Note
This page is a reference documentation. It only explains the function signature, and not how to use it. Please refer to the user guide for the big picture.
nidl.metrics.contrastive_accuracy_score¶
- nidl.metrics.contrastive_accuracy_score(z1, z2, normalize=True, topk=1, eps=1e-12)[source]¶
Compute the top-k contrastive accuracy between two embeddings.
This metric measures how often the true positive pair is among the top-k most similar candidates in the opposite view, in both directions:
For each i, treat
z1[i]as a query and all rows ofz2as a retrieval database. Check whether the matching elementz2[i]is within the top-k most similar vectors toz1[i].Symmetrically, treat
z2[i]as a query and all rows ofz1as the database, and check whetherz1[i]is within the top-k neighbors.
The final score is the average of the two directional accuracies:
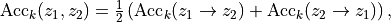
where each directional accuracy is the fraction of queries whose true pair is in the top-k most similar candidates.
Similarities are Euclidean dot-product between the embeddings. The score is in the range
[0, 1], where higher is better.- Parameters:
- z1torch.Tensor or np.ndarray, shape (n_samples, n_features)
Embeddings from the first view / augmentation.
- z2torch.Tensor or np.ndarray, shape (n_samples, n_features)
Embeddings from the second view / augmentation. Must have the same shape as
z1.- normalizebool, default=True
If True, each embedding vector is L2-normalized along the feature dimension before computing similarities. This makes the metric equivalent to using cosine similarity. If False, raw dot products are used.
- topkint, default=1
The “k” in “top-k”. For each query, we check whether the true counterpart index
iis contained in the indices of the top-k most similar candidates. Iftopkis greater than the number of samples, it is automatically clipped.- epsfloat, default=1e-12
Small constant used to avoid division by zero during normalization.
- Returns:
- scoretorch.Tensor or numpy scalar
The contrastive top-k accuracy:
If inputs are
torch.Tensor→ returns a 0-dimtorch.Tensor.If inputs are
np.ndarray→ returns a NumPy scalar.
- Raises:
- TypeError
If
z1andz2are not both torch tensors or both NumPy arrays.- ValueError
If shapes of
z1andz2do not match, or if they are not 2-dimensional, or iftopk < 1.
Examples
>>> z1 = torch.randn(8, 128) >>> z2 = z1 + 0.1 * torch.randn(8, 128) # slightly perturbed positives >>> contrastive_accuracy_score(z1, z2, topk=1) tensor(1.) # often close to 1 for this synthetic example
Examples using nidl.metrics.contrastive_accuracy_score¶

Visualization of metrics during training of PyTorch-Lightning models