB/s]
69%|██████▉ | 118M/170M [18:19<09:14, 95.3kB/s]
69%|██████▉ | 118M/170M [18:20<09:26, 93.2kB/s]
69%|██████▉ | 118M/170M [18:20<10:12, 86.1kB/s]
69%|██████▉ | 118M/170M [18:20<10:35, 83.0kB/s]
69%|██████▉ | 118M/170M [18:21<15:56, 55.1kB/s]
69%|██████▉ | 118M/170M [18:22<18:42, 46.9kB/s]
69%|██████▉ | 118M/170M [18:23<15:47, 55.5kB/s]
69%|██████▉ | 118M/170M [18:23<13:52, 63.1kB/s]
69%|██████▉ | 118M/170M [18:24<13:09, 66.5kB/s]
69%|██████▉ | 118M/170M [18:24<14:19, 61.1kB/s]
69%|██████▉ | 118M/170M [18:25<14:11, 61.6kB/s]
69%|██████▉ | 118M/170M [18:25<16:03, 54.4kB/s]
69%|██████▉ | 118M/170M [18:26<13:28, 64.8kB/s]
69%|██████▉ | 118M/170M [18:26<11:54, 73.3kB/s]
69%|██████▉ | 118M/170M [18:26<10:25, 83.7kB/s]
69%|██████▉ | 118M/170M [18:27<09:02, 96.4kB/s]
69%|██████▉ | 118M/170M [18:27<08:26, 103kB/s]
69%|██████▉ | 118M/170M [18:27<07:51, 111kB/s]
69%|██████▉ | 118M/170M [18:27<07:38, 114kB/s]
69%|██████▉ | 118M/170M [18:28<07:10, 121kB/s]
69%|██████▉ | 118M/170M [18:28<07:03, 123kB/s]
69%|██████▉ | 118M/170M [18:28<06:57, 125kB/s]
69%|██████▉ | 118M/170M [18:28<06:33, 132kB/s]
69%|██████▉ | 118M/170M [18:29<07:07, 122kB/s]
69%|██████▉ | 118M/170M [18:29<06:43, 129kB/s]
70%|██████▉ | 119M/170M [18:29<06:53, 126kB/s]
70%|██████▉ | 119M/170M [18:29<06:20, 137kB/s]
70%|██████▉ | 119M/170M [18:29<06:11, 140kB/s]
70%|██████▉ | 119M/170M [18:30<06:35, 131kB/s]
70%|██████▉ | 119M/170M [18:30<05:43, 151kB/s]
70%|██████▉ | 119M/170M [18:30<06:06, 141kB/s]
70%|██████▉ | 119M/170M [18:30<05:48, 148kB/s]
70%|██████▉ | 119M/170M [18:31<05:38, 153kB/s]
70%|██████▉ | 119M/170M [18:31<06:10, 139kB/s]
70%|██████▉ | 119M/170M [18:31<06:02, 143kB/s]
70%|██████▉ | 119M/170M [18:31<06:24, 134kB/s]
70%|██████▉ | 119M/170M [18:32<06:34, 131kB/s]
70%|██████▉ | 119M/170M [18:32<05:50, 147kB/s]
70%|██████▉ | 119M/170M [18:32<06:09, 140kB/s]
70%|██████▉ | 119M/170M [18:32<06:01, 143kB/s]
70%|██████▉ | 119M/170M [18:32<05:57, 144kB/s]
70%|██████▉ | 119M/170M [18:33<06:20, 135kB/s]
70%|██████▉ | 119M/170M [18:33<05:57, 144kB/s]
70%|██████▉ | 119M/170M [18:33<06:21, 135kB/s]
70%|██████▉ | 119M/170M [18:34<06:48, 126kB/s]
70%|██████▉ | 119M/170M [18:34<05:54, 145kB/s]
70%|██████▉ | 119M/170M [18:34<07:18, 117kB/s]
70%|██████▉ | 119M/170M [18:34<07:24, 115kB/s]
70%|██████▉ | 119M/170M [18:35<07:26, 115kB/s]
70%|██████▉ | 119M/170M [18:35<07:13, 118kB/s]
70%|██████▉ | 119M/170M [18:35<07:00, 122kB/s]
70%|███████ | 119M/170M [18:36<07:34, 112kB/s]
70%|███████ | 119M/170M [18:36<07:41, 111kB/s]
70%|███████ | 119M/170M [18:36<08:47, 96.8kB/s]
70%|███████ | 119M/170M [18:37<10:03, 84.6kB/s]
70%|███████ | 120M/170M [18:38<13:05, 64.9kB/s]
70%|███████ | 120M/170M [18:38<11:09, 76.2kB/s]
70%|███████ | 120M/170M [18:38<10:14, 82.8kB/s]
70%|███████ | 120M/170M [18:38<09:50, 86.2kB/s]
70%|███████ | 120M/170M [18:39<08:19, 102kB/s]
70%|███████ | 120M/170M [18:39<08:07, 104kB/s]
70%|███████ | 120M/170M [18:39<08:38, 97.9kB/s]
70%|███████ | 120M/170M [18:40<10:05, 83.8kB/s]
70%|███████ | 120M/170M [18:40<09:32, 88.6kB/s]
70%|███████ | 120M/170M [18:40<08:53, 95.1kB/s]
70%|███████ | 120M/170M [18:41<08:46, 96.2kB/s]
70%|███████ | 120M/170M [18:41<08:41, 97.2kB/s]
70%|███████ | 120M/170M [18:41<08:54, 94.6kB/s]
70%|███████ | 120M/170M [18:42<08:20, 101kB/s]
70%|███████ | 120M/170M [18:42<09:38, 87.4kB/s]
70%|███████ | 120M/170M [18:43<09:17, 90.7kB/s]
70%|███████ | 120M/170M [18:43<08:44, 96.3kB/s]
70%|███████ | 120M/170M [18:43<08:15, 102kB/s]
70%|███████ | 120M/170M [18:43<07:59, 105kB/s]
70%|███████ | 120M/170M [18:44<07:50, 107kB/s]
70%|███████ | 120M/170M [18:44<09:00, 93.1kB/s]
70%|███████ | 120M/170M [18:44<08:26, 99.3kB/s]
71%|███████ | 120M/170M [18:45<08:36, 97.3kB/s]
71%|███████ | 120M/170M [18:45<07:55, 106kB/s]
71%|███████ | 120M/170M [18:45<07:46, 108kB/s]
71%|███████ | 120M/170M [18:46<07:20, 114kB/s]
71%|███████ | 120M/170M [18:46<07:20, 114kB/s]
71%|███████ | 120M/170M [18:46<07:26, 112kB/s]
71%|███████ | 120M/170M [18:46<07:04, 118kB/s]
71%|███████ | 120M/170M [18:47<06:47, 123kB/s]
71%|███████ | 120M/170M [18:47<07:09, 116kB/s]
71%|███████ | 121M/170M [18:47<06:50, 122kB/s]
71%|███████ | 121M/170M [18:48<06:55, 120kB/s]
71%|███████ | 121M/170M [18:48<07:00, 119kB/s]
71%|███████ | 121M/170M [18:48<06:48, 122kB/s]
71%|███████ | 121M/170M [18:48<06:14, 133kB/s]
71%|███████ | 121M/170M [18:48<06:07, 136kB/s]
71%|███████ | 121M/170M [18:49<06:16, 132kB/s]
71%|███████ | 121M/170M [18:49<05:55, 140kB/s]
71%|███████ | 121M/170M [18:49<06:08, 135kB/s]
71%|███████ | 121M/170M [18:49<06:15, 132kB/s]
71%|███████ | 121M/170M [18:50<06:59, 118kB/s]
71%|███████ | 121M/170M [18:50<06:51, 121kB/s]
71%|███████ | 121M/170M [18:50<06:35, 125kB/s]
71%|███████ | 121M/170M [18:51<06:46, 122kB/s]
71%|███████ | 121M/170M [18:51<06:56, 119kB/s]
71%|███████ | 121M/170M [18:51<07:52, 105kB/s]
71%|███████ | 121M/170M [18:52<08:24, 98.1kB/s]
71%|███████ | 121M/170M [18:52<08:36, 95.7kB/s]
71%|███████ | 121M/170M [18:52<08:48, 93.5kB/s]
71%|███████ | 121M/170M [18:53<09:44, 84.4kB/s]
71%|███████ | 121M/170M [18:53<11:19, 72.6kB/s]
71%|███████ | 121M/170M [18:54<11:24, 72.0kB/s]
71%|███████ | 121M/170M [18:54<10:13, 80.3kB/s]
71%|███████ | 121M/170M [18:55<10:00, 81.9kB/s]
71%|███████ | 121M/170M [18:55<11:15, 72.8kB/s]
71%|███████ | 121M/170M [18:56<10:18, 79.5kB/s]
71%|███████ | 121M/170M [18:56<09:13, 88.8kB/s]
71%|███████ | 121M/170M [18:56<08:24, 97.4kB/s]
71%|███████ | 121M/170M [18:56<07:53, 104kB/s]
71%|███████ | 121M/170M [18:57<07:36, 107kB/s]
71%|███████▏ | 122M/170M [18:57<07:11, 113kB/s]
71%|███████▏ | 122M/170M [18:57<07:32, 108kB/s]
71%|███████▏ | 122M/170M [18:57<06:54, 118kB/s]
71%|███████▏ | 122M/170M [18:58<06:52, 119kB/s]
71%|███████▏ | 122M/170M [18:58<06:49, 119kB/s]
71%|███████▏ | 122M/170M [18:58<06:55, 118kB/s]
71%|███████▏ | 122M/170M [18:58<06:45, 120kB/s]
71%|███████▏ | 122M/170M [18:59<06:25, 126kB/s]
71%|███████▏ | 122M/170M [18:59<06:12, 131kB/s]
71%|███████▏ | 122M/170M [18:59<07:16, 111kB/s]
71%|███████▏ | 122M/170M [19:00<09:43, 83.4kB/s]
71%|███████▏ | 122M/170M [19:01<14:19, 56.6kB/s]
71%|███████▏ | 122M/170M [19:01<13:08, 61.7kB/s]
72%|███████▏ | 122M/170M [19:02<10:50, 74.6kB/s]
72%|███████▏ | 122M/170M [19:02<09:47, 82.7kB/s]
72%|███████▏ | 122M/170M [19:02<09:35, 84.3kB/s]
72%|███████▏ | 122M/170M [19:03<11:28, 70.4kB/s]
72%|███████▏ | 122M/170M [19:03<09:53, 81.6kB/s]
72%|███████▏ | 122M/170M [19:03<08:47, 91.8kB/s]
72%|███████▏ | 122M/170M [19:04<08:02, 100kB/s]
72%|███████▏ | 122M/170M [19:04<07:12, 112kB/s]
72%|███████▏ | 122M/170M [19:04<07:32, 107kB/s]
72%|███████▏ | 122M/170M [19:05<08:30, 94.6kB/s]
72%|███████▏ | 122M/170M [19:05<07:43, 104kB/s]
72%|███████▏ | 122M/170M [19:05<07:41, 104kB/s]
72%|███████▏ | 122M/170M [19:06<07:36, 105kB/s]
72%|███████▏ | 122M/170M [19:06<07:37, 105kB/s]
72%|███████▏ | 122M/170M [19:06<07:44, 104kB/s]
72%|███████▏ | 122M/170M [19:06<07:44, 104kB/s]
72%|███████▏ | 122M/170M [19:07<07:29, 107kB/s]
72%|███████▏ | 122M/170M [19:07<07:50, 102kB/s]
72%|███████▏ | 123M/170M [19:07<06:57, 115kB/s]
72%|███████▏ | 123M/170M [19:08<07:12, 111kB/s]
72%|███████▏ | 123M/170M [19:08<08:50, 90.3kB/s]
72%|███████▏ | 123M/170M [19:08<07:39, 104kB/s]
72%|███████▏ | 123M/170M [19:09<07:46, 103kB/s]
72%|███████▏ | 123M/170M [19:09<07:53, 101kB/s]
72%|███████▏ | 123M/170M [19:09<07:27, 107kB/s]
72%|███████▏ | 123M/170M [19:10<07:07, 112kB/s]
72%|███████▏ | 123M/170M [19:10<06:56, 115kB/s]
72%|███████▏ | 123M/170M [19:10<06:48, 117kB/s]
72%|███████▏ | 123M/170M [19:10<06:43, 118kB/s]
72%|███████▏ | 123M/170M [19:11<06:55, 115kB/s]
72%|███████▏ | 123M/170M [19:11<06:52, 115kB/s]
72%|███████▏ | 123M/170M [19:11<06:34, 121kB/s]
72%|███████▏ | 123M/170M [19:12<06:42, 118kB/s]
72%|███████▏ | 123M/170M [19:12<06:25, 123kB/s]
72%|███████▏ | 123M/170M [19:12<06:12, 127kB/s]
72%|███████▏ | 123M/170M [19:12<05:59, 132kB/s]
72%|███████▏ | 123M/170M [19:13<06:35, 120kB/s]
72%|███████▏ | 123M/170M [19:13<07:03, 112kB/s]
72%|███████▏ | 123M/170M [19:13<06:46, 117kB/s]
72%|███████▏ | 123M/170M [19:13<06:32, 120kB/s]
72%|███████▏ | 123M/170M [19:14<07:16, 108kB/s]
72%|███████▏ | 123M/170M [19:14<06:49, 115kB/s]
72%|███████▏ | 123M/170M [19:14<06:58, 113kB/s]
72%|███████▏ | 123M/170M [19:15<06:47, 116kB/s]
72%|███████▏ | 123M/170M [19:15<06:46, 116kB/s]
72%|███████▏ | 123M/170M [19:15<06:26, 122kB/s]
72%|███████▏ | 123M/170M [19:15<06:48, 115kB/s]
72%|███████▏ | 123M/170M [19:16<06:30, 121kB/s]
72%|███████▏ | 124M/170M [19:16<06:30, 120kB/s]
72%|███████▏ | 124M/170M [19:16<06:47, 115kB/s]
72%|███████▏ | 124M/170M [19:17<07:27, 105kB/s]
72%|███████▏ | 124M/170M [19:17<06:59, 112kB/s]
73%|███████▎ | 124M/170M [19:17<06:34, 119kB/s]
73%|███████▎ | 124M/170M [19:17<06:17, 124kB/s]
73%|███████▎ | 124M/170M [19:18<06:22, 122kB/s]
73%|███████▎ | 124M/170M [19:18<06:43, 116kB/s]
73%|███████▎ | 124M/170M [19:18<07:57, 97.8kB/s]
73%|███████▎ | 124M/170M [19:19<08:53, 87.5kB/s]
73%|███████▎ | 124M/170M [19:19<09:36, 80.9kB/s]
73%|███████▎ | 124M/170M [19:20<09:07, 85.1kB/s]
73%|███████▎ | 124M/170M [19:20<11:19, 68.5kB/s]
73%|███████▎ | 124M/170M [19:21<12:10, 63.8kB/s]
73%|███████▎ | 124M/170M [19:21<11:13, 69.1kB/s]
73%|███████▎ | 124M/170M [19:22<09:29, 81.7kB/s]
73%|███████▎ | 124M/170M [19:22<08:47, 88.1kB/s]
73%|███████▎ | 124M/170M [19:22<07:51, 98.5kB/s]
73%|███████▎ | 124M/170M [19:22<07:33, 102kB/s]
73%|███████▎ | 124M/170M [19:23<07:42, 100kB/s]
73%|███████▎ | 124M/170M [19:23<08:30, 90.8kB/s]
73%|███████▎ | 124M/170M [19:24<08:58, 85.9kB/s]
73%|███████▎ | 124M/170M [19:24<08:26, 91.3kB/s]
73%|███████▎ | 124M/170M [19:24<08:41, 88.7kB/s]
73%|███████▎ | 124M/170M [19:25<08:17, 92.8kB/s]
73%|███████▎ | 124M/170M [19:25<08:11, 93.9kB/s]
73%|███████▎ | 124M/170M [19:25<08:11, 93.8kB/s]
73%|███████▎ | 124M/170M [19:26<07:27, 103kB/s]
73%|███████▎ | 124M/170M [19:26<07:12, 106kB/s]
73%|███████▎ | 124M/170M [19:26<07:18, 105kB/s]
73%|███████▎ | 124M/170M [19:27<08:34, 89.4kB/s]
73%|███████▎ | 125M/170M [19:27<08:10, 93.8kB/s]
73%|███████▎ | 125M/170M [19:27<07:32, 102kB/s]
73%|███████▎ | 125M/170M [19:28<07:45, 98.7kB/s]
73%|███████▎ | 125M/170M [19:28<07:49, 97.8kB/s]
73%|███████▎ | 125M/170M [19:28<08:41, 87.9kB/s]
73%|███████▎ | 125M/170M [19:29<08:32, 89.5kB/s]
73%|███████▎ | 125M/170M [19:29<08:33, 89.2kB/s]
73%|███████▎ | 125M/170M [19:29<08:13, 92.8kB/s]
73%|███████▎ | 125M/170M [19:30<07:53, 96.5kB/s]
73%|███████▎ | 125M/170M [19:30<08:28, 89.9kB/s]
73%|███████▎ | 125M/170M [19:31<08:22, 90.8kB/s]
73%|███████▎ | 125M/170M [19:31<09:07, 83.3kB/s]
73%|███████▎ | 125M/170M [19:31<08:42, 87.2kB/s]
73%|███████▎ | 125M/170M [19:32<08:29, 89.5kB/s]
73%|███████▎ | 125M/170M [19:32<07:47, 97.5kB/s]
73%|███████▎ | 125M/170M [19:32<07:12, 105kB/s]
73%|███████▎ | 125M/170M [19:32<07:07, 106kB/s]
73%|███████▎ | 125M/170M [19:33<07:03, 107kB/s]
73%|███████▎ | 125M/170M [19:33<06:42, 113kB/s]
73%|███████▎ | 125M/170M [19:33<06:39, 113kB/s]
73%|███████▎ | 125M/170M [19:34<07:04, 107kB/s]
73%|███████▎ | 125M/170M [19:35<11:16, 67.0kB/s]
73%|███████▎ | 125M/170M [19:35<13:33, 55.6kB/s]
73%|███████▎ | 125M/170M [19:36<13:07, 57.5kB/s]
73%|███████▎ | 125M/170M [19:36<11:49, 63.7kB/s]
74%|███████▎ | 125M/170M [19:37<10:58, 68.6kB/s]
74%|███████▎ | 125M/170M [19:37<12:52, 58.4kB/s]
74%|███████▎ | 125M/170M [19:38<14:56, 50.3kB/s]
74%|███████▎ | 125M/170M [19:39<14:10, 53.0kB/s]
74%|███████▎ | 125M/170M [19:39<14:13, 52.8kB/s]
74%|███████▎ | 126M/170M [19:40<12:22, 60.6kB/s]
74%|███████▎ | 126M/170M [19:40<10:31, 71.2kB/s]
74%|███████▎ | 126M/170M [19:41<10:23, 72.1kB/s]
74%|███████▎ | 126M/170M [19:41<10:12, 73.3kB/s]
74%|███████▎ | 126M/170M [19:42<10:39, 70.1kB/s]
74%|███████▎ | 126M/170M [19:42<09:33, 78.2kB/s]
74%|███████▎ | 126M/170M [19:42<09:04, 82.3kB/s]
74%|███████▎ | 126M/170M [19:43<09:05, 82.0kB/s]
74%|███████▍ | 126M/170M [19:43<09:23, 79.4kB/s]
74%|███████▍ | 126M/170M [19:43<08:48, 84.5kB/s]
74%|███████▍ | 126M/170M [19:44<08:26, 88.2kB/s]
74%|███████▍ | 126M/170M [19:44<07:43, 96.3kB/s]
74%|███████▍ | 126M/170M [19:44<07:37, 97.5kB/s]
74%|███████▍ | 126M/170M [19:45<07:36, 97.6kB/s]
74%|███████▍ | 126M/170M [19:45<09:16, 80.0kB/s]
74%|███████▍ | 126M/170M [19:45<08:27, 87.6kB/s]
74%|███████▍ | 126M/170M [19:46<08:22, 88.5kB/s]
74%|███████▍ | 126M/170M [19:46<08:31, 86.9kB/s]
74%|███████▍ | 126M/170M [19:47<08:06, 91.4kB/s]
74%|███████▍ | 126M/170M [19:47<07:55, 93.4kB/s]
74%|███████▍ | 126M/170M [19:47<07:34, 97.7kB/s]
74%|███████▍ | 126M/170M [19:47<07:11, 103kB/s]
74%|███████▍ | 126M/170M [19:48<07:02, 105kB/s]
74%|███████▍ | 126M/170M [19:48<07:12, 102kB/s]
74%|███████▍ | 126M/170M [19:48<06:45, 109kB/s]
74%|███████▍ | 126M/170M [19:49<07:21, 100kB/s]
74%|███████▍ | 126M/170M [19:49<07:11, 102kB/s]
74%|███████▍ | 126M/170M [19:49<07:23, 99.4kB/s]
74%|███████▍ | 126M/170M [19:50<06:55, 106kB/s]
74%|███████▍ | 126M/170M [19:50<07:08, 103kB/s]
74%|███████▍ | 126M/170M [19:50<07:30, 97.8kB/s]
74%|███████▍ | 127M/170M [19:51<07:38, 95.9kB/s]
74%|███████▍ | 127M/170M [19:51<06:57, 105kB/s]
74%|███████▍ | 127M/170M [19:51<06:52, 106kB/s]
74%|███████▍ | 127M/170M [19:52<07:19, 99.8kB/s]
74%|███████▍ | 127M/170M [19:52<07:26, 98.3kB/s]
74%|███████▍ | 127M/170M [19:52<06:52, 106kB/s]
74%|███████▍ | 127M/170M [19:52<06:18, 116kB/s]
74%|███████▍ | 127M/170M [19:53<06:30, 112kB/s]
74%|███████▍ | 127M/170M [19:53<06:27, 113kB/s]
74%|███████▍ | 127M/170M [19:53<07:09, 102kB/s]
74%|███████▍ | 127M/170M [19:54<07:15, 100kB/s]
74%|███████▍ | 127M/170M [19:54<07:40, 94.6kB/s]
74%|███████▍ | 127M/170M [19:54<07:22, 98.4kB/s]
74%|███████▍ | 127M/170M [19:55<08:01, 90.4kB/s]
74%|███████▍ | 127M/170M [19:55<07:54, 91.6kB/s]
74%|███████▍ | 127M/170M [19:56<07:30, 96.6kB/s]
75%|███████▍ | 127M/170M [19:56<08:02, 90.1kB/s]
75%|███████▍ | 127M/170M [19:56<07:52, 91.9kB/s]
75%|███████▍ | 127M/170M [19:57<07:21, 98.3kB/s]
75%|███████▍ | 127M/170M [19:57<07:12, 100kB/s]
75%|███████▍ | 127M/170M [19:57<07:11, 100kB/s]
75%|███████▍ | 127M/170M [19:57<06:09, 117kB/s]
75%|███████▍ | 127M/170M [19:58<05:57, 121kB/s]
75%|███████▍ | 127M/170M [19:58<06:06, 118kB/s]
75%|███████▍ | 127M/170M [19:58<05:45, 125kB/s]
75%|███████▍ | 127M/170M [19:59<06:08, 117kB/s]
75%|███████▍ | 127M/170M [19:59<05:39, 127kB/s]
75%|███████▍ | 127M/170M [19:59<05:35, 128kB/s]
75%|███████▍ | 127M/170M [19:59<05:31, 130kB/s]
75%|███████▍ | 127M/170M [19:59<05:44, 125kB/s]
75%|███████▍ | 128M/170M [20:00<07:06, 101kB/s]
75%|███████▍ | 128M/170M [20:00<08:09, 87.8kB/s]
75%|███████▍ | 128M/170M [20:01<10:13, 70.0kB/s]
75%|███████▍ | 128M/170M [20:01<09:02, 79.0kB/s]
75%|███████▍ | 128M/170M [20:02<08:13, 86.9kB/s]
75%|███████▍ | 128M/170M [20:02<07:50, 91.0kB/s]
75%|███████▍ | 128M/170M [20:02<07:16, 98.1kB/s]
75%|███████▍ | 128M/170M [20:03<07:08, 99.9kB/s]
75%|███████▍ | 128M/170M [20:03<06:56, 103kB/s]
75%|███████▍ | 128M/170M [20:03<06:30, 109kB/s]
75%|███████▍ | 128M/170M [20:03<06:31, 109kB/s]
75%|███████▍ | 128M/170M [20:04<06:13, 114kB/s]
75%|███████▌ | 128M/170M [20:04<06:02, 118kB/s]
75%|███████▌ | 128M/170M [20:04<05:57, 119kB/s]
75%|███████▌ | 128M/170M [20:05<06:01, 118kB/s]
75%|███████▌ | 128M/170M [20:06<12:15, 57.8kB/s]
75%|███████▌ | 128M/170M [20:06<12:28, 56.8kB/s]
75%|███████▌ | 128M/170M [20:07<11:48, 59.9kB/s]
75%|███████▌ | 128M/170M [20:07<10:40, 66.2kB/s]
75%|███████▌ | 128M/170M [20:08<10:05, 69.9kB/s]
75%|███████▌ | 128M/170M [20:08<09:14, 76.4kB/s]
75%|███████▌ | 128M/170M [20:08<08:47, 80.1kB/s]
75%|███████▌ | 128M/170M [20:09<08:16, 85.2kB/s]
75%|███████▌ | 128M/170M [20:09<09:01, 78.1kB/s]
75%|███████▌ | 128M/170M [20:09<08:20, 84.3kB/s]
75%|███████▌ | 128M/170M [20:10<07:52, 89.3kB/s]
75%|███████▌ | 128M/170M [20:10<08:14, 85.3kB/s]
75%|███████▌ | 128M/170M [20:11<07:35, 92.6kB/s]
75%|███████▌ | 128M/170M [20:11<07:07, 98.4kB/s]
75%|███████▌ | 128M/170M [20:11<06:57, 101kB/s]
75%|███████▌ | 128M/170M [20:11<07:17, 96.0kB/s]
75%|███████▌ | 129M/170M [20:12<07:09, 97.8kB/s]
75%|███████▌ | 129M/170M [20:12<07:40, 91.2kB/s]
75%|███████▌ | 129M/170M [20:13<07:28, 93.4kB/s]
75%|███████▌ | 129M/170M [20:13<06:35, 106kB/s]
75%|███████▌ | 129M/170M [20:13<06:34, 106kB/s]
75%|███████▌ | 129M/170M [20:14<07:52, 88.6kB/s]
75%|███████▌ | 129M/170M [20:14<08:07, 85.8kB/s]
76%|███████▌ | 129M/170M [20:14<07:39, 90.9kB/s]
76%|███████▌ | 129M/170M [20:15<07:51, 88.5kB/s]
76%|███████▌ | 129M/170M [20:15<07:54, 87.8kB/s]
76%|███████▌ | 129M/170M [20:15<07:52, 88.1kB/s]
76%|███████▌ | 129M/170M [20:16<07:20, 94.5kB/s]
76%|███████▌ | 129M/170M [20:16<07:22, 93.9kB/s]
76%|███████▌ | 129M/170M [20:17<07:49, 88.5kB/s]
76%|███████▌ | 129M/170M [20:17<07:44, 89.4kB/s]
76%|███████▌ | 129M/170M [20:17<07:47, 88.7kB/s]
76%|███████▌ | 129M/170M [20:18<08:16, 83.5kB/s]
76%|███████▌ | 129M/170M [20:18<08:13, 84.0kB/s]
76%|███████▌ | 129M/170M [20:19<09:02, 76.3kB/s]
76%|███████▌ | 129M/170M [20:19<09:02, 76.3kB/s]
76%|███████▌ | 129M/170M [20:19<07:57, 86.6kB/s]
76%|███████▌ | 129M/170M [20:20<07:22, 93.3kB/s]
76%|███████▌ | 129M/170M [20:20<07:20, 93.6kB/s]
76%|███████▌ | 129M/170M [20:20<06:39, 103kB/s]
76%|███████▌ | 129M/170M [20:20<06:31, 105kB/s]
76%|███████▌ | 129M/170M [20:21<06:16, 109kB/s]
76%|███████▌ | 129M/170M [20:21<06:18, 109kB/s]
76%|███████▌ | 129M/170M [20:21<06:00, 114kB/s]
76%|███████▌ | 129M/170M [20:22<06:06, 112kB/s]
76%|███████▌ | 129M/170M [20:22<06:14, 110kB/s]
76%|███████▌ | 129M/170M [20:22<05:47, 118kB/s]
76%|███████▌ | 130M/170M [20:22<05:33, 123kB/s]
76%|███████▌ | 130M/170M [20:23<05:21, 127kB/s]
76%|███████▌ | 130M/170M [20:23<05:41, 120kB/s]
76%|███████▌ | 130M/170M [20:23<05:49, 117kB/s]
76%|███████▌ | 130M/170M [20:24<06:17, 108kB/s]
76%|███████▌ | 130M/170M [20:24<06:00, 113kB/s]
76%|███████▌ | 130M/170M [20:24<06:26, 106kB/s]
76%|███████▌ | 130M/170M [20:24<06:22, 107kB/s]
76%|███████▌ | 130M/170M [20:25<06:37, 102kB/s]
76%|███████▌ | 130M/170M [20:25<06:01, 112kB/s]
76%|███████▌ | 130M/170M [20:25<06:28, 104kB/s]
76%|███████▌ | 130M/170M [20:26<06:16, 108kB/s]
76%|███████▌ | 130M/170M [20:26<06:40, 101kB/s]
76%|███████▌ | 130M/170M [20:26<07:02, 96.1kB/s]
76%|███████▌ | 130M/170M [20:27<07:00, 96.3kB/s]
76%|███████▋ | 130M/170M [20:27<06:42, 100kB/s]
76%|███████▋ | 130M/170M [20:27<06:38, 101kB/s]
76%|███████▋ | 130M/170M [20:28<06:34, 102kB/s]
76%|███████▋ | 130M/170M [20:28<06:47, 99.1kB/s]
76%|███████▋ | 130M/170M [20:28<07:01, 95.6kB/s]
76%|███████▋ | 130M/170M [20:29<07:06, 94.4kB/s]
76%|███████▋ | 130M/170M [20:29<06:47, 99.0kB/s]
76%|███████▋ | 130M/170M [20:29<06:57, 96.5kB/s]
76%|███████▋ | 130M/170M [20:30<06:43, 99.6kB/s]
76%|███████▋ | 130M/170M [20:30<06:22, 105kB/s]
76%|███████▋ | 130M/170M [20:30<07:09, 93.5kB/s]
76%|███████▋ | 130M/170M [20:31<07:31, 88.8kB/s]
76%|███████▋ | 130M/170M [20:31<08:38, 77.3kB/s]
77%|███████▋ | 130M/170M [20:32<08:04, 82.7kB/s]
77%|███████▋ | 130M/170M [20:32<07:30, 88.9kB/s]
77%|███████▋ | 131M/170M [20:32<07:05, 94.0kB/s]
77%|███████▋ | 131M/170M [20:33<06:48, 97.8kB/s]
77%|███████▋ | 131M/170M [20:33<07:11, 92.4kB/s]
77%|███████▋ | 131M/170M [20:33<06:42, 99.0kB/s]
77%|███████▋ | 131M/170M [20:34<06:22, 104kB/s]
77%|███████▋ | 131M/170M [20:34<06:05, 109kB/s]
77%|███████▋ | 131M/170M [20:34<06:11, 107kB/s]
77%|███████▋ | 131M/170M [20:35<10:24, 63.7kB/s]
77%|███████▋ | 131M/170M [20:36<12:47, 51.8kB/s]
77%|███████▋ | 131M/170M [20:37<11:29, 57.5kB/s]
77%|███████▋ | 131M/170M [20:37<11:36, 56.9kB/s]
77%|███████▋ | 131M/170M [20:37<09:51, 66.9kB/s]
77%|███████▋ | 131M/170M [20:38<08:02, 82.0kB/s]
77%|███████▋ | 131M/170M [20:38<07:13, 91.3kB/s]
77%|███████▋ | 131M/170M [20:38<05:58, 110kB/s]
77%|███████▋ | 131M/170M [20:38<05:23, 122kB/s]
77%|███████▋ | 131M/170M [20:38<05:09, 127kB/s]
77%|███████▋ | 131M/170M [20:39<05:41, 115kB/s]
77%|███████▋ | 131M/170M [20:39<05:14, 125kB/s]
77%|███████▋ | 131M/170M [20:39<04:56, 133kB/s]
77%|███████▋ | 131M/170M [20:39<04:39, 141kB/s]
77%|███████▋ | 131M/170M [20:40<04:35, 142kB/s]
77%|███████▋ | 131M/170M [20:40<04:29, 145kB/s]
77%|███████▋ | 131M/170M [20:40<04:26, 147kB/s]
77%|███████▋ | 131M/170M [20:40<04:23, 148kB/s]
77%|███████▋ | 131M/170M [20:41<04:28, 146kB/s]
77%|███████▋ | 131M/170M [20:41<04:11, 155kB/s]
77%|███████▋ | 131M/170M [20:41<04:17, 152kB/s]
77%|███████▋ | 131M/170M [20:41<04:30, 144kB/s]
77%|███████▋ | 131M/170M [20:41<04:23, 148kB/s]
77%|███████▋ | 131M/170M [20:42<04:21, 149kB/s]
77%|███████▋ | 132M/170M [20:42<04:24, 147kB/s]
77%|███████▋ | 132M/170M [20:42<04:18, 151kB/s]
77%|███████▋ | 132M/170M [20:42<04:40, 139kB/s]
77%|███████▋ | 132M/170M [20:43<04:42, 138kB/s]
77%|███████▋ | 132M/170M [20:43<04:28, 145kB/s]
77%|███████▋ | 132M/170M [20:43<04:41, 138kB/s]
77%|███████▋ | 132M/170M [20:43<04:30, 143kB/s]
77%|███████▋ | 132M/170M [20:44<04:58, 130kB/s]
77%|███████▋ | 132M/170M [20:44<04:53, 132kB/s]
77%|███████▋ | 132M/170M [20:44<04:41, 137kB/s]
77%|███████▋ | 132M/170M [20:44<04:30, 143kB/s]
77%|███████▋ | 132M/170M [20:44<04:20, 148kB/s]
77%|███████▋ | 132M/170M [20:45<04:24, 146kB/s]
77%|███████▋ | 132M/170M [20:45<04:18, 149kB/s]
77%|███████▋ | 132M/170M [20:45<04:12, 152kB/s]
77%|███████▋ | 132M/170M [20:45<03:53, 165kB/s]
77%|███████▋ | 132M/170M [20:45<03:59, 161kB/s]
77%|███████▋ | 132M/170M [20:46<04:22, 146kB/s]
77%|███████▋ | 132M/170M [20:46<04:31, 141kB/s]
78%|███████▊ | 132M/170M [20:46<04:11, 153kB/s]
78%|███████▊ | 132M/170M [20:46<04:54, 130kB/s]
78%|███████▊ | 132M/170M [20:47<04:49, 132kB/s]
78%|███████▊ | 132M/170M [20:47<04:40, 136kB/s]
78%|███████▊ | 132M/170M [20:47<04:09, 153kB/s]
78%|███████▊ | 132M/170M [20:47<04:10, 152kB/s]
78%|███████▊ | 132M/170M [20:48<04:08, 153kB/s]
78%|███████▊ | 132M/170M [20:48<04:05, 155kB/s]
78%|███████▊ | 132M/170M [20:48<04:03, 157kB/s]
78%|███████▊ | 132M/170M [20:48<04:20, 146kB/s]
78%|███████▊ | 132M/170M [20:48<04:15, 149kB/s]
78%|███████▊ | 133M/170M [20:49<04:15, 148kB/s]
78%|███████▊ | 133M/170M [20:49<04:02, 157kB/s]
78%|███████▊ | 133M/170M [20:49<04:07, 153kB/s]
78%|███████▊ | 133M/170M [20:49<04:04, 155kB/s]
78%|███████▊ | 133M/170M [20:50<04:20, 146kB/s]
78%|███████▊ | 133M/170M [20:50<04:25, 142kB/s]
78%|███████▊ | 133M/170M [20:50<04:14, 148kB/s]
78%|███████▊ | 133M/170M [20:50<04:37, 136kB/s]
78%|███████▊ | 133M/170M [20:50<04:26, 142kB/s]
78%|███████▊ | 133M/170M [20:51<04:30, 139kB/s]
78%|███████▊ | 133M/170M [20:51<04:28, 140kB/s]
78%|███████▊ | 133M/170M [20:51<04:59, 126kB/s]
78%|███████▊ | 133M/170M [20:52<05:32, 113kB/s]
78%|███████▊ | 133M/170M [20:52<05:13, 120kB/s]
78%|███████▊ | 133M/170M [20:52<04:50, 129kB/s]
78%|███████▊ | 133M/170M [20:52<04:53, 128kB/s]
78%|███████▊ | 133M/170M [20:53<04:59, 125kB/s]
78%|███████▊ | 133M/170M [20:53<04:23, 142kB/s]
78%|███████▊ | 133M/170M [20:53<04:23, 142kB/s]
78%|███████▊ | 133M/170M [20:53<04:33, 137kB/s]
78%|███████▊ | 133M/170M [20:53<04:28, 139kB/s]
78%|███████▊ | 133M/170M [20:54<04:24, 141kB/s]
78%|███████▊ | 133M/170M [20:54<04:29, 138kB/s]
78%|███████▊ | 133M/170M [20:54<04:20, 143kB/s]
78%|███████▊ | 133M/170M [20:54<04:38, 133kB/s]
78%|███████▊ | 133M/170M [20:55<04:15, 146kB/s]
78%|███████▊ | 133M/170M [20:55<04:19, 143kB/s]
78%|███████▊ | 133M/170M [20:55<04:17, 144kB/s]
78%|███████▊ | 133M/170M [20:55<04:01, 153kB/s]
78%|███████▊ | 133M/170M [20:56<04:22, 141kB/s]
78%|███████▊ | 133M/170M [20:56<04:31, 136kB/s]
78%|███████▊ | 134M/170M [20:56<04:06, 150kB/s]
78%|███████▊ | 134M/170M [20:56<04:25, 139kB/s]
78%|███████▊ | 134M/170M [20:56<04:26, 138kB/s]
78%|███████▊ | 134M/170M [20:57<04:43, 130kB/s]
78%|███████▊ | 134M/170M [20:57<04:35, 134kB/s]
78%|███████▊ | 134M/170M [20:57<04:26, 138kB/s]
78%|███████▊ | 134M/170M [20:57<04:19, 141kB/s]
78%|███████▊ | 134M/170M [20:58<04:59, 123kB/s]
78%|███████▊ | 134M/170M [20:58<04:50, 126kB/s]
78%|███████▊ | 134M/170M [20:58<05:01, 122kB/s]
79%|███████▊ | 134M/170M [20:59<04:43, 129kB/s]
79%|███████▊ | 134M/170M [20:59<04:38, 131kB/s]
79%|███████▊ | 134M/170M [20:59<04:27, 137kB/s]
79%|███████▊ | 134M/170M [20:59<04:14, 143kB/s]
79%|███████▊ | 134M/170M [20:59<04:16, 142kB/s]
79%|███████▊ | 134M/170M [21:00<04:21, 140kB/s]
79%|███████▊ | 134M/170M [21:00<04:20, 140kB/s]
79%|███████▊ | 134M/170M [21:00<04:15, 142kB/s]
79%|███████▊ | 134M/170M [21:00<04:24, 137kB/s]
79%|███████▊ | 134M/170M [21:01<04:34, 133kB/s]
79%|███████▊ | 134M/170M [21:01<04:28, 135kB/s]
79%|███████▊ | 134M/170M [21:01<04:18, 140kB/s]
79%|███████▊ | 134M/170M [21:01<04:03, 149kB/s]
79%|███████▉ | 134M/170M [21:01<04:07, 147kB/s]
79%|███████▉ | 134M/170M [21:02<03:55, 154kB/s]
79%|███████▉ | 134M/170M [21:02<04:01, 150kB/s]
79%|███████▉ | 134M/170M [21:02<03:58, 151kB/s]
79%|███████▉ | 134M/170M [21:02<03:57, 152kB/s]
79%|███████▉ | 134M/170M [21:03<04:04, 147kB/s]
79%|███████▉ | 134M/170M [21:03<03:46, 159kB/s]
79%|███████▉ | 135M/170M [21:03<04:04, 147kB/s]
79%|███████▉ | 135M/170M [21:03<03:54, 153kB/s]
79%|███████▉ | 135M/170M [21:03<03:52, 155kB/s]
79%|███████▉ | 135M/170M [21:04<03:52, 154kB/s]
79%|███████▉ | 135M/170M [21:04<03:46, 158kB/s]
79%|███████▉ | 135M/170M [21:04<03:58, 150kB/s]
79%|███████▉ | 135M/170M [21:04<03:59, 149kB/s]
79%|███████▉ | 135M/170M [21:04<03:54, 153kB/s]
79%|███████▉ | 135M/170M [21:05<03:57, 151kB/s]
79%|███████▉ | 135M/170M [21:05<04:14, 140kB/s]
79%|███████▉ | 135M/170M [21:05<04:12, 141kB/s]
79%|███████▉ | 135M/170M [21:05<04:14, 140kB/s]
79%|███████▉ | 135M/170M [21:06<04:03, 146kB/s]
79%|███████▉ | 135M/170M [21:06<03:51, 153kB/s]
79%|███████▉ | 135M/170M [21:06<03:53, 152kB/s]
79%|███████▉ | 135M/170M [21:06<03:47, 156kB/s]
79%|███████▉ | 135M/170M [21:06<03:50, 154kB/s]
79%|███████▉ | 135M/170M [21:07<03:56, 150kB/s]
79%|███████▉ | 135M/170M [21:07<03:51, 153kB/s]
79%|███████▉ | 135M/170M [21:07<03:51, 153kB/s]
79%|███████▉ | 135M/170M [21:07<04:18, 136kB/s]
79%|███████▉ | 135M/170M [21:08<04:03, 145kB/s]
79%|███████▉ | 135M/170M [21:08<04:10, 141kB/s]
79%|███████▉ | 135M/170M [21:08<03:43, 158kB/s]
79%|███████▉ | 135M/170M [21:08<03:52, 151kB/s]
79%|███████▉ | 135M/170M [21:08<03:41, 159kB/s]
79%|███████▉ | 135M/170M [21:09<03:45, 156kB/s]
79%|███████▉ | 135M/170M [21:09<03:42, 158kB/s]
79%|███████▉ | 135M/170M [21:09<03:40, 159kB/s]
79%|███████▉ | 135M/170M [21:09<03:42, 157kB/s]
79%|███████▉ | 135M/170M [21:10<03:54, 149kB/s]
79%|███████▉ | 136M/170M [21:10<03:52, 151kB/s]
80%|███████▉ | 136M/170M [21:10<03:43, 156kB/s]
80%|███████▉ | 136M/170M [21:10<03:46, 154kB/s]
80%|███████▉ | 136M/170M [21:10<03:58, 146kB/s]
80%|███████▉ | 136M/170M [21:11<03:49, 152kB/s]
80%|███████▉ | 136M/170M [21:11<03:41, 157kB/s]
80%|███████▉ | 136M/170M [21:11<03:40, 158kB/s]
80%|███████▉ | 136M/170M [21:11<03:53, 149kB/s]
80%|███████▉ | 136M/170M [21:11<03:34, 162kB/s]
80%|███████▉ | 136M/170M [21:12<03:48, 152kB/s]
80%|███████▉ | 136M/170M [21:12<03:48, 151kB/s]
80%|███████▉ | 136M/170M [21:12<03:46, 153kB/s]
80%|███████▉ | 136M/170M [21:12<03:47, 152kB/s]
80%|███████▉ | 136M/170M [21:13<03:46, 153kB/s]
80%|███████▉ | 136M/170M [21:13<03:57, 145kB/s]
80%|███████▉ | 136M/170M [21:13<03:52, 148kB/s]
80%|███████▉ | 136M/170M [21:13<03:44, 153kB/s]
80%|███████▉ | 136M/170M [21:13<03:52, 148kB/s]
80%|███████▉ | 136M/170M [21:14<03:58, 144kB/s]
80%|███████▉ | 136M/170M [21:14<03:42, 154kB/s]
80%|███████▉ | 136M/170M [21:14<03:46, 151kB/s]
80%|███████▉ | 136M/170M [21:14<03:54, 146kB/s]
80%|███████▉ | 136M/170M [21:14<03:44, 152kB/s]
80%|███████▉ | 136M/170M [21:15<03:43, 153kB/s]
80%|███████▉ | 136M/170M [21:15<03:41, 154kB/s]
80%|███████▉ | 136M/170M [21:15<03:40, 155kB/s]
80%|███████▉ | 136M/170M [21:15<03:43, 153kB/s]
80%|████████ | 136M/170M [21:16<03:40, 155kB/s]
80%|████████ | 136M/170M [21:16<03:29, 162kB/s]
80%|████████ | 136M/170M [21:16<03:50, 148kB/s]
80%|████████ | 137M/170M [21:16<03:34, 158kB/s]
80%|████████ | 137M/170M [21:16<04:15, 133kB/s]
80%|████████ | 137M/170M [21:17<04:03, 140kB/s]
80%|████████ | 137M/170M [21:17<03:52, 146kB/s]
80%|████████ | 137M/170M [21:17<03:51, 146kB/s]
80%|████████ | 137M/170M [21:17<03:53, 145kB/s]
80%|████████ | 137M/170M [21:18<03:32, 159kB/s]
80%|████████ | 137M/170M [21:18<03:31, 160kB/s]
80%|████████ | 137M/170M [21:18<03:36, 156kB/s]
80%|████████ | 137M/170M [21:18<03:34, 157kB/s]
80%|████████ | 137M/170M [21:18<03:34, 157kB/s]
80%|████████ | 137M/170M [21:19<03:45, 149kB/s]
80%|████████ | 137M/170M [21:19<03:38, 154kB/s]
80%|████████ | 137M/170M [21:19<03:42, 151kB/s]
80%|████████ | 137M/170M [21:19<03:29, 160kB/s]
80%|████████ | 137M/170M [21:19<03:28, 161kB/s]
80%|████████ | 137M/170M [21:20<03:26, 162kB/s]
80%|████████ | 137M/170M [21:20<03:26, 162kB/s]
80%|████████ | 137M/170M [21:20<03:59, 139kB/s]
80%|████████ | 137M/170M [21:20<03:45, 148kB/s]
80%|████████ | 137M/170M [21:21<03:45, 148kB/s]
80%|████████ | 137M/170M [21:21<03:36, 154kB/s]
80%|████████ | 137M/170M [21:21<03:45, 148kB/s]
81%|████████ | 137M/170M [21:21<03:46, 147kB/s]
81%|████████ | 137M/170M [21:21<03:39, 151kB/s]
81%|████████ | 137M/170M [21:22<03:37, 152kB/s]
81%|████████ | 137M/170M [21:22<03:31, 157kB/s]
81%|████████ | 137M/170M [21:22<03:34, 154kB/s]
81%|████████ | 137M/170M [21:22<03:45, 146kB/s]
81%|████████ | 137M/170M [21:23<03:51, 142kB/s]
81%|████████ | 137M/170M [21:23<03:44, 147kB/s]
81%|████████ | 138M/170M [21:23<03:42, 148kB/s]
81%|████████ | 138M/170M [21:23<04:01, 137kB/s]
81%|████████ | 138M/170M [21:23<03:45, 146kB/s]
81%|████████ | 138M/170M [21:24<03:43, 147kB/s]
81%|████████ | 138M/170M [21:24<03:40, 149kB/s]
81%|████████ | 138M/170M [21:24<03:42, 148kB/s]
81%|████████ | 138M/170M [21:25<05:35, 97.7kB/s]
81%|████████ | 138M/170M [21:25<05:50, 93.5kB/s]
81%|████████ | 138M/170M [21:25<05:42, 95.5kB/s]
81%|████████ | 138M/170M [21:26<05:37, 96.8kB/s]
81%|████████ | 138M/170M [21:26<05:27, 99.8kB/s]
81%|████████ | 138M/170M [21:26<04:47, 113kB/s]
81%|████████ | 138M/170M [21:26<04:47, 113kB/s]
81%|████████ | 138M/170M [21:27<04:34, 119kB/s]
81%|████████ | 138M/170M [21:27<04:08, 131kB/s]
81%|████████ | 138M/170M [21:27<04:11, 129kB/s]
81%|████████ | 138M/170M [21:27<04:06, 132kB/s]
81%|████████ | 138M/170M [21:28<03:59, 135kB/s]
81%|████████ | 138M/170M [21:28<04:06, 131kB/s]
81%|████████ | 138M/170M [21:28<04:08, 130kB/s]
81%|████████ | 138M/170M [21:28<04:04, 132kB/s]
81%|████████ | 138M/170M [21:29<04:25, 122kB/s]
81%|████████ | 138M/170M [21:29<04:39, 115kB/s]
81%|████████ | 138M/170M [21:29<04:28, 120kB/s]
81%|████████ | 138M/170M [21:30<05:00, 107kB/s]
81%|████████ | 138M/170M [21:30<04:31, 118kB/s]
81%|████████ | 138M/170M [21:30<04:45, 112kB/s]
81%|████████ | 138M/170M [21:31<04:49, 111kB/s]
81%|████████ | 138M/170M [21:31<05:12, 103kB/s]
81%|████████ | 138M/170M [21:31<05:07, 104kB/s]
81%|████████ | 139M/170M [21:32<07:16, 73.3kB/s]
81%|████████▏ | 139M/170M [21:33<07:58, 66.8kB/s]
81%|████████▏ | 139M/170M [21:33<07:10, 74.1kB/s]
81%|████████▏ | 139M/170M [21:34<10:48, 49.2kB/s]
81%|████████▏ | 139M/170M [21:35<12:11, 43.6kB/s]
81%|████████▏ | 139M/170M [21:35<10:27, 50.7kB/s]
81%|████████▏ | 139M/170M [21:36<08:44, 60.6kB/s]
81%|████████▏ | 139M/170M [21:36<07:25, 71.2kB/s]
81%|████████▏ | 139M/170M [21:36<06:56, 76.1kB/s]
81%|████████▏ | 139M/170M [21:37<06:39, 79.2kB/s]
81%|████████▏ | 139M/170M [21:37<06:26, 81.9kB/s]
81%|████████▏ | 139M/170M [21:37<05:45, 91.4kB/s]
81%|████████▏ | 139M/170M [21:38<05:12, 101kB/s]
81%|████████▏ | 139M/170M [21:38<05:09, 102kB/s]
82%|████████▏ | 139M/170M [21:38<04:30, 117kB/s]
82%|████████▏ | 139M/170M [21:38<04:21, 121kB/s]
82%|████████▏ | 139M/170M [21:39<04:07, 127kB/s]
82%|████████▏ | 139M/170M [21:39<04:00, 131kB/s]
82%|████████▏ | 139M/170M [21:39<03:46, 139kB/s]
82%|████████▏ | 139M/170M [21:39<03:38, 143kB/s]
82%|████████▏ | 139M/170M [21:39<03:41, 142kB/s]
82%|████████▏ | 139M/170M [21:40<03:50, 135kB/s]
82%|████████▏ | 139M/170M [21:40<03:27, 151kB/s]
82%|████████▏ | 139M/170M [21:40<03:41, 141kB/s]
82%|████████▏ | 139M/170M [21:40<03:49, 136kB/s]
82%|████████▏ | 139M/170M [21:41<03:27, 150kB/s]
82%|████████▏ | 139M/170M [21:41<03:22, 154kB/s]
82%|████████▏ | 139M/170M [21:41<03:12, 161kB/s]
82%|████████▏ | 139M/170M [21:41<03:28, 149kB/s]
82%|████████▏ | 139M/170M [21:41<03:38, 142kB/s]
82%|████████▏ | 139M/170M [21:42<03:32, 146kB/s]
82%|████████▏ | 140M/170M [21:42<03:27, 149kB/s]
82%|████████▏ | 140M/170M [21:42<03:22, 153kB/s]
82%|████████▏ | 140M/170M [21:42<03:28, 148kB/s]
82%|████████▏ | 140M/170M [21:43<03:36, 143kB/s]
82%|████████▏ | 140M/170M [21:43<03:18, 155kB/s]
82%|████████▏ | 140M/170M [21:43<03:20, 154kB/s]
82%|████████▏ | 140M/170M [21:43<03:16, 156kB/s]
82%|████████▏ | 140M/170M [21:43<03:14, 158kB/s]
82%|████████▏ | 140M/170M [21:44<03:10, 161kB/s]
82%|████████▏ | 140M/170M [21:44<03:14, 157kB/s]
82%|████████▏ | 140M/170M [21:44<03:23, 150kB/s]
82%|████████▏ | 140M/170M [21:44<03:06, 165kB/s]
82%|████████▏ | 140M/170M [21:44<03:04, 166kB/s]
82%|████████▏ | 140M/170M [21:45<03:28, 146kB/s]
82%|████████▏ | 140M/170M [21:45<03:16, 155kB/s]
82%|████████▏ | 140M/170M [21:45<03:16, 155kB/s]
82%|████████▏ | 140M/170M [21:45<03:30, 145kB/s]
82%|████████▏ | 140M/170M [21:46<03:49, 133kB/s]
82%|████████▏ | 140M/170M [21:46<03:56, 128kB/s]
82%|████████▏ | 140M/170M [21:46<04:27, 113kB/s]
82%|████████▏ | 140M/170M [21:47<05:06, 98.8kB/s]
82%|████████▏ | 140M/170M [21:47<06:04, 83.1kB/s]
82%|████████▏ | 140M/170M [21:47<05:21, 94.0kB/s]
82%|████████▏ | 140M/170M [21:48<04:43, 107kB/s]
82%|████████▏ | 140M/170M [21:48<04:53, 103kB/s]
82%|████████▏ | 140M/170M [21:48<04:16, 118kB/s]
82%|████████▏ | 140M/170M [21:48<04:01, 125kB/s]
82%|████████▏ | 140M/170M [21:49<03:35, 140kB/s]
82%|████████▏ | 140M/170M [21:49<03:29, 143kB/s]
82%|████████▏ | 140M/170M [21:49<03:29, 143kB/s]
82%|████████▏ | 141M/170M [21:49<03:28, 144kB/s]
82%|████████▏ | 141M/170M [21:49<03:22, 148kB/s]
82%|████████▏ | 141M/170M [21:50<03:18, 151kB/s]
82%|████████▏ | 141M/170M [21:50<03:21, 148kB/s]
82%|████████▏ | 141M/170M [21:50<03:24, 146kB/s]
83%|████████▎ | 141M/170M [21:50<03:22, 148kB/s]
83%|████████▎ | 141M/170M [21:51<03:17, 151kB/s]
83%|████████▎ | 141M/170M [21:51<03:16, 151kB/s]
83%|████████▎ | 141M/170M [21:51<03:14, 153kB/s]
83%|████████▎ | 141M/170M [21:51<03:24, 145kB/s]
83%|████████▎ | 141M/170M [21:51<03:19, 149kB/s]
83%|████████▎ | 141M/170M [21:52<03:18, 150kB/s]
83%|████████▎ | 141M/170M [21:52<03:15, 152kB/s]
83%|████████▎ | 141M/170M [21:52<03:10, 155kB/s]
83%|████████▎ | 141M/170M [21:52<03:35, 137kB/s]
83%|████████▎ | 141M/170M [21:53<03:11, 154kB/s]
83%|████████▎ | 141M/170M [21:53<03:11, 154kB/s]
83%|████████▎ | 141M/170M [21:53<03:10, 155kB/s]
83%|████████▎ | 141M/170M [21:53<03:03, 160kB/s]
83%|████████▎ | 141M/170M [21:53<02:57, 165kB/s]
83%|████████▎ | 141M/170M [21:54<03:01, 162kB/s]
83%|████████▎ | 141M/170M [21:54<03:02, 161kB/s]
83%|████████▎ | 141M/170M [21:54<03:00, 162kB/s]
83%|████████▎ | 141M/170M [21:54<03:04, 158kB/s]
83%|████████▎ | 141M/170M [21:54<03:11, 153kB/s]
83%|████████▎ | 141M/170M [21:55<03:30, 138kB/s]
83%|████████▎ | 141M/170M [21:55<03:18, 147kB/s]
83%|████████▎ | 141M/170M [21:55<03:28, 140kB/s]
83%|████████▎ | 141M/170M [21:55<03:25, 142kB/s]
83%|████████▎ | 141M/170M [21:56<03:21, 144kB/s]
83%|████████▎ | 141M/170M [21:56<03:22, 144kB/s]
83%|████████▎ | 142M/170M [21:56<03:06, 156kB/s]
83%|████████▎ | 142M/170M [21:56<03:00, 161kB/s]
83%|████████▎ | 142M/170M [21:56<03:00, 160kB/s]
83%|████████▎ | 142M/170M [21:57<03:03, 158kB/s]
83%|████████▎ | 142M/170M [21:57<03:14, 148kB/s]
83%|████████▎ | 142M/170M [21:57<03:14, 148kB/s]
83%|████████▎ | 142M/170M [21:57<03:18, 145kB/s]
83%|████████▎ | 142M/170M [21:57<03:04, 156kB/s]
83%|████████▎ | 142M/170M [21:58<03:01, 158kB/s]
83%|████████▎ | 142M/170M [21:58<02:59, 159kB/s]
83%|████████▎ | 142M/170M [21:58<03:00, 159kB/s]
83%|████████▎ | 142M/170M [21:58<02:58, 160kB/s]
83%|████████▎ | 142M/170M [21:59<03:09, 150kB/s]
83%|████████▎ | 142M/170M [21:59<03:05, 154kB/s]
83%|████████▎ | 142M/170M [21:59<02:53, 165kB/s]
83%|████████▎ | 142M/170M [21:59<03:03, 155kB/s]
83%|████████▎ | 142M/170M [21:59<03:01, 157kB/s]
83%|████████▎ | 142M/170M [22:00<02:56, 161kB/s]
83%|████████▎ | 142M/170M [22:00<03:05, 153kB/s]
83%|████████▎ | 142M/170M [22:00<03:05, 153kB/s]
83%|████████▎ | 142M/170M [22:00<02:54, 162kB/s]
83%|████████▎ | 142M/170M [22:00<03:02, 155kB/s]
83%|████████▎ | 142M/170M [22:01<03:04, 153kB/s]
83%|████████▎ | 142M/170M [22:01<03:07, 151kB/s]
83%|████████▎ | 142M/170M [22:01<02:55, 161kB/s]
83%|████████▎ | 142M/170M [22:01<03:18, 142kB/s]
84%|████████▎ | 142M/170M [22:01<03:01, 155kB/s]
84%|████████▎ | 142M/170M [22:02<03:14, 144kB/s]
84%|████████▎ | 142M/170M [22:02<03:04, 152kB/s]
84%|████████▎ | 142M/170M [22:02<02:59, 156kB/s]
84%|████████▎ | 143M/170M [22:02<03:16, 143kB/s]
84%|████████▎ | 143M/170M [22:03<02:56, 158kB/s]
84%|████████▎ | 143M/170M [22:03<02:53, 161kB/s]
84%|████████▎ | 143M/170M [22:03<02:52, 162kB/s]
84%|████████▎ | 143M/170M [22:03<02:57, 157kB/s]
84%|████████▎ | 143M/170M [22:03<02:56, 158kB/s]
84%|████████▎ | 143M/170M [22:04<03:17, 140kB/s]
84%|████████▎ | 143M/170M [22:04<02:55, 158kB/s]
84%|████████▎ | 143M/170M [22:04<03:02, 152kB/s]
84%|████████▍ | 143M/170M [22:04<02:48, 165kB/s]
84%|████████▍ | 143M/170M [22:04<02:57, 156kB/s]
84%|████████▍ | 143M/170M [22:05<02:48, 164kB/s]
84%|████████▍ | 143M/170M [22:05<02:53, 160kB/s]
84%|████████▍ | 143M/170M [22:05<02:48, 163kB/s]
84%|████████▍ | 143M/170M [22:05<02:44, 167kB/s]
84%|████████▍ | 143M/170M [22:05<02:48, 164kB/s]
84%|████████▍ | 143M/170M [22:06<03:28, 132kB/s]
84%|████████▍ | 143M/170M [22:06<03:23, 135kB/s]
84%|████████▍ | 143M/170M [22:06<03:05, 148kB/s]
84%|████████▍ | 143M/170M [22:06<02:59, 153kB/s]
84%|████████▍ | 143M/170M [22:07<02:56, 155kB/s]
84%|████████▍ | 143M/170M [22:07<02:49, 161kB/s]
84%|████████▍ | 143M/170M [22:07<02:49, 161kB/s]
84%|████████▍ | 143M/170M [22:07<02:55, 155kB/s]
84%|████████▍ | 143M/170M [22:07<03:02, 149kB/s]
84%|████████▍ | 143M/170M [22:08<02:52, 157kB/s]
84%|████████▍ | 143M/170M [22:08<03:11, 142kB/s]
84%|████████▍ | 143M/170M [22:08<02:51, 158kB/s]
84%|████████▍ | 143M/170M [22:08<02:55, 154kB/s]
84%|████████▍ | 143M/170M [22:09<03:08, 143kB/s]
84%|████████▍ | 143M/170M [22:09<02:45, 163kB/s]
84%|████████▍ | 144M/170M [22:09<02:41, 167kB/s]
84%|████████▍ | 144M/170M [22:09<02:47, 161kB/s]
84%|████████▍ | 144M/170M [22:09<02:43, 165kB/s]
84%|████████▍ | 144M/170M [22:10<02:51, 156kB/s]
84%|████████▍ | 144M/170M [22:10<02:39, 169kB/s]
84%|████████▍ | 144M/170M [22:10<02:43, 164kB/s]
84%|████████▍ | 144M/170M [22:10<03:09, 141kB/s]
84%|████████▍ | 144M/170M [22:10<02:51, 156kB/s]
84%|████████▍ | 144M/170M [22:11<02:49, 158kB/s]
84%|████████▍ | 144M/170M [22:11<02:55, 152kB/s]
84%|████████▍ | 144M/170M [22:11<02:51, 156kB/s]
84%|████████▍ | 144M/170M [22:11<02:51, 155kB/s]
84%|████████▍ | 144M/170M [22:11<02:53, 153kB/s]
84%|████████▍ | 144M/170M [22:12<02:52, 154kB/s]
84%|████████▍ | 144M/170M [22:12<02:58, 149kB/s]
84%|████████▍ | 144M/170M [22:12<02:54, 152kB/s]
84%|████████▍ | 144M/170M [22:12<02:55, 151kB/s]
85%|████████▍ | 144M/170M [22:13<02:52, 154kB/s]
85%|████████▍ | 144M/170M [22:13<02:46, 159kB/s]
85%|████████▍ | 144M/170M [22:13<02:44, 161kB/s]
85%|████████▍ | 144M/170M [22:13<02:48, 156kB/s]
85%|████████▍ | 144M/170M [22:13<02:45, 159kB/s]
85%|████████▍ | 144M/170M [22:14<02:40, 164kB/s]
85%|████████▍ | 144M/170M [22:14<02:51, 153kB/s]
85%|████████▍ | 144M/170M [22:14<02:36, 167kB/s]
85%|████████▍ | 144M/170M [22:14<02:49, 154kB/s]
85%|████████▍ | 144M/170M [22:14<02:42, 161kB/s]
85%|████████▍ | 144M/170M [22:15<03:06, 140kB/s]
85%|████████▍ | 144M/170M [22:15<03:03, 142kB/s]
85%|████████▍ | 144M/170M [22:15<02:56, 147kB/s]
85%|████████▍ | 145M/170M [22:15<02:51, 151kB/s]
85%|████████▍ | 145M/170M [22:15<02:48, 154kB/s]
85%|████████▍ | 145M/170M [22:16<02:52, 151kB/s]
85%|████████▍ | 145M/170M [22:16<02:56, 147kB/s]
85%|████████▍ | 145M/170M [22:16<02:45, 156kB/s]
85%|████████▍ | 145M/170M [22:16<02:45, 156kB/s]
85%|████████▍ | 145M/170M [22:17<03:01, 142kB/s]
85%|████████▍ | 145M/170M [22:17<03:11, 135kB/s]
85%|████████▍ | 145M/170M [22:17<02:51, 150kB/s]
85%|████████▍ | 145M/170M [22:17<02:47, 153kB/s]
85%|████████▍ | 145M/170M [22:17<02:54, 147kB/s]
85%|████████▍ | 145M/170M [22:18<02:39, 161kB/s]
85%|████████▍ | 145M/170M [22:18<02:39, 160kB/s]
85%|████████▌ | 145M/170M [22:18<02:48, 152kB/s]
85%|████████▌ | 145M/170M [22:18<02:51, 149kB/s]
85%|████████▌ | 145M/170M [22:19<02:40, 158kB/s]
85%|████████▌ | 145M/170M [22:19<02:44, 155kB/s]
85%|████████▌ | 145M/170M [22:19<03:00, 141kB/s]
85%|████████▌ | 145M/170M [22:19<03:10, 134kB/s]
85%|████████▌ | 145M/170M [22:20<03:12, 132kB/s]
85%|████████▌ | 145M/170M [22:20<03:11, 132kB/s]
85%|████████▌ | 145M/170M [22:20<03:02, 138kB/s]
85%|████████▌ | 145M/170M [22:20<02:59, 141kB/s]
85%|████████▌ | 145M/170M [22:20<03:00, 140kB/s]
85%|████████▌ | 145M/170M [22:21<03:14, 130kB/s]
85%|████████▌ | 145M/170M [22:21<02:57, 142kB/s]
85%|████████▌ | 145M/170M [22:21<03:17, 127kB/s]
85%|████████▌ | 145M/170M [22:22<03:18, 126kB/s]
85%|████████▌ | 145M/170M [22:22<03:35, 116kB/s]
85%|████████▌ | 145M/170M [22:22<03:25, 122kB/s]
85%|████████▌ | 145M/170M [22:22<03:17, 127kB/s]
85%|████████▌ | 146M/170M [22:23<03:24, 122kB/s]
85%|████████▌ | 146M/170M [22:23<03:19, 125kB/s]
85%|████████▌ | 146M/170M [22:23<03:06, 133kB/s]
85%|████████▌ | 146M/170M [22:23<03:11, 130kB/s]
85%|████████▌ | 146M/170M [22:24<03:04, 134kB/s]
85%|████████▌ | 146M/170M [22:24<03:09, 131kB/s]
85%|████████▌ | 146M/170M [22:24<02:56, 141kB/s]
85%|████████▌ | 146M/170M [22:24<03:18, 125kB/s]
86%|████████▌ | 146M/170M [22:25<03:02, 135kB/s]
86%|████████▌ | 146M/170M [22:25<03:02, 135kB/s]
86%|████████▌ | 146M/170M [22:25<02:59, 138kB/s]
86%|████████▌ | 146M/170M [22:25<02:52, 142kB/s]
86%|████████▌ | 146M/170M [22:25<02:53, 141kB/s]
86%|████████▌ | 146M/170M [22:26<02:59, 137kB/s]
86%|████████▌ | 146M/170M [22:26<03:22, 121kB/s]
86%|████████▌ | 146M/170M [22:26<03:20, 122kB/s]
86%|████████▌ | 146M/170M [22:27<03:19, 122kB/s]
86%|████████▌ | 146M/170M [22:27<03:12, 127kB/s]
86%|████████▌ | 146M/170M [22:27<03:19, 122kB/s]
86%|████████▌ | 146M/170M [22:27<03:12, 127kB/s]
86%|████████▌ | 146M/170M [22:28<03:19, 122kB/s]
86%|████████▌ | 146M/170M [22:28<03:32, 114kB/s]
86%|████████▌ | 146M/170M [22:28<03:30, 115kB/s]
86%|████████▌ | 146M/170M [22:29<03:23, 119kB/s]
86%|████████▌ | 146M/170M [22:29<03:21, 120kB/s]
86%|████████▌ | 146M/170M [22:29<03:17, 122kB/s]
86%|████████▌ | 146M/170M [22:29<03:19, 121kB/s]
86%|████████▌ | 146M/170M [22:30<03:24, 118kB/s]
86%|████████▌ | 146M/170M [22:30<03:34, 112kB/s]
86%|████████▌ | 146M/170M [22:30<04:23, 91.3kB/s]
86%|████████▌ | 147M/170M [22:31<04:09, 96.0kB/s]
86%|████████▌ | 147M/170M [22:31<03:50, 104kB/s]
86%|████████▌ | 147M/170M [22:31<03:21, 119kB/s]
86%|████████▌ | 147M/170M [22:31<03:07, 128kB/s]
86%|████████▌ | 147M/170M [22:32<03:03, 130kB/s]
86%|████████▌ | 147M/170M [22:32<03:03, 130kB/s]
86%|████████▌ | 147M/170M [22:32<02:59, 133kB/s]
86%|████████▌ | 147M/170M [22:32<03:01, 131kB/s]
86%|████████▌ | 147M/170M [22:33<03:06, 127kB/s]
86%|████████▌ | 147M/170M [22:33<02:56, 134kB/s]
86%|████████▌ | 147M/170M [22:33<02:58, 133kB/s]
86%|████████▌ | 147M/170M [22:33<03:00, 131kB/s]
86%|████████▌ | 147M/170M [22:34<02:54, 135kB/s]
86%|████████▌ | 147M/170M [22:34<03:04, 128kB/s]
86%|████████▌ | 147M/170M [22:34<02:54, 135kB/s]
86%|████████▌ | 147M/170M [22:34<02:59, 131kB/s]
86%|████████▌ | 147M/170M [22:35<03:04, 127kB/s]
86%|████████▋ | 147M/170M [22:35<04:33, 85.6kB/s]
86%|████████▋ | 147M/170M [22:36<04:50, 80.7kB/s]
86%|████████▋ | 147M/170M [22:36<05:16, 73.8kB/s]
86%|████████▋ | 147M/170M [22:37<05:35, 69.5kB/s]
86%|████████▋ | 147M/170M [22:37<05:26, 71.4kB/s]
86%|████████▋ | 147M/170M [22:38<05:29, 70.6kB/s]
86%|████████▋ | 147M/170M [22:38<04:54, 78.9kB/s]
86%|████████▋ | 147M/170M [22:38<04:29, 86.2kB/s]
86%|████████▋ | 147M/170M [22:39<04:13, 91.6kB/s]
86%|████████▋ | 147M/170M [22:39<03:58, 97.0kB/s]
86%|████████▋ | 147M/170M [22:39<03:50, 100kB/s]
86%|████████▋ | 147M/170M [22:40<03:51, 99.6kB/s]
86%|████████▋ | 147M/170M [22:40<03:59, 96.2kB/s]
87%|████████▋ | 147M/170M [22:40<04:07, 92.8kB/s]
87%|████████▋ | 148M/170M [22:41<04:15, 89.8kB/s]
87%|████████▋ | 148M/170M [22:41<04:12, 90.8kB/s]
87%|████████▋ | 148M/170M [22:42<04:46, 80.0kB/s]
87%|████████▋ | 148M/170M [22:42<04:25, 86.2kB/s]
87%|████████▋ | 148M/170M [22:42<04:01, 94.7kB/s]
87%|████████▋ | 148M/170M [22:42<03:35, 106kB/s]
87%|████████▋ | 148M/170M [22:43<03:21, 113kB/s]
87%|████████▋ | 148M/170M [22:43<03:47, 99.8kB/s]
87%|████████▋ | 148M/170M [22:43<03:28, 109kB/s]
87%|████████▋ | 148M/170M [22:44<03:48, 99.4kB/s]
87%|████████▋ | 148M/170M [22:44<03:36, 105kB/s]
87%|████████▋ | 148M/170M [22:44<03:21, 112kB/s]
87%|████████▋ | 148M/170M [22:45<03:20, 113kB/s]
87%|████████▋ | 148M/170M [22:45<03:26, 109kB/s]
87%|████████▋ | 148M/170M [22:45<03:28, 108kB/s]
87%|████████▋ | 148M/170M [22:45<03:23, 111kB/s]
87%|████████▋ | 148M/170M [22:46<03:44, 100kB/s]
87%|████████▋ | 148M/170M [22:46<03:45, 99.5kB/s]
87%|████████▋ | 148M/170M [22:47<03:57, 94.1kB/s]
87%|████████▋ | 148M/170M [22:47<04:47, 77.8kB/s]
87%|████████▋ | 148M/170M [22:47<03:58, 93.5kB/s]
87%|████████▋ | 148M/170M [22:48<03:40, 101kB/s]
87%|████████▋ | 148M/170M [22:48<03:04, 121kB/s]
87%|████████▋ | 148M/170M [22:48<02:47, 132kB/s]
87%|████████▋ | 148M/170M [22:48<02:40, 139kB/s]
87%|████████▋ | 148M/170M [22:48<02:29, 148kB/s]
87%|████████▋ | 148M/170M [22:49<02:25, 152kB/s]
87%|████████▋ | 148M/170M [22:49<02:21, 156kB/s]
87%|████████▋ | 148M/170M [22:49<02:18, 160kB/s]
87%|████████▋ | 148M/170M [22:49<02:19, 158kB/s]
87%|████████▋ | 149M/170M [22:49<02:30, 146kB/s]
87%|████████▋ | 149M/170M [22:50<02:26, 150kB/s]
87%|████████▋ | 149M/170M [22:50<02:24, 151kB/s]
87%|████████▋ | 149M/170M [22:50<02:25, 150kB/s]
87%|████████▋ | 149M/170M [22:50<02:31, 145kB/s]
87%|████████▋ | 149M/170M [22:50<02:23, 152kB/s]
87%|████████▋ | 149M/170M [22:51<02:23, 151kB/s]
87%|████████▋ | 149M/170M [22:51<02:15, 161kB/s]
87%|████████▋ | 149M/170M [22:51<02:22, 153kB/s]
87%|████████▋ | 149M/170M [22:51<02:11, 165kB/s]
87%|████████▋ | 149M/170M [22:52<02:52, 125kB/s]
87%|████████▋ | 149M/170M [22:52<02:39, 135kB/s]
87%|████████▋ | 149M/170M [22:52<02:33, 141kB/s]
87%|████████▋ | 149M/170M [22:52<02:31, 143kB/s]
87%|████████▋ | 149M/170M [22:53<02:35, 138kB/s]
87%|████████▋ | 149M/170M [22:53<02:21, 152kB/s]
87%|████████▋ | 149M/170M [22:53<02:24, 149kB/s]
87%|████████▋ | 149M/170M [22:53<02:23, 150kB/s]
87%|████████▋ | 149M/170M [22:53<02:17, 156kB/s]
87%|████████▋ | 149M/170M [22:54<02:14, 159kB/s]
87%|████████▋ | 149M/170M [22:54<02:26, 146kB/s]
88%|████████▊ | 149M/170M [22:54<02:20, 152kB/s]
88%|████████▊ | 149M/170M [22:54<02:20, 152kB/s]
88%|████████▊ | 149M/170M [22:54<02:20, 151kB/s]
88%|████████▊ | 149M/170M [22:55<02:23, 148kB/s]
88%|████████▊ | 149M/170M [22:55<02:23, 147kB/s]
88%|████████▊ | 149M/170M [22:55<02:13, 158kB/s]
88%|████████▊ | 149M/170M [22:55<02:11, 160kB/s]
88%|████████▊ | 149M/170M [22:56<02:13, 158kB/s]
88%|████████▊ | 149M/170M [22:56<02:15, 155kB/s]
88%|████████▊ | 149M/170M [22:56<02:14, 156kB/s]
88%|████████▊ | 150M/170M [22:56<02:22, 147kB/s]
88%|████████▊ | 150M/170M [22:56<02:20, 149kB/s]
88%|████████▊ | 150M/170M [22:57<02:18, 151kB/s]
88%|████████▊ | 150M/170M [22:57<02:16, 153kB/s]
88%|████████▊ | 150M/170M [22:57<02:12, 158kB/s]
88%|████████▊ | 150M/170M [22:57<02:12, 157kB/s]
88%|████████▊ | 150M/170M [22:57<02:20, 148kB/s]
88%|████████▊ | 150M/170M [22:58<02:05, 165kB/s]
88%|████████▊ | 150M/170M [22:58<02:02, 169kB/s]
88%|████████▊ | 150M/170M [22:58<02:17, 151kB/s]
88%|████████▊ | 150M/170M [22:58<02:29, 139kB/s]
88%|████████▊ | 150M/170M [22:59<02:29, 138kB/s]
88%|████████▊ | 150M/170M [22:59<02:35, 132kB/s]
88%|████████▊ | 150M/170M [22:59<02:19, 147kB/s]
88%|████████▊ | 150M/170M [22:59<02:20, 146kB/s]
88%|████████▊ | 150M/170M [22:59<02:14, 153kB/s]
88%|████████▊ | 150M/170M [23:00<02:12, 155kB/s]
88%|████████▊ | 150M/170M [23:00<02:08, 159kB/s]
88%|████████▊ | 150M/170M [23:00<02:05, 162kB/s]
88%|████████▊ | 150M/170M [23:00<02:15, 151kB/s]
88%|████████▊ | 150M/170M [23:00<02:11, 154kB/s]
88%|████████▊ | 150M/170M [23:01<02:31, 134kB/s]
88%|████████▊ | 150M/170M [23:01<02:21, 143kB/s]
88%|████████▊ | 150M/170M [23:01<02:19, 145kB/s]
88%|████████▊ | 150M/170M [23:01<02:14, 150kB/s]
88%|████████▊ | 150M/170M [23:02<02:11, 153kB/s]
88%|████████▊ | 150M/170M [23:02<02:12, 151kB/s]
88%|████████▊ | 150M/170M [23:02<02:08, 157kB/s]
88%|████████▊ | 150M/170M [23:02<02:10, 154kB/s]
88%|████████▊ | 150M/170M [23:02<02:08, 156kB/s]
88%|████████▊ | 151M/170M [23:03<02:11, 152kB/s]
88%|████████▊ | 151M/170M [23:03<02:15, 147kB/s]
88%|████████▊ | 151M/170M [23:03<02:07, 157kB/s]
88%|████████▊ | 151M/170M [23:03<02:06, 157kB/s]
88%|████████▊ | 151M/170M [23:03<01:59, 166kB/s]
88%|████████▊ | 151M/170M [23:04<02:01, 163kB/s]
88%|████████▊ | 151M/170M [23:04<02:06, 157kB/s]
88%|████████▊ | 151M/170M [23:04<01:58, 167kB/s]
88%|████████▊ | 151M/170M [23:04<02:05, 158kB/s]
88%|████████▊ | 151M/170M [23:05<02:05, 157kB/s]
88%|████████▊ | 151M/170M [23:05<02:06, 155kB/s]
88%|████████▊ | 151M/170M [23:05<02:00, 162kB/s]
89%|████████▊ | 151M/170M [23:05<02:07, 154kB/s]
89%|████████▊ | 151M/170M [23:05<02:06, 155kB/s]
89%|████████▊ | 151M/170M [23:06<02:05, 156kB/s]
89%|████████▊ | 151M/170M [23:06<02:03, 158kB/s]
89%|████████▊ | 151M/170M [23:06<02:09, 151kB/s]
89%|████████▊ | 151M/170M [23:06<02:04, 156kB/s]
89%|████████▊ | 151M/170M [23:06<02:02, 159kB/s]
89%|████████▊ | 151M/170M [23:07<02:08, 151kB/s]
89%|████████▊ | 151M/170M [23:07<02:03, 156kB/s]
89%|████████▊ | 151M/170M [23:07<02:02, 157kB/s]
89%|████████▊ | 151M/170M [23:07<02:13, 145kB/s]
89%|████████▊ | 151M/170M [23:08<02:13, 144kB/s]
89%|████████▊ | 151M/170M [23:08<02:07, 151kB/s]
89%|████████▉ | 151M/170M [23:08<02:04, 154kB/s]
89%|████████▉ | 151M/170M [23:08<02:05, 153kB/s]
89%|████████▉ | 151M/170M [23:08<02:00, 159kB/s]
89%|████████▉ | 151M/170M [23:09<02:01, 157kB/s]
89%|████████▉ | 151M/170M [23:09<01:56, 163kB/s]
89%|████████▉ | 151M/170M [23:09<01:56, 163kB/s]
89%|████████▉ | 152M/170M [23:09<01:58, 161kB/s]
89%|████████▉ | 152M/170M [23:09<02:06, 150kB/s]
89%|████████▉ | 152M/170M [23:10<02:05, 151kB/s]
89%|████████▉ | 152M/170M [23:10<02:08, 147kB/s]
89%|████████▉ | 152M/170M [23:10<01:59, 158kB/s]
89%|████████▉ | 152M/170M [23:10<02:01, 154kB/s]
89%|████████▉ | 152M/170M [23:10<01:59, 158kB/s]
89%|████████▉ | 152M/170M [23:11<02:02, 153kB/s]
89%|████████▉ | 152M/170M [23:11<01:54, 164kB/s]
89%|████████▉ | 152M/170M [23:11<01:55, 162kB/s]
89%|████████▉ | 152M/170M [23:11<02:02, 152kB/s]
89%|████████▉ | 152M/170M [23:12<01:58, 158kB/s]
89%|████████▉ | 152M/170M [23:12<01:59, 156kB/s]
89%|████████▉ | 152M/170M [23:12<02:00, 154kB/s]
89%|████████▉ | 152M/170M [23:12<01:59, 155kB/s]
89%|████████▉ | 152M/170M [23:12<01:52, 164kB/s]
89%|████████▉ | 152M/170M [23:13<01:56, 158kB/s]
89%|████████▉ | 152M/170M [23:13<01:58, 156kB/s]
89%|████████▉ | 152M/170M [23:13<02:03, 149kB/s]
89%|████████▉ | 152M/170M [23:13<01:59, 154kB/s]
89%|████████▉ | 152M/170M [23:13<01:58, 155kB/s]
89%|████████▉ | 152M/170M [23:14<01:52, 162kB/s]
89%|████████▉ | 152M/170M [23:14<02:10, 140kB/s]
89%|████████▉ | 152M/170M [23:14<02:08, 142kB/s]
89%|████████▉ | 152M/170M [23:14<01:59, 152kB/s]
89%|████████▉ | 152M/170M [23:15<01:57, 154kB/s]
89%|████████▉ | 152M/170M [23:15<01:53, 160kB/s]
89%|████████▉ | 152M/170M [23:15<01:56, 156kB/s]
89%|████████▉ | 152M/170M [23:15<01:52, 161kB/s]
89%|████████▉ | 152M/170M [23:15<01:54, 158kB/s]
89%|████████▉ | 153M/170M [23:16<01:57, 153kB/s]
89%|████████▉ | 153M/170M [23:16<01:49, 164kB/s]
89%|████████▉ | 153M/170M [23:16<01:50, 162kB/s]
90%|████████▉ | 153M/170M [23:16<02:09, 139kB/s]
90%|████████▉ | 153M/170M [23:16<02:06, 141kB/s]
90%|████████▉ | 153M/170M [23:17<02:00, 148kB/s]
90%|████████▉ | 153M/170M [23:17<01:57, 152kB/s]
90%|████████▉ | 153M/170M [23:17<01:56, 153kB/s]
90%|████████▉ | 153M/170M [23:17<01:52, 157kB/s]
90%|████████▉ | 153M/170M [23:17<01:47, 164kB/s]
90%|████████▉ | 153M/170M [23:18<01:49, 161kB/s]
90%|████████▉ | 153M/170M [23:18<01:52, 157kB/s]
90%|████████▉ | 153M/170M [23:18<01:48, 162kB/s]
90%|████████▉ | 153M/170M [23:18<02:03, 142kB/s]
90%|████████▉ | 153M/170M [23:19<02:04, 140kB/s]
90%|████████▉ | 153M/170M [23:19<01:58, 147kB/s]
90%|████████▉ | 153M/170M [23:19<01:56, 149kB/s]
90%|████████▉ | 153M/170M [23:19<02:22, 122kB/s]
90%|████████▉ | 153M/170M [23:20<02:24, 120kB/s]
90%|████████▉ | 153M/170M [23:20<02:17, 126kB/s]
90%|████████▉ | 153M/170M [23:20<02:17, 126kB/s]
90%|████████▉ | 153M/170M [23:20<02:09, 133kB/s]
90%|████████▉ | 153M/170M [23:21<02:11, 131kB/s]
90%|████████▉ | 153M/170M [23:21<02:15, 127kB/s]
90%|████████▉ | 153M/170M [23:21<02:10, 132kB/s]
90%|████████▉ | 153M/170M [23:21<02:06, 136kB/s]
90%|████████▉ | 153M/170M [23:22<02:02, 140kB/s]
90%|████████▉ | 153M/170M [23:22<02:03, 139kB/s]
90%|████████▉ | 153M/170M [23:22<02:06, 135kB/s]
90%|█████████ | 153M/170M [23:22<01:57, 145kB/s]
90%|█████████ | 153M/170M [23:23<01:57, 145kB/s]
90%|█████████ | 154M/170M [23:23<02:00, 141kB/s]
90%|█████████ | 154M/170M [23:23<02:06, 133kB/s]
90%|█████████ | 154M/170M [23:23<01:58, 143kB/s]
90%|█████████ | 154M/170M [23:24<02:09, 130kB/s]
90%|█████████ | 154M/170M [23:24<02:00, 140kB/s]
90%|█████████ | 154M/170M [23:24<01:56, 144kB/s]
90%|█████████ | 154M/170M [23:24<01:57, 143kB/s]
90%|█████████ | 154M/170M [23:24<01:48, 155kB/s]
90%|█████████ | 154M/170M [23:25<01:47, 156kB/s]
90%|█████████ | 154M/170M [23:25<01:51, 150kB/s]
90%|█████████ | 154M/170M [23:25<01:50, 150kB/s]
90%|█████████ | 154M/170M [23:25<01:50, 151kB/s]
90%|█████████ | 154M/170M [23:25<01:56, 143kB/s]
90%|█████████ | 154M/170M [23:26<01:58, 139kB/s]
90%|█████████ | 154M/170M [23:26<01:56, 142kB/s]
90%|█████████ | 154M/170M [23:26<01:54, 144kB/s]
90%|█████████ | 154M/170M [23:26<01:51, 148kB/s]
90%|█████████ | 154M/170M [23:27<01:46, 154kB/s]
90%|█████████ | 154M/170M [23:27<01:48, 151kB/s]
90%|█████████ | 154M/170M [23:27<01:49, 150kB/s]
90%|█████████ | 154M/170M [23:27<01:50, 148kB/s]
90%|█████████ | 154M/170M [23:27<01:38, 166kB/s]
90%|█████████ | 154M/170M [23:28<01:40, 162kB/s]
90%|█████████ | 154M/170M [23:28<01:56, 139kB/s]
91%|█████████ | 154M/170M [23:28<01:58, 137kB/s]
91%|█████████ | 154M/170M [23:28<01:53, 142kB/s]
91%|█████████ | 154M/170M [23:29<01:52, 143kB/s]
91%|█████████ | 154M/170M [23:29<01:54, 140kB/s]
91%|█████████ | 154M/170M [23:29<01:43, 155kB/s]
91%|█████████ | 154M/170M [23:29<01:42, 156kB/s]
91%|█████████ | 155M/170M [23:29<01:40, 160kB/s]
91%|█████████ | 155M/170M [23:30<01:42, 155kB/s]
91%|█████████ | 155M/170M [23:30<01:42, 156kB/s]
91%|█████████ | 155M/170M [23:30<01:39, 159kB/s]
91%|█████████ | 155M/170M [23:30<01:49, 144kB/s]
91%|█████████ | 155M/170M [23:30<01:45, 150kB/s]
91%|█████████ | 155M/170M [23:31<01:49, 144kB/s]
91%|█████████ | 155M/170M [23:31<01:40, 157kB/s]
91%|█████████ | 155M/170M [23:31<01:44, 151kB/s]
91%|█████████ | 155M/170M [23:31<01:37, 162kB/s]
91%|█████████ | 155M/170M [23:32<01:43, 152kB/s]
91%|█████████ | 155M/170M [23:32<01:46, 147kB/s]
91%|█████████ | 155M/170M [23:32<01:45, 147kB/s]
91%|█████████ | 155M/170M [23:32<01:40, 155kB/s]
91%|█████████ | 155M/170M [23:32<01:43, 150kB/s]
91%|█████████ | 155M/170M [23:33<01:46, 145kB/s]
91%|█████████ | 155M/170M [23:33<02:41, 95.5kB/s]
91%|█████████ | 155M/170M [23:34<03:14, 79.6kB/s]
91%|█████████ | 155M/170M [23:34<03:02, 84.6kB/s]
91%|█████████ | 155M/170M [23:35<02:59, 85.5kB/s]
91%|█████████ | 155M/170M [23:36<04:17, 59.7kB/s]
91%|█████████ | 155M/170M [23:36<03:42, 68.7kB/s]
91%|█████████ | 155M/170M [23:36<03:36, 70.7kB/s]
91%|█████████ | 155M/170M [23:36<03:01, 84.1kB/s]
91%|█████████ | 155M/170M [23:37<02:57, 85.5kB/s]
91%|█████████ | 155M/170M [23:37<03:06, 81.6kB/s]
91%|█████████ | 155M/170M [23:38<02:46, 91.2kB/s]
91%|█████████ | 155M/170M [23:38<02:33, 98.3kB/s]
91%|█████████ | 155M/170M [23:38<02:18, 109kB/s]
91%|█████████ | 155M/170M [23:38<02:16, 110kB/s]
91%|█████████ | 155M/170M [23:39<02:17, 109kB/s]
91%|█████████ | 156M/170M [23:39<02:09, 116kB/s]
91%|█████████ | 156M/170M [23:39<02:03, 121kB/s]
91%|█████████▏| 156M/170M [23:39<01:55, 130kB/s]
91%|█████████▏| 156M/170M [23:40<01:49, 136kB/s]
91%|█████████▏| 156M/170M [23:40<01:59, 125kB/s]
91%|█████████▏| 156M/170M [23:40<01:53, 131kB/s]
91%|█████████▏| 156M/170M [23:40<01:54, 130kB/s]
91%|█████████▏| 156M/170M [23:41<01:44, 141kB/s]
91%|█████████▏| 156M/170M [23:41<01:47, 137kB/s]
91%|█████████▏| 156M/170M [23:41<01:42, 143kB/s]
91%|█████████▏| 156M/170M [23:41<01:46, 138kB/s]
91%|█████████▏| 156M/170M [23:42<01:54, 127kB/s]
91%|█████████▏| 156M/170M [23:42<01:52, 129kB/s]
91%|█████████▏| 156M/170M [23:42<01:47, 136kB/s]
91%|█████████▏| 156M/170M [23:42<01:48, 134kB/s]
92%|█████████▏| 156M/170M [23:43<01:48, 134kB/s]
92%|█████████▏| 156M/170M [23:43<01:46, 135kB/s]
92%|█████████▏| 156M/170M [23:43<01:42, 141kB/s]
92%|█████████▏| 156M/170M [23:43<01:51, 129kB/s]
92%|█████████▏| 156M/170M [23:44<01:54, 125kB/s]
92%|█████████▏| 156M/170M [23:44<01:47, 134kB/s]
92%|█████████▏| 156M/170M [23:44<01:54, 125kB/s]
92%|█████████▏| 156M/170M [23:44<01:55, 123kB/s]
92%|█████████▏| 156M/170M [23:45<01:59, 119kB/s]
92%|█████████▏| 156M/170M [23:45<01:57, 121kB/s]
92%|█████████▏| 156M/170M [23:45<02:05, 113kB/s]
92%|█████████▏| 156M/170M [23:46<02:23, 98.5kB/s]
92%|█████████▏| 156M/170M [23:46<02:24, 97.3kB/s]
92%|█████████▏| 156M/170M [23:46<02:10, 108kB/s]
92%|█████████▏| 156M/170M [23:46<02:06, 111kB/s]
92%|█████████▏| 156M/170M [23:47<02:11, 106kB/s]
92%|█████████▏| 157M/170M [23:47<02:07, 109kB/s]
92%|█████████▏| 157M/170M [23:47<02:07, 109kB/s]
92%|█████████▏| 157M/170M [23:48<02:05, 111kB/s]
92%|█████████▏| 157M/170M [23:48<02:05, 110kB/s]
92%|█████████▏| 157M/170M [23:48<02:01, 114kB/s]
92%|█████████▏| 157M/170M [23:49<02:07, 108kB/s]
92%|█████████▏| 157M/170M [23:49<02:03, 112kB/s]
92%|█████████▏| 157M/170M [23:49<02:11, 104kB/s]
92%|█████████▏| 157M/170M [23:49<01:56, 118kB/s]
92%|█████████▏| 157M/170M [23:50<01:52, 121kB/s]
92%|█████████▏| 157M/170M [23:50<01:48, 126kB/s]
92%|█████████▏| 157M/170M [23:50<01:50, 123kB/s]
92%|█████████▏| 157M/170M [23:50<01:50, 123kB/s]
92%|█████████▏| 157M/170M [23:51<02:02, 111kB/s]
92%|█████████▏| 157M/170M [23:51<02:02, 111kB/s]
92%|█████████▏| 157M/170M [23:51<02:08, 105kB/s]
92%|█████████▏| 157M/170M [23:52<01:59, 112kB/s]
92%|█████████▏| 157M/170M [23:52<02:01, 110kB/s]
92%|█████████▏| 157M/170M [23:52<01:59, 112kB/s]
92%|█████████▏| 157M/170M [23:53<01:55, 115kB/s]
92%|█████████▏| 157M/170M [23:53<01:53, 117kB/s]
92%|█████████▏| 157M/170M [23:53<01:52, 119kB/s]
92%|█████████▏| 157M/170M [23:54<02:05, 106kB/s]
92%|█████████▏| 157M/170M [23:54<02:04, 106kB/s]
92%|█████████▏| 157M/170M [23:54<02:08, 103kB/s]
92%|█████████▏| 157M/170M [23:55<02:20, 93.6kB/s]
92%|█████████▏| 157M/170M [23:55<02:05, 105kB/s]
92%|█████████▏| 157M/170M [23:55<01:57, 112kB/s]
92%|█████████▏| 157M/170M [23:55<01:52, 116kB/s]
92%|█████████▏| 157M/170M [23:56<01:47, 121kB/s]
92%|█████████▏| 158M/170M [23:56<01:43, 126kB/s]
92%|█████████▏| 158M/170M [23:56<01:42, 126kB/s]
92%|█████████▏| 158M/170M [23:56<01:42, 127kB/s]
92%|█████████▏| 158M/170M [23:57<01:42, 126kB/s]
92%|█████████▏| 158M/170M [23:57<01:43, 124kB/s]
92%|█████████▏| 158M/170M [23:57<01:46, 120kB/s]
93%|█████████▎| 158M/170M [23:57<01:48, 118kB/s]
93%|█████████▎| 158M/170M [23:58<01:54, 112kB/s]
93%|█████████▎| 158M/170M [23:58<01:47, 119kB/s]
93%|█████████▎| 158M/170M [23:58<01:46, 119kB/s]
93%|█████████▎| 158M/170M [23:59<01:45, 120kB/s]
93%|█████████▎| 158M/170M [23:59<01:45, 120kB/s]
93%|█████████▎| 158M/170M [23:59<01:47, 117kB/s]
93%|█████████▎| 158M/170M [23:59<01:48, 115kB/s]
93%|█████████▎| 158M/170M [24:00<01:47, 116kB/s]
93%|█████████▎| 158M/170M [24:00<01:41, 123kB/s]
93%|█████████▎| 158M/170M [24:00<01:53, 110kB/s]
93%|█████████▎| 158M/170M [24:01<01:48, 115kB/s]
93%|█████████▎| 158M/170M [24:01<01:42, 121kB/s]
93%|█████████▎| 158M/170M [24:01<01:40, 123kB/s]
93%|█████████▎| 158M/170M [24:01<01:35, 129kB/s]
93%|█████████▎| 158M/170M [24:01<01:33, 132kB/s]
93%|█████████▎| 158M/170M [24:02<01:37, 125kB/s]
93%|█████████▎| 158M/170M [24:02<01:36, 126kB/s]
93%|█████████▎| 158M/170M [24:02<01:39, 122kB/s]
93%|█████████▎| 158M/170M [24:03<01:38, 124kB/s]
93%|█████████▎| 158M/170M [24:03<01:37, 125kB/s]
93%|█████████▎| 158M/170M [24:03<01:47, 113kB/s]
93%|█████████▎| 158M/170M [24:03<01:43, 116kB/s]
93%|█████████▎| 158M/170M [24:04<01:42, 117kB/s]
93%|█████████▎| 158M/170M [24:04<01:49, 109kB/s]
93%|█████████▎| 159M/170M [24:04<01:50, 108kB/s]
93%|█████████▎| 159M/170M [24:05<01:51, 107kB/s]
93%|█████████▎| 159M/170M [24:05<01:46, 112kB/s]
93%|█████████▎| 159M/170M [24:05<01:46, 112kB/s]
93%|█████████▎| 159M/170M [24:05<01:33, 127kB/s]
93%|█████████▎| 159M/170M [24:06<01:29, 132kB/s]
93%|█████████▎| 159M/170M [24:06<01:45, 112kB/s]
93%|█████████▎| 159M/170M [24:06<01:45, 111kB/s]
93%|█████████▎| 159M/170M [24:07<01:38, 119kB/s]
93%|█████████▎| 159M/170M [24:07<01:30, 129kB/s]
93%|█████████▎| 159M/170M [24:07<01:30, 128kB/s]
93%|█████████▎| 159M/170M [24:07<01:29, 130kB/s]
93%|█████████▎| 159M/170M [24:08<01:32, 125kB/s]
93%|█████████▎| 159M/170M [24:08<01:31, 126kB/s]
93%|█████████▎| 159M/170M [24:08<01:35, 121kB/s]
93%|█████████▎| 159M/170M [24:08<01:37, 118kB/s]
93%|█████████▎| 159M/170M [24:09<01:39, 116kB/s]
93%|█████████▎| 159M/170M [24:09<01:42, 111kB/s]
93%|█████████▎| 159M/170M [24:09<01:40, 113kB/s]
93%|█████████▎| 159M/170M [24:10<01:32, 123kB/s]
93%|█████████▎| 159M/170M [24:10<01:27, 129kB/s]
93%|█████████▎| 159M/170M [24:10<01:50, 102kB/s]
93%|█████████▎| 159M/170M [24:11<01:47, 105kB/s]
93%|█████████▎| 159M/170M [24:11<01:49, 102kB/s]
93%|█████████▎| 159M/170M [24:11<01:50, 102kB/s]
93%|█████████▎| 159M/170M [24:11<01:47, 103kB/s]
93%|█████████▎| 159M/170M [24:12<01:46, 105kB/s]
94%|█████████▎| 159M/170M [24:12<01:49, 101kB/s]
94%|█████████▎| 159M/170M [24:12<01:42, 108kB/s]
94%|█████████▎| 159M/170M [24:13<01:42, 107kB/s]
94%|█████████▎| 160M/170M [24:13<01:34, 116kB/s]
94%|█████████▎| 160M/170M [24:13<01:32, 118kB/s]
94%|█████████▎| 160M/170M [24:13<01:30, 121kB/s]
94%|█████████▎| 160M/170M [24:14<01:26, 126kB/s]
94%|█████████▎| 160M/170M [24:14<01:33, 116kB/s]
94%|█████████▎| 160M/170M [24:14<01:37, 111kB/s]
94%|█████████▎| 160M/170M [24:15<01:53, 94.9kB/s]
94%|█████████▎| 160M/170M [24:15<02:00, 89.4kB/s]
94%|█████████▎| 160M/170M [24:15<01:46, 101kB/s]
94%|█████████▎| 160M/170M [24:16<01:43, 103kB/s]
94%|█████████▍| 160M/170M [24:16<01:33, 115kB/s]
94%|█████████▍| 160M/170M [24:16<01:29, 118kB/s]
94%|█████████▍| 160M/170M [24:16<01:28, 120kB/s]
94%|█████████▍| 160M/170M [24:17<01:30, 117kB/s]
94%|█████████▍| 160M/170M [24:17<01:30, 117kB/s]
94%|█████████▍| 160M/170M [24:17<01:26, 121kB/s]
94%|█████████▍| 160M/170M [24:18<01:33, 112kB/s]
94%|█████████▍| 160M/170M [24:18<01:36, 108kB/s]
94%|█████████▍| 160M/170M [24:18<01:42, 101kB/s]
94%|█████████▍| 160M/170M [24:19<01:33, 111kB/s]
94%|█████████▍| 160M/170M [24:19<01:28, 117kB/s]
94%|█████████▍| 160M/170M [24:19<01:24, 121kB/s]
94%|█████████▍| 160M/170M [24:19<01:22, 124kB/s]
94%|█████████▍| 160M/170M [24:20<01:59, 85.6kB/s]
94%|█████████▍| 160M/170M [24:20<01:47, 94.6kB/s]
94%|█████████▍| 160M/170M [24:20<01:38, 104kB/s]
94%|█████████▍| 160M/170M [24:21<01:37, 104kB/s]
94%|█████████▍| 160M/170M [24:21<01:35, 106kB/s]
94%|█████████▍| 160M/170M [24:22<01:50, 91.1kB/s]
94%|█████████▍| 160M/170M [24:22<01:51, 90.0kB/s]
94%|█████████▍| 160M/170M [24:22<01:46, 93.8kB/s]
94%|█████████▍| 161M/170M [24:23<01:37, 102kB/s]
94%|█████████▍| 161M/170M [24:23<01:34, 105kB/s]
94%|█████████▍| 161M/170M [24:23<01:41, 97.8kB/s]
94%|█████████▍| 161M/170M [24:24<01:38, 100kB/s]
94%|█████████▍| 161M/170M [24:24<01:33, 105kB/s]
94%|█████████▍| 161M/170M [24:24<01:37, 100kB/s]
94%|█████████▍| 161M/170M [24:25<02:04, 78.7kB/s]
94%|█████████▍| 161M/170M [24:25<02:09, 74.9kB/s]
94%|█████████▍| 161M/170M [24:26<02:08, 75.3kB/s]
94%|█████████▍| 161M/170M [24:26<02:00, 80.3kB/s]
94%|█████████▍| 161M/170M [24:26<01:46, 90.5kB/s]
94%|█████████▍| 161M/170M [24:27<01:41, 94.4kB/s]
94%|█████████▍| 161M/170M [24:27<01:29, 107kB/s]
94%|█████████▍| 161M/170M [24:27<01:32, 104kB/s]
94%|█████████▍| 161M/170M [24:27<01:26, 110kB/s]
94%|█████████▍| 161M/170M [24:28<01:30, 105kB/s]
94%|█████████▍| 161M/170M [24:28<01:26, 109kB/s]
94%|█████████▍| 161M/170M [24:28<01:14, 126kB/s]
94%|█████████▍| 161M/170M [24:28<01:14, 126kB/s]
95%|█████████▍| 161M/170M [24:29<01:09, 134kB/s]
95%|█████████▍| 161M/170M [24:29<01:05, 142kB/s]
95%|█████████▍| 161M/170M [24:29<01:03, 146kB/s]
95%|█████████▍| 161M/170M [24:29<01:02, 148kB/s]
95%|█████████▍| 161M/170M [24:30<01:03, 146kB/s]
95%|█████████▍| 161M/170M [24:30<00:58, 157kB/s]
95%|█████████▍| 161M/170M [24:30<00:54, 167kB/s]
95%|█████████▍| 161M/170M [24:30<00:55, 164kB/s]
95%|█████████▍| 161M/170M [24:30<00:56, 162kB/s]
95%|█████████▍| 161M/170M [24:31<01:01, 148kB/s]
95%|█████████▍| 161M/170M [24:31<01:01, 147kB/s]
95%|█████████▍| 162M/170M [24:31<00:59, 150kB/s]
95%|█████████▍| 162M/170M [24:32<01:32, 96.9kB/s]
95%|█████████▍| 162M/170M [24:32<02:05, 70.9kB/s]
95%|█████████▍| 162M/170M [24:33<02:06, 70.1kB/s]
95%|█████████▍| 162M/170M [24:33<01:56, 75.8kB/s]
95%|█████████▍| 162M/170M [24:33<01:45, 83.9kB/s]
95%|█████████▍| 162M/170M [24:34<01:40, 87.7kB/s]
95%|█████████▍| 162M/170M [24:34<01:36, 91.1kB/s]
95%|█████████▍| 162M/170M [24:35<01:50, 79.2kB/s]
95%|█████████▍| 162M/170M [24:35<01:51, 77.9kB/s]
95%|█████████▍| 162M/170M [24:35<01:37, 89.1kB/s]
95%|█████████▍| 162M/170M [24:36<01:28, 97.1kB/s]
95%|█████████▍| 162M/170M [24:36<01:24, 101kB/s]
95%|█████████▍| 162M/170M [24:36<01:20, 107kB/s]
95%|█████████▍| 162M/170M [24:36<01:13, 116kB/s]
95%|█████████▌| 162M/170M [24:37<01:08, 123kB/s]
95%|█████████▌| 162M/170M [24:37<01:05, 130kB/s]
95%|█████████▌| 162M/170M [24:37<01:03, 132kB/s]
95%|█████████▌| 162M/170M [24:37<00:59, 140kB/s]
95%|█████████▌| 162M/170M [24:38<01:00, 139kB/s]
95%|█████████▌| 162M/170M [24:38<00:56, 147kB/s]
95%|█████████▌| 162M/170M [24:38<00:54, 152kB/s]
95%|█████████▌| 162M/170M [24:38<00:56, 147kB/s]
95%|█████████▌| 162M/170M [24:38<00:52, 158kB/s]
95%|█████████▌| 162M/170M [24:39<00:50, 161kB/s]
95%|█████████▌| 162M/170M [24:39<00:51, 160kB/s]
95%|█████████▌| 162M/170M [24:39<00:50, 160kB/s]
95%|█████████▌| 162M/170M [24:39<00:53, 153kB/s]
95%|█████████▌| 162M/170M [24:39<00:49, 163kB/s]
95%|█████████▌| 162M/170M [24:40<00:50, 158kB/s]
95%|█████████▌| 162M/170M [24:40<00:52, 153kB/s]
95%|█████████▌| 163M/170M [24:40<00:57, 139kB/s]
95%|█████████▌| 163M/170M [24:40<00:54, 145kB/s]
95%|█████████▌| 163M/170M [24:40<00:53, 148kB/s]
95%|█████████▌| 163M/170M [24:41<00:54, 145kB/s]
95%|█████████▌| 163M/170M [24:41<00:53, 146kB/s]
95%|█████████▌| 163M/170M [24:41<00:49, 158kB/s]
95%|█████████▌| 163M/170M [24:41<00:49, 156kB/s]
95%|█████████▌| 163M/170M [24:42<00:48, 158kB/s]
95%|█████████▌| 163M/170M [24:42<00:53, 144kB/s]
95%|█████████▌| 163M/170M [24:42<00:51, 148kB/s]
96%|█████████▌| 163M/170M [24:42<00:50, 151kB/s]
96%|█████████▌| 163M/170M [24:42<00:49, 155kB/s]
96%|█████████▌| 163M/170M [24:43<00:49, 152kB/s]
96%|█████████▌| 163M/170M [24:43<00:48, 156kB/s]
96%|█████████▌| 163M/170M [24:43<00:47, 158kB/s]
96%|█████████▌| 163M/170M [24:43<00:46, 161kB/s]
96%|█████████▌| 163M/170M [24:43<00:45, 163kB/s]
96%|█████████▌| 163M/170M [24:44<00:44, 165kB/s]
96%|█████████▌| 163M/170M [24:44<00:46, 160kB/s]
96%|█████████▌| 163M/170M [24:44<00:44, 166kB/s]
96%|█████████▌| 163M/170M [24:44<00:49, 147kB/s]
96%|█████████▌| 163M/170M [24:45<00:50, 145kB/s]
96%|█████████▌| 163M/170M [24:45<00:46, 155kB/s]
96%|█████████▌| 163M/170M [24:45<00:46, 154kB/s]
96%|█████████▌| 163M/170M [24:45<00:46, 155kB/s]
96%|█████████▌| 163M/170M [24:45<00:45, 157kB/s]
96%|█████████▌| 163M/170M [24:46<00:46, 155kB/s]
96%|█████████▌| 163M/170M [24:46<00:44, 160kB/s]
96%|█████████▌| 163M/170M [24:46<00:44, 159kB/s]
96%|█████████▌| 163M/170M [24:46<00:46, 152kB/s]
96%|█████████▌| 164M/170M [24:46<00:47, 146kB/s]
96%|█████████▌| 164M/170M [24:47<00:46, 149kB/s]
96%|█████████▌| 164M/170M [24:47<00:43, 161kB/s]
96%|█████████▌| 164M/170M [24:47<00:43, 158kB/s]
96%|█████████▌| 164M/170M [24:47<00:43, 157kB/s]
96%|█████████▌| 164M/170M [24:47<00:45, 150kB/s]
96%|█████████▌| 164M/170M [24:48<00:40, 166kB/s]
96%|█████████▌| 164M/170M [24:48<00:42, 160kB/s]
96%|█████████▌| 164M/170M [24:48<00:41, 163kB/s]
96%|█████████▌| 164M/170M [24:48<00:41, 163kB/s]
96%|█████████▌| 164M/170M [24:49<00:45, 146kB/s]
96%|█████████▌| 164M/170M [24:49<00:46, 143kB/s]
96%|█████████▌| 164M/170M [24:49<00:41, 158kB/s]
96%|█████████▌| 164M/170M [24:49<00:39, 164kB/s]
96%|█████████▌| 164M/170M [24:49<00:43, 150kB/s]
96%|█████████▌| 164M/170M [24:50<00:44, 146kB/s]
96%|█████████▌| 164M/170M [24:50<00:44, 144kB/s]
96%|█████████▌| 164M/170M [24:50<00:40, 158kB/s]
96%|█████████▌| 164M/170M [24:50<00:41, 153kB/s]
96%|█████████▋| 164M/170M [24:51<01:11, 89.5kB/s]
96%|█████████▋| 164M/170M [24:51<01:10, 89.7kB/s]
96%|█████████▋| 164M/170M [24:52<01:16, 82.2kB/s]
96%|█████████▋| 164M/170M [24:52<01:09, 90.5kB/s]
96%|█████████▋| 164M/170M [24:52<01:03, 98.0kB/s]
96%|█████████▋| 164M/170M [24:53<01:03, 98.1kB/s]
96%|█████████▋| 164M/170M [24:53<00:51, 120kB/s]
96%|█████████▋| 164M/170M [24:53<00:51, 120kB/s]
96%|█████████▋| 164M/170M [24:53<00:51, 119kB/s]
96%|█████████▋| 164M/170M [24:54<00:52, 116kB/s]
96%|█████████▋| 164M/170M [24:54<00:47, 126kB/s]
96%|█████████▋| 164M/170M [24:54<00:48, 124kB/s]
96%|█████████▋| 165M/170M [24:54<00:49, 120kB/s]
97%|█████████▋| 165M/170M [24:55<00:47, 125kB/s]
97%|█████████▋| 165M/170M [24:55<00:48, 122kB/s]
97%|█████████▋| 165M/170M [24:55<00:50, 116kB/s]
97%|█████████▋| 165M/170M [24:56<00:47, 122kB/s]
97%|█████████▋| 165M/170M [24:56<00:47, 123kB/s]
97%|█████████▋| 165M/170M [24:56<00:52, 110kB/s]
97%|█████████▋| 165M/170M [24:56<00:49, 116kB/s]
97%|█████████▋| 165M/170M [24:57<00:49, 114kB/s]
97%|█████████▋| 165M/170M [24:57<00:47, 119kB/s]
97%|█████████▋| 165M/170M [24:57<00:51, 109kB/s]
97%|█████████▋| 165M/170M [24:58<00:52, 107kB/s]
97%|█████████▋| 165M/170M [24:58<00:51, 109kB/s]
97%|█████████▋| 165M/170M [24:58<00:53, 104kB/s]
97%|█████████▋| 165M/170M [24:58<00:48, 114kB/s]
97%|█████████▋| 165M/170M [24:59<00:44, 122kB/s]
97%|█████████▋| 165M/170M [24:59<00:43, 127kB/s]
97%|█████████▋| 165M/170M [24:59<00:40, 132kB/s]
97%|█████████▋| 165M/170M [25:00<00:47, 113kB/s]
97%|█████████▋| 165M/170M [25:00<00:44, 121kB/s]
97%|█████████▋| 165M/170M [25:00<00:45, 116kB/s]
97%|█████████▋| 165M/170M [25:00<00:48, 109kB/s]
97%|█████████▋| 165M/170M [25:01<00:45, 114kB/s]
97%|█████████▋| 165M/170M [25:01<00:44, 118kB/s]
97%|█████████▋| 165M/170M [25:01<00:42, 122kB/s]
97%|█████████▋| 165M/170M [25:02<01:03, 81.6kB/s]
97%|█████████▋| 165M/170M [25:02<01:04, 79.5kB/s]
97%|█████████▋| 165M/170M [25:03<01:03, 80.3kB/s]
97%|█████████▋| 165M/170M [25:03<00:57, 87.6kB/s]
97%|█████████▋| 165M/170M [25:03<00:48, 104kB/s]
97%|█████████▋| 166M/170M [25:03<00:43, 114kB/s]
97%|█████████▋| 166M/170M [25:04<00:42, 117kB/s]
97%|█████████▋| 166M/170M [25:04<00:38, 128kB/s]
97%|█████████▋| 166M/170M [25:04<00:36, 135kB/s]
97%|█████████▋| 166M/170M [25:04<00:34, 142kB/s]
97%|█████████▋| 166M/170M [25:05<00:33, 143kB/s]
97%|█████████▋| 166M/170M [25:05<00:33, 141kB/s]
97%|█████████▋| 166M/170M [25:05<00:31, 150kB/s]
97%|█████████▋| 166M/170M [25:05<00:32, 147kB/s]
97%|█████████▋| 166M/170M [25:05<00:30, 153kB/s]
97%|█████████▋| 166M/170M [25:06<00:29, 159kB/s]
97%|█████████▋| 166M/170M [25:06<00:28, 162kB/s]
97%|█████████▋| 166M/170M [25:06<00:32, 142kB/s]
97%|█████████▋| 166M/170M [25:06<00:30, 148kB/s]
97%|█████████▋| 166M/170M [25:06<00:29, 154kB/s]
97%|█████████▋| 166M/170M [25:07<00:28, 157kB/s]
97%|█████████▋| 166M/170M [25:07<00:28, 154kB/s]
97%|█████████▋| 166M/170M [25:07<00:26, 164kB/s]
97%|█████████▋| 166M/170M [25:07<00:27, 160kB/s]
97%|█████████▋| 166M/170M [25:07<00:26, 162kB/s]
97%|█████████▋| 166M/170M [25:08<00:26, 163kB/s]
97%|█████████▋| 166M/170M [25:08<00:28, 149kB/s]
97%|█████████▋| 166M/170M [25:08<00:29, 143kB/s]
98%|█████████▊| 166M/170M [25:08<00:28, 147kB/s]
98%|█████████▊| 166M/170M [25:09<00:28, 148kB/s]
98%|█████████▊| 166M/170M [25:09<00:26, 155kB/s]
98%|█████████▊| 166M/170M [25:09<00:27, 151kB/s]
98%|█████████▊| 166M/170M [25:09<00:26, 154kB/s]
98%|█████████▊| 166M/170M [25:09<00:27, 149kB/s]
98%|█████████▊| 166M/170M [25:10<00:25, 160kB/s]
98%|█████████▊| 166M/170M [25:10<00:25, 157kB/s]
98%|█████████▊| 167M/170M [25:10<00:24, 162kB/s]
98%|█████████▊| 167M/170M [25:10<00:24, 159kB/s]
98%|█████████▊| 167M/170M [25:10<00:25, 152kB/s]
98%|█████████▊| 167M/170M [25:11<00:25, 153kB/s]
98%|█████████▊| 167M/170M [25:11<00:24, 155kB/s]
98%|█████████▊| 167M/170M [25:11<00:24, 158kB/s]
98%|█████████▊| 167M/170M [25:11<00:24, 157kB/s]
98%|█████████▊| 167M/170M [25:12<00:25, 147kB/s]
98%|█████████▊| 167M/170M [25:12<00:26, 138kB/s]
98%|█████████▊| 167M/170M [25:12<00:25, 146kB/s]
98%|█████████▊| 167M/170M [25:12<00:25, 142kB/s]
98%|█████████▊| 167M/170M [25:12<00:22, 161kB/s]
98%|█████████▊| 167M/170M [25:13<00:24, 148kB/s]
98%|█████████▊| 167M/170M [25:13<00:23, 153kB/s]
98%|█████████▊| 167M/170M [25:13<00:22, 158kB/s]
98%|█████████▊| 167M/170M [25:13<00:22, 155kB/s]
98%|█████████▊| 167M/170M [25:13<00:21, 158kB/s]
98%|█████████▊| 167M/170M [25:14<00:21, 158kB/s]
98%|█████████▊| 167M/170M [25:14<00:21, 158kB/s]
98%|█████████▊| 167M/170M [25:14<00:20, 164kB/s]
98%|█████████▊| 167M/170M [25:14<00:20, 162kB/s]
98%|█████████▊| 167M/170M [25:14<00:19, 166kB/s]
98%|█████████▊| 167M/170M [25:15<00:19, 165kB/s]
98%|█████████▊| 167M/170M [25:15<00:21, 153kB/s]
98%|█████████▊| 167M/170M [25:15<00:20, 156kB/s]
98%|█████████▊| 167M/170M [25:15<00:20, 156kB/s]
98%|█████████▊| 167M/170M [25:16<00:20, 151kB/s]
98%|█████████▊| 167M/170M [25:16<00:21, 145kB/s]
98%|█████████▊| 167M/170M [25:16<00:21, 144kB/s]
98%|█████████▊| 167M/170M [25:16<00:19, 156kB/s]
98%|█████████▊| 168M/170M [25:16<00:19, 155kB/s]
98%|█████████▊| 168M/170M [25:17<00:19, 155kB/s]
98%|█████████▊| 168M/170M [25:17<00:18, 155kB/s]
98%|█████████▊| 168M/170M [25:17<00:19, 148kB/s]
98%|█████████▊| 168M/170M [25:17<00:18, 153kB/s]
98%|█████████▊| 168M/170M [25:17<00:17, 159kB/s]
98%|█████████▊| 168M/170M [25:18<00:18, 147kB/s]
98%|█████████▊| 168M/170M [25:18<00:18, 150kB/s]
98%|█████████▊| 168M/170M [25:18<00:17, 157kB/s]
98%|█████████▊| 168M/170M [25:18<00:17, 150kB/s]
98%|█████████▊| 168M/170M [25:19<00:16, 165kB/s]
98%|█████████▊| 168M/170M [25:19<00:16, 164kB/s]
98%|█████████▊| 168M/170M [25:19<00:15, 163kB/s]
98%|█████████▊| 168M/170M [25:19<00:18, 141kB/s]
99%|█████████▊| 168M/170M [25:19<00:17, 145kB/s]
99%|█████████▊| 168M/170M [25:20<00:17, 141kB/s]
99%|█████████▊| 168M/170M [25:20<00:15, 156kB/s]
99%|█████████▊| 168M/170M [25:20<00:15, 155kB/s]
99%|█████████▊| 168M/170M [25:20<00:15, 159kB/s]
99%|█████████▊| 168M/170M [25:20<00:15, 154kB/s]
99%|█████████▊| 168M/170M [25:21<00:14, 162kB/s]
99%|█████████▊| 168M/170M [25:21<00:14, 164kB/s]
99%|█████████▊| 168M/170M [25:21<00:13, 171kB/s]
99%|█████████▊| 168M/170M [25:21<00:13, 162kB/s]
99%|█████████▊| 168M/170M [25:22<00:15, 138kB/s]
99%|█████████▊| 168M/170M [25:22<00:15, 139kB/s]
99%|█████████▊| 168M/170M [25:22<00:13, 155kB/s]
99%|█████████▉| 168M/170M [25:22<00:13, 158kB/s]
99%|█████████▉| 168M/170M [25:22<00:13, 158kB/s]
99%|█████████▉| 168M/170M [25:23<00:12, 160kB/s]
99%|█████████▉| 168M/170M [25:23<00:13, 152kB/s]
99%|█████████▉| 169M/170M [25:23<00:14, 134kB/s]
99%|█████████▉| 169M/170M [25:23<00:14, 134kB/s]
99%|█████████▉| 169M/170M [25:24<00:14, 130kB/s]
99%|█████████▉| 169M/170M [25:24<00:15, 124kB/s]
99%|█████████▉| 169M/170M [25:24<00:15, 117kB/s]
99%|█████████▉| 169M/170M [25:24<00:14, 125kB/s]
99%|█████████▉| 169M/170M [25:25<00:13, 134kB/s]
99%|█████████▉| 169M/170M [25:25<00:12, 138kB/s]
99%|█████████▉| 169M/170M [25:25<00:12, 141kB/s]
99%|█████████▉| 169M/170M [25:25<00:11, 142kB/s]
99%|█████████▉| 169M/170M [25:26<00:10, 152kB/s]
99%|█████████▉| 169M/170M [25:26<00:11, 137kB/s]
99%|█████████▉| 169M/170M [25:26<00:10, 152kB/s]
99%|█████████▉| 169M/170M [25:26<00:11, 139kB/s]
99%|█████████▉| 169M/170M [25:27<00:11, 128kB/s]
99%|█████████▉| 169M/170M [25:27<00:11, 132kB/s]
99%|█████████▉| 169M/170M [25:27<00:10, 139kB/s]
99%|█████████▉| 169M/170M [25:27<00:09, 145kB/s]
99%|█████████▉| 169M/170M [25:27<00:10, 136kB/s]
99%|█████████▉| 169M/170M [25:28<00:08, 154kB/s]
99%|█████████▉| 169M/170M [25:28<00:09, 146kB/s]
99%|█████████▉| 169M/170M [25:28<00:08, 145kB/s]
99%|█████████▉| 169M/170M [25:28<00:08, 140kB/s]
99%|█████████▉| 169M/170M [25:29<00:08, 143kB/s]
99%|█████████▉| 169M/170M [25:29<00:08, 132kB/s]
99%|█████████▉| 169M/170M [25:29<00:08, 138kB/s]
99%|█████████▉| 169M/170M [25:29<00:07, 143kB/s]
99%|█████████▉| 169M/170M [25:30<00:07, 147kB/s]
99%|█████████▉| 169M/170M [25:30<00:07, 148kB/s]
99%|█████████▉| 169M/170M [25:30<00:07, 141kB/s]
99%|█████████▉| 170M/170M [25:30<00:07, 139kB/s]
99%|█████████▉| 170M/170M [25:30<00:06, 144kB/s]
99%|█████████▉| 170M/170M [25:31<00:06, 144kB/s]
99%|█████████▉| 170M/170M [25:31<00:06, 141kB/s]
99%|█████████▉| 170M/170M [25:31<00:06, 138kB/s]
100%|█████████▉| 170M/170M [25:31<00:05, 139kB/s]
100%|█████████▉| 170M/170M [25:32<00:05, 139kB/s]
100%|█████████▉| 170M/170M [25:32<00:05, 143kB/s]
100%|█████████▉| 170M/170M [25:32<00:05, 143kB/s]
100%|█████████▉| 170M/170M [25:32<00:04, 150kB/s]
100%|█████████▉| 170M/170M [25:32<00:04, 151kB/s]
100%|█████████▉| 170M/170M [25:33<00:04, 146kB/s]
100%|█████████▉| 170M/170M [25:33<00:04, 140kB/s]
100%|█████████▉| 170M/170M [25:33<00:03, 144kB/s]
100%|█████████▉| 170M/170M [25:33<00:03, 145kB/s]
100%|█████████▉| 170M/170M [25:34<00:03, 141kB/s]
100%|█████████▉| 170M/170M [25:34<00:03, 134kB/s]
100%|█████████▉| 170M/170M [25:34<00:03, 135kB/s]
100%|█████████▉| 170M/170M [25:34<00:02, 142kB/s]
100%|█████████▉| 170M/170M [25:35<00:02, 144kB/s]
100%|█████████▉| 170M/170M [25:35<00:02, 131kB/s]
100%|█████████▉| 170M/170M [25:35<00:02, 131kB/s]
100%|█████████▉| 170M/170M [25:35<00:02, 131kB/s]
100%|█████████▉| 170M/170M [25:36<00:01, 147kB/s]
100%|█████████▉| 170M/170M [25:36<00:01, 147kB/s]
100%|█████████▉| 170M/170M [25:36<00:01, 139kB/s]
100%|█████████▉| 170M/170M [25:36<00:00, 141kB/s]
100%|█████████▉| 170M/170M [25:37<00:00, 137kB/s]
100%|█████████▉| 170M/170M [25:37<00:00, 141kB/s]
100%|█████████▉| 170M/170M [25:37<00:00, 142kB/s]
100%|█████████▉| 170M/170M [25:37<00:00, 140kB/s]
100%|██████████| 170M/170M [25:37<00:00, 111kB/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torchvision/datasets/cifar.py:83: VisibleDeprecationWarning: dtype(): align should be passed as Python or NumPy boolean but got `align=0`. Did you mean to pass a tuple to create a subarray type? (Deprecated NumPy 2.4)
entry = pickle.load(f, encoding="latin1")
Dataset and data augmentations for contrastive learning¶
To perform contrastive learning, we need to define a set of data augmentations to create multiple views of the same image.
Finally we define the SSL dataloader for pretraining the models and the labelled dataloaders for testing the models.
Define augmentation transforms for contrastive learning
contrast_transforms = transforms.Compose(
[
transforms.RandomResizedCrop(size=32),
transforms.RandomHorizontalFlip(),
transforms.RandomApply(
[
transforms.ColorJitter(
brightness=0.8, contrast=0.8, saturation=0.8, hue=0.2
)
],
p=0.8,
),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
]
)
Load CIFAR10 data with contrastive transforms
train_ssl_dataset = CIFAR10(
root=data_dir,
train=True,
transform=MultiViewsTransform(contrast_transforms, n_views=2),
)
Create labelled dataloaders for the downstream task.
train_xy_loader = DataLoader(
train_xy_dataset,
batch_size=256,
shuffle=False,
drop_last=False,
num_workers=num_workers,
)
test_xy_loader = DataLoader(
test_xy_dataset,
batch_size=256,
shuffle=False,
drop_last=False,
num_workers=num_workers,
)
# We define a function that yields the data loader for
# SSL training given the batch size.
def get_ssl_loader(batch_size):
"""
Creates and returns a DataLoader for SSL training with specified batch
size.
"""
train_ssl_loader = DataLoader(
train_ssl_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=num_workers,
)
return train_ssl_loader
Model Architecture¶
Similarly to the original DCL paper, we use a ResNet18 encoder. Since CIFAR10 images are small, the kernel’s size in the first convolutional layer is decreased from 7 to 3 as reported in the ResNet paper.
def resnet18_encoder(latent_size):
"""
Creates a modified ResNet18 encoder with custom latent size for CIFAR10
images with reduced kernel size and removed max pooling.
"""
encoder = resnet18(num_classes=latent_size)
encoder.latent_size = latent_size
# Because CIFAR10 images are small, we reduce the kernel size of the first
# convolutional layer from 7 to 3.
# And remove the MaxPool layer.
encoder.conv1 = nn.Conv2d(
3, 64, kernel_size=3, stride=1, padding=1, bias=False
)
encoder.maxpool = nn.Identity()
return encoder
Defining SimCLR and DCL Models¶
Now we’ll configure the parameters for each model. We’ll train both models for 100 epochs.
%% Configure SimCLR and DCL models
def configure_models(batch_size):
simclr = SimCLR(
encoder=resnet18_encoder(latent_size),
proj_input_dim=latent_size,
proj_hidden_dim=latent_size,
proj_output_dim=latent_size,
temperature=0.07,
optimizer="sgd",
learning_rate=0.03 * batch_size / 256,
random_state=seed,
max_epochs=100,
enable_checkpointing=True,
enable_model_summary=False,
devices=1,
)
dcl = DCL(
encoder=resnet18_encoder(latent_size),
proj_input_dim=latent_size,
proj_hidden_dim=latent_size,
proj_output_dim=latent_size,
temperature=0.07,
optimizer="sgd",
learning_rate=0.03 * batch_size / 256,
random_state=seed,
max_epochs=100,
enable_checkpointing=True,
enable_model_summary=False,
devices=1,
)
return simclr, dcl
Comparing SimCLR and DCL Models for different batch sizes¶
We compare SimCLR and DCL using three batch sizes: 32, 128 and 256 and evaluate their performances on the downstream classification task.
To do so we first define a function to evaluate trained models on the CIFAR10 task with linear probing. Then we train both models for a given batch size, evaluate their performances and plot the results.
def eval_model_cifar10(model, train_xy_loader, test_xy_loader):
# We first extract the features of the train and test sets
X_train, y_train = model.transform_with_targets(train_xy_loader)
X_test, y_test = model.transform_with_targets(test_xy_loader)
X_train, y_train = X_train.cpu().numpy(), y_train.cpu().numpy()
X_test, y_test = X_test.cpu().numpy(), y_test.cpu().numpy()
# We define the linear probe
estimator = LogisticRegression(max_iter=500, random_state=seed, n_jobs=1)
# We fit the linear probe on the training set
estimator.fit(X_train, y_train)
# We predict the targets on the test set and compute accuracy
y_predict = estimator.predict(X_test)
acc = accuracy_score(y_test, y_predict)
print(f"Accuracy: {acc}")
return acc
def evaluate_models(dcl, simclr, train_xy_loader, test_xy_loader):
acc_simclr = eval_model_cifar10(simclr, train_xy_loader, test_xy_loader)
acc_dcl = eval_model_cifar10(dcl, train_xy_loader, test_xy_loader)
return acc_simclr, acc_dcl
Train models from scratch
def train_models(batch_size, simclr, dcl):
# Fit models
print(f"----------Fitting DCL for batch size = {batch_size}----------")
# Get SSL loader
train_ssl_loader = get_ssl_loader(batch_size)
dcl.fit(train_ssl_loader)
print(f"----------Fitting SimCLR for batch size = {batch_size}----------")
# Get SSL loader
train_ssl_loader = get_ssl_loader(batch_size)
simclr.fit(train_ssl_loader)
return simclr, dcl
# Load trained models' weights from HuggingFace
def load_weights(batch_size):
weights_simclr = Weights(
name="hf-hub:neurospin/nidl_example_dcl_vs_simclr",
data_dir=model_dir,
filepath=f"example_simclr_bs_{batch_size}.ckpt",
)
weights_dcl = Weights(
name="hf-hub:neurospin/nidl_example_dcl_vs_simclr",
data_dir=model_dir,
filepath=f"example_dcl_bs_{batch_size}.ckpt",
)
simclr = weights_simclr.load_checkpoint(
SimCLR,
encoder=resnet18_encoder(latent_size),
devices=1,
accelerator=accelerator,
enable_checkpointing=False,
logger=False,
)
dcl = weights_dcl.load_checkpoint(
DCL,
encoder=resnet18_encoder(latent_size),
devices=1,
accelerator=accelerator,
enable_checkpointing=False,
logger=False,
)
return simclr, dcl
Iterate over several batch sizes and save each model’s accuracy on CIFAR10
batch_sizes = [32, 128, 256]
# Store classification results
accuracies = {"simclr": [], "dcl": []}
for bs in batch_sizes:
# Load weights or else train models
if load_pretrained:
simclr, dcl = load_weights(batch_size=bs)
else:
simclr, dcl = configure_models(bs)
simclr, dcl = train_models(bs, simclr=simclr, dcl=dcl)
# Evaluate models on cifar10
acc_simclr, acc_dcl = evaluate_models(
simclr=simclr,
dcl=dcl,
train_xy_loader=train_xy_loader,
test_xy_loader=test_xy_loader,
)
accuracies["simclr"].append(acc_simclr)
accuracies["dcl"].append(acc_dcl)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40/40 0:01:15 • 0:00:00 0.55it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20/20 0:00:37 • 0:00:00 0.53it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
Accuracy: 0.639
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40/40 0:01:15 • 0:00:00 0.55it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20/20 0:00:37 • 0:00:00 0.54it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 500 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=500).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
Accuracy: 0.6782
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40/40 0:01:14 • 0:00:00 0.56it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20/20 0:00:37 • 0:00:00 0.54it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
Accuracy: 0.656
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40/40 0:01:14 • 0:00:00 0.55it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20/20 0:00:37 • 0:00:00 0.54it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
Accuracy: 0.6748
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40/40 0:01:15 • 0:00:00 0.55it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20/20 0:00:37 • 0:00:00 0.53it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
Accuracy: 0.661
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40/40 0:01:15 • 0:00:00 0.55it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20/20 0:00:37 • 0:00:00 0.54it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
Accuracy: 0.6716
Results¶
plt.plot(batch_sizes, accuracies["simclr"], label="simclr", c="b")
plt.plot(batch_sizes, accuracies["dcl"], label="dcl", c="g")
plt.xlabel("Batch size")
plt.ylabel("Accuracy on CIFAR10")
plt.title("DCL vs SimCLR comparison on predicting CIFAR10 labels.")
plt.ylim(0.5, 0.8)
plt.legend()
plt.show()
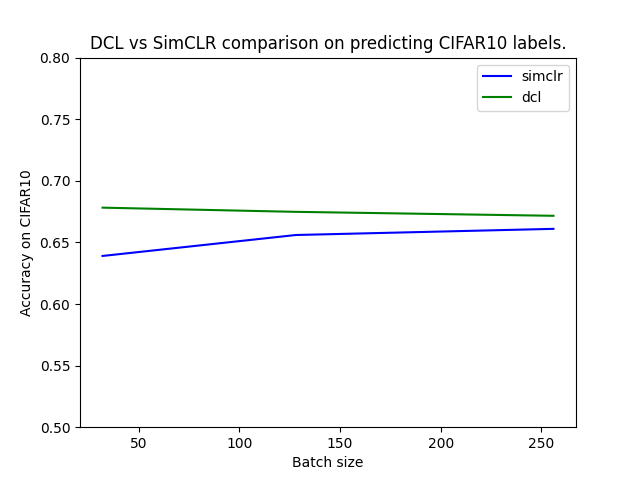
In this experiment, DCL shows improved downstream classification accuracy when trained with small batch sizes (32), with this advantage diminishing at larger batch sizes (128 and 256). Note that this example uses reduced data for linear probing and trains for only 100 epochs, compared to the original DCL paper which used 200 epochs and reports higher absolute performance and greater gains of DCL over SimCLR.
Total running time of the script: (38 minutes 22.823 seconds)
Estimated memory usage: 1223 MB