Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
nidl.losses.BarlowTwinsLoss¶
- class nidl.losses.BarlowTwinsLoss(lambd=0.005)[source]¶
Bases:
ModuleImplementation of the Barlow Twins loss [1].
Compute the Barlow Twins loss, which reduces redundancy between the components of the outputs.
Given a mini-batch of size
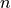 , two embeddings
, two embeddings
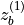 and
and 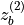 representing
two outputs of dimension
representing
two outputs of dimension 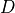 of the same sample:
of the same sample: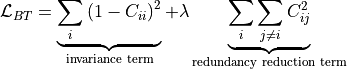
where
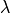 is a positive constant trading off
the importance of the first and second terms of the loss,
and where
is a positive constant trading off
the importance of the first and second terms of the loss,
and where 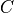 is the cross-correlation matrix computed
between the outputs of the two identical networks
along the batch dimension:
is the cross-correlation matrix computed
between the outputs of the two identical networks
along the batch dimension: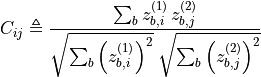
where
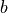 indexes batch samples
and
indexes batch samples
and 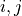 index the vector dimension of the networks outputs.
index the vector dimension of the networks outputs.- Parameters:
- lambd: float, default=5e-3
Trading off the importance of the redundancy reduction term over the invariance term.
References
[1]Zbontar, J., et al., “Barlow Twins: Self-Supervised Learning via Redundancy Reduction.” PMLR, 2021. hhttps://proceedings.mlr.press/v139/zbontar21a