Note
Go to the end to download the full example code.
Self-Supervised Learning with I-JEPA on MedMNIST3D¶
This example demonstrates how to pretrain a 3D vision transformer with I-JEPA [1] on a MedMNIST3D dataset [2] using the nidl library. It will also show you how to evaluate the learned representations with a simple linear probe.
I-JEPA: the key idea behind I-JEPA is to learn representations by predicting masked-out image blocks from their surrounding context in the latent space . This is the main difference with Masked Autoencoders (MAE) which predicts the masked-out blocks in the pixel space.
3D adaptation: I-JEPA is designed to be flexible. Even if the original implementation only used 2d images, its extension to 3d volumes is straightforward. There are two key differences with the 2d case: the tokenization is performed with 3D patches, and the positional embeddings are 3D as well. As for the masking strategy, it follows the same random block subsampling strategy as in 2d.
In this tutorial, we will follow these steps:
Load a MedMNIST3D dataset.
Build a 3D vision transformer encoder.
Train an I-JEPA model, or optionally load pretrained weights from the Hugging Face Hub.
Evaluate the pretrained encoder on the downstream classification task with a logistic regression probe.
In this example we use OrganMNIST3D, one of the 3D datasets distributed by
MedMNIST. MedMNIST3D datasets are lightweight 3D medical image classification
benchmarks standardized to a common spatial size, which makes them convenient
for prototyping self-supervised pipelines.
Setup¶
This example requires medmnist in addition to nidl. If you want to load
pretrained weights from the Hugging Face Hub, you also need
huggingface_hub installed in your environment.
from __future__ import annotations
import os
from typing import Callable, Optional
import matplotlib.pyplot as plt
import medmnist
import numpy as np
import torch
from lightning_fabric import seed_everything
from medmnist import INFO
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from torch.utils.data import DataLoader
from torchvision.transforms import Compose
from nidl.backbones.volume import VisionTransformer3D
from nidl.estimators.ssl import IJEPA
from nidl.transforms.volume.augmentation import RandomResizedCrop
from nidl.transforms.volume.preprocessing import ZNormalization
from nidl.utils.weights import Weights
We define some global parameters that will be used throughout the example.
Training a 3D I-JEPA model can take substantial time depending on your
hardware. By default, this example trains a lightweight configuration that is
suitable for a tutorial. If you later publish pretrained weights to the
Hugging Face Hub, set load_pretrained = True and fill the corresponding
repository information below.
Data-related parameters
# Directory where to download MedMNIST data
data_dir = "/tmp/medmnist"
# Directory where to cache optional pretrained weights
model_dir = "/tmp/nidl_example_ijepa_medmnist"
# MedMNIST3D dataset to use
dataset_name = "organmnist3d"
# Spatial size used by MedMNIST+ for 3D datasets
img_size = 64
# Whether to load a pretrained checkpoint from HF or train locally
load_pretrained = True
# Fill these two values once a checkpoint is published on HF
hf_repo_id = "neurospin/nidl_example_ijepa_medmnist"
hf_checkpoint = "nidl_example_ijepa_medmnist.pt"
Reproducibility and training configuration
# What accelerator to use: GPU if available, else CPU
accelerator = "gpu" if torch.cuda.is_available() else "cpu"
# Parameters for the data loaders. Reduce them if you run out of memory.
batch_size = 16
num_workers = 4
# Training configuration
max_epochs = 20
learning_rate = 3e-4
weight_decay = 5e-4
random_seed = 42
seed_everything(random_seed)
rd_generator = np.random.default_rng(seed=random_seed)
Data preparation¶
We first define a small MedMNIST3D dataset wrapper and the transforms used for self-supervised pretraining and downstream evaluation.
class MedMNIST3DDataset:
"""Simple wrapper around a MedMNIST3D split."""
def __init__(
self,
dataset_name: str,
root: str,
split: str,
transform: Optional[Callable] = None,
size: int = 64,
download: bool = True,
):
dataset_name = dataset_name.lower()
if dataset_name not in INFO:
raise ValueError(
f"Unknown MedMNIST dataset '{dataset_name}'. "
f"Available datasets include: {sorted(INFO.keys())}"
)
if "3d" not in dataset_name:
raise ValueError(
f"This example is written for MedMNIST3D datasets, got "
f"'{dataset_name}'."
)
info = INFO[dataset_name]
dataset_cls = getattr(medmnist, info["python_class"])
os.makedirs(root, exist_ok=True)
self.dataset = dataset_cls(
split=split,
root=root,
transform=transform,
download=download,
size=size,
as_rgb=False,
)
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
return self.dataset[index]
train_transform = Compose(
[
RandomResizedCrop(img_size, scale=(0.5, 1.0)),
ZNormalization(),
lambda x: torch.from_numpy(x).float(),
]
)
eval_transform = Compose(
[
ZNormalization(),
lambda x: torch.from_numpy(x).float(),
]
)
We create one dataset for self-supervised training, and labeled datasets for linear probing.
ssl_dataset = MedMNIST3DDataset(
dataset_name=dataset_name,
root=data_dir,
split="train",
transform=train_transform,
size=img_size,
)
train_xy_dataset = MedMNIST3DDataset(
dataset_name=dataset_name,
root=data_dir,
split="train",
transform=eval_transform,
size=img_size,
)
test_xy_dataset = MedMNIST3DDataset(
dataset_name=dataset_name,
root=data_dir,
split="test",
transform=eval_transform,
size=img_size,
)
0%| | 0.00/361M [00:00<?, ?B/s]
0%| | 65.5k/361M [00:00<17:32, 343kB/s]
0%| | 164k/361M [00:00<10:44, 560kB/s]
0%| | 229k/361M [00:00<12:24, 485kB/s]
0%| | 360k/361M [00:00<08:50, 681kB/s]
0%| | 524k/361M [00:00<07:57, 756kB/s]
0%| | 688k/361M [00:00<07:34, 793kB/s]
0%| | 852k/361M [00:01<07:23, 814kB/s]
0%| | 950k/361M [00:01<07:05, 847kB/s]
0%| | 1.15M/361M [00:01<06:54, 870kB/s]
0%| | 1.25M/361M [00:01<06:46, 886kB/s]
0%| | 1.41M/361M [00:01<06:52, 873kB/s]
0%| | 1.61M/361M [00:01<06:29, 923kB/s]
0%| | 1.80M/361M [00:02<06:16, 956kB/s]
1%| | 2.00M/361M [00:02<06:07, 979kB/s]
1%| | 2.20M/361M [00:02<06:01, 993kB/s]
1%| | 2.39M/361M [00:02<05:57, 1.00MB/s]
1%| | 2.59M/361M [00:02<06:00, 995kB/s]
1%| | 2.85M/361M [00:03<05:25, 1.10MB/s]
1%| | 3.05M/361M [00:03<05:32, 1.08MB/s]
1%| | 3.24M/361M [00:03<05:37, 1.06MB/s]
1%| | 3.47M/361M [00:03<05:25, 1.10MB/s]
1%| | 3.70M/361M [00:03<05:18, 1.12MB/s]
1%| | 3.87M/361M [00:04<05:42, 1.04MB/s]
1%| | 4.16M/361M [00:04<05:00, 1.19MB/s]
1%| | 4.39M/361M [00:04<04:59, 1.19MB/s]
1%|▏ | 4.62M/361M [00:04<04:59, 1.19MB/s]
1%|▏ | 4.85M/361M [00:04<04:58, 1.19MB/s]
1%|▏ | 5.08M/361M [00:05<05:17, 1.12MB/s]
1%|▏ | 5.21M/361M [00:05<05:18, 1.12MB/s]
1%|▏ | 5.41M/361M [00:05<05:28, 1.08MB/s]
2%|▏ | 5.60M/361M [00:05<05:34, 1.06MB/s]
2%|▏ | 5.83M/361M [00:05<05:23, 1.10MB/s]
2%|▏ | 6.03M/361M [00:06<05:30, 1.08MB/s]
2%|▏ | 6.23M/361M [00:06<04:47, 1.24MB/s]
2%|▏ | 6.39M/361M [00:06<04:32, 1.30MB/s]
2%|▏ | 6.55M/361M [00:06<05:09, 1.15MB/s]
2%|▏ | 6.72M/361M [00:06<05:38, 1.05MB/s]
2%|▏ | 6.91M/361M [00:06<05:40, 1.04MB/s]
2%|▏ | 7.14M/361M [00:06<05:25, 1.09MB/s]
2%|▏ | 7.47M/361M [00:07<04:35, 1.28MB/s]
2%|▏ | 7.63M/361M [00:07<04:22, 1.35MB/s]
2%|▏ | 7.83M/361M [00:07<04:45, 1.24MB/s]
2%|▏ | 8.19M/361M [00:07<04:03, 1.45MB/s]
2%|▏ | 8.52M/361M [00:07<03:50, 1.53MB/s]
2%|▏ | 8.81M/361M [00:08<03:50, 1.53MB/s]
3%|▎ | 9.11M/361M [00:08<03:53, 1.51MB/s]
3%|▎ | 9.27M/361M [00:08<03:55, 1.50MB/s]
3%|▎ | 9.50M/361M [00:08<04:12, 1.39MB/s]
3%|▎ | 9.73M/361M [00:08<04:24, 1.33MB/s]
3%|▎ | 9.96M/361M [00:08<04:33, 1.29MB/s]
3%|▎ | 10.2M/361M [00:09<04:52, 1.20MB/s]
3%|▎ | 10.4M/361M [00:09<04:52, 1.20MB/s]
3%|▎ | 10.6M/361M [00:09<04:52, 1.20MB/s]
3%|▎ | 10.9M/361M [00:09<04:40, 1.25MB/s]
3%|▎ | 11.0M/361M [00:09<04:45, 1.23MB/s]
3%|▎ | 11.1M/361M [00:10<05:30, 1.06MB/s]
3%|▎ | 11.3M/361M [00:10<05:33, 1.05MB/s]
3%|▎ | 11.6M/361M [00:10<05:19, 1.09MB/s]
3%|▎ | 11.9M/361M [00:10<04:32, 1.28MB/s]
3%|▎ | 12.0M/361M [00:10<04:35, 1.27MB/s]
3%|▎ | 12.2M/361M [00:10<05:07, 1.14MB/s]
3%|▎ | 12.4M/361M [00:11<05:18, 1.10MB/s]
3%|▎ | 12.6M/361M [00:11<05:09, 1.13MB/s]
4%|▎ | 12.8M/361M [00:11<05:18, 1.09MB/s]
4%|▎ | 13.0M/361M [00:11<05:09, 1.13MB/s]
4%|▎ | 13.5M/361M [00:11<03:58, 1.46MB/s]
4%|▍ | 13.7M/361M [00:12<04:12, 1.38MB/s]
4%|▍ | 13.9M/361M [00:12<04:44, 1.22MB/s]
4%|▍ | 14.1M/361M [00:12<04:59, 1.16MB/s]
4%|▍ | 14.3M/361M [00:12<04:44, 1.22MB/s]
4%|▍ | 14.5M/361M [00:12<05:13, 1.11MB/s]
4%|▍ | 14.6M/361M [00:12<05:05, 1.14MB/s]
4%|▍ | 14.9M/361M [00:13<04:47, 1.21MB/s]
4%|▍ | 15.0M/361M [00:13<05:16, 1.09MB/s]
4%|▍ | 15.3M/361M [00:13<04:53, 1.18MB/s]
4%|▍ | 15.5M/361M [00:13<05:20, 1.08MB/s]
4%|▍ | 15.8M/361M [00:13<04:43, 1.22MB/s]
4%|▍ | 16.1M/361M [00:14<04:12, 1.37MB/s]
5%|▍ | 16.3M/361M [00:14<04:33, 1.26MB/s]
5%|▍ | 16.5M/361M [00:14<04:50, 1.19MB/s]
5%|▍ | 16.7M/361M [00:14<05:02, 1.14MB/s]
5%|▍ | 16.9M/361M [00:14<05:12, 1.10MB/s]
5%|▍ | 17.1M/361M [00:15<05:20, 1.08MB/s]
5%|▍ | 17.3M/361M [00:15<04:56, 1.16MB/s]
5%|▍ | 17.5M/361M [00:15<05:07, 1.12MB/s]
5%|▍ | 17.9M/361M [00:15<04:25, 1.29MB/s]
5%|▌ | 18.2M/361M [00:15<04:11, 1.36MB/s]
5%|▌ | 18.4M/361M [00:15<04:32, 1.26MB/s]
5%|▌ | 18.5M/361M [00:16<04:07, 1.39MB/s]
5%|▌ | 18.7M/361M [00:16<04:44, 1.21MB/s]
5%|▌ | 19.0M/361M [00:16<04:32, 1.26MB/s]
5%|▌ | 19.3M/361M [00:16<03:55, 1.45MB/s]
5%|▌ | 19.6M/361M [00:16<03:59, 1.43MB/s]
5%|▌ | 19.8M/361M [00:17<04:12, 1.35MB/s]
6%|▌ | 20.1M/361M [00:17<04:21, 1.31MB/s]
6%|▌ | 20.3M/361M [00:17<04:39, 1.22MB/s]
6%|▌ | 20.6M/361M [00:17<04:08, 1.37MB/s]
6%|▌ | 20.8M/361M [00:17<04:18, 1.32MB/s]
6%|▌ | 21.1M/361M [00:18<03:56, 1.44MB/s]
6%|▌ | 21.4M/361M [00:18<03:52, 1.46MB/s]
6%|▌ | 21.6M/361M [00:18<04:15, 1.33MB/s]
6%|▌ | 22.0M/361M [00:18<03:55, 1.44MB/s]
6%|▌ | 22.2M/361M [00:18<03:51, 1.47MB/s]
6%|▌ | 22.5M/361M [00:18<04:05, 1.38MB/s]
6%|▋ | 22.7M/361M [00:19<03:49, 1.47MB/s]
6%|▋ | 22.8M/361M [00:19<03:46, 1.49MB/s]
6%|▋ | 23.0M/361M [00:19<04:28, 1.26MB/s]
6%|▋ | 23.3M/361M [00:19<03:59, 1.41MB/s]
7%|▋ | 23.5M/361M [00:19<04:23, 1.28MB/s]
7%|▋ | 23.7M/361M [00:19<04:41, 1.20MB/s]
7%|▋ | 24.0M/361M [00:20<04:41, 1.20MB/s]
7%|▋ | 24.2M/361M [00:20<04:54, 1.15MB/s]
7%|▋ | 24.4M/361M [00:20<04:50, 1.16MB/s]
7%|▋ | 24.8M/361M [00:20<03:55, 1.43MB/s]
7%|▋ | 25.1M/361M [00:20<03:49, 1.46MB/s]
7%|▋ | 25.2M/361M [00:21<03:45, 1.49MB/s]
7%|▋ | 25.4M/361M [00:21<04:22, 1.28MB/s]
7%|▋ | 25.6M/361M [00:21<04:28, 1.25MB/s]
7%|▋ | 25.9M/361M [00:21<04:14, 1.32MB/s]
7%|▋ | 26.1M/361M [00:21<04:34, 1.22MB/s]
7%|▋ | 26.3M/361M [00:21<05:01, 1.11MB/s]
7%|▋ | 26.5M/361M [00:22<04:42, 1.19MB/s]
7%|▋ | 26.8M/361M [00:22<04:29, 1.24MB/s]
8%|▊ | 27.1M/361M [00:22<04:02, 1.38MB/s]
8%|▊ | 27.4M/361M [00:22<04:03, 1.37MB/s]
8%|▊ | 27.6M/361M [00:22<04:12, 1.32MB/s]
8%|▊ | 28.0M/361M [00:23<03:52, 1.44MB/s]
8%|▊ | 28.1M/361M [00:23<04:14, 1.31MB/s]
8%|▊ | 28.4M/361M [00:23<04:10, 1.33MB/s]
8%|▊ | 28.6M/361M [00:23<04:18, 1.29MB/s]
8%|▊ | 28.9M/361M [00:23<04:23, 1.26MB/s]
8%|▊ | 29.0M/361M [00:24<04:23, 1.26MB/s]
8%|▊ | 29.2M/361M [00:24<04:54, 1.13MB/s]
8%|▊ | 29.4M/361M [00:24<05:02, 1.10MB/s]
8%|▊ | 29.6M/361M [00:24<04:54, 1.13MB/s]
8%|▊ | 29.8M/361M [00:24<05:18, 1.04MB/s]
8%|▊ | 30.0M/361M [00:24<04:50, 1.14MB/s]
8%|▊ | 30.2M/361M [00:25<04:45, 1.16MB/s]
8%|▊ | 30.5M/361M [00:25<04:42, 1.17MB/s]
8%|▊ | 30.7M/361M [00:25<04:40, 1.18MB/s]
9%|▊ | 30.9M/361M [00:25<04:39, 1.18MB/s]
9%|▊ | 31.3M/361M [00:25<03:48, 1.44MB/s]
9%|▊ | 31.5M/361M [00:26<03:46, 1.46MB/s]
9%|▉ | 31.7M/361M [00:26<04:12, 1.31MB/s]
9%|▉ | 31.9M/361M [00:26<04:43, 1.16MB/s]
9%|▉ | 32.0M/361M [00:26<05:06, 1.07MB/s]
9%|▉ | 32.1M/361M [00:26<05:47, 948kB/s]
9%|▉ | 32.3M/361M [00:26<05:21, 1.02MB/s]
9%|▉ | 32.5M/361M [00:27<05:20, 1.02MB/s]
9%|▉ | 32.8M/361M [00:27<04:52, 1.12MB/s]
9%|▉ | 33.0M/361M [00:27<05:00, 1.09MB/s]
9%|▉ | 33.2M/361M [00:27<05:05, 1.07MB/s]
9%|▉ | 33.4M/361M [00:27<04:54, 1.11MB/s]
9%|▉ | 33.7M/361M [00:28<04:48, 1.14MB/s]
9%|▉ | 33.8M/361M [00:28<04:56, 1.10MB/s]
9%|▉ | 34.0M/361M [00:28<05:03, 1.08MB/s]
9%|▉ | 34.2M/361M [00:28<05:10, 1.06MB/s]
10%|▉ | 34.4M/361M [00:28<04:57, 1.10MB/s]
10%|▉ | 34.5M/361M [00:28<05:39, 962kB/s]
10%|▉ | 34.8M/361M [00:29<05:00, 1.09MB/s]
10%|▉ | 35.1M/361M [00:29<04:14, 1.28MB/s]
10%|▉ | 35.3M/361M [00:29<04:21, 1.25MB/s]
10%|▉ | 35.5M/361M [00:29<04:20, 1.25MB/s]
10%|▉ | 35.7M/361M [00:29<03:52, 1.40MB/s]
10%|▉ | 35.8M/361M [00:29<04:31, 1.20MB/s]
10%|▉ | 36.0M/361M [00:30<04:46, 1.14MB/s]
10%|█ | 36.3M/361M [00:30<04:28, 1.21MB/s]
10%|█ | 36.5M/361M [00:30<04:42, 1.15MB/s]
10%|█ | 36.6M/361M [00:30<05:06, 1.06MB/s]
10%|█ | 36.9M/361M [00:30<04:41, 1.15MB/s]
10%|█ | 37.1M/361M [00:31<05:05, 1.06MB/s]
10%|█ | 37.3M/361M [00:31<05:08, 1.05MB/s]
10%|█ | 37.6M/361M [00:31<04:20, 1.24MB/s]
10%|█ | 37.8M/361M [00:31<04:34, 1.18MB/s]
11%|█ | 38.0M/361M [00:31<04:34, 1.18MB/s]
11%|█ | 38.2M/361M [00:32<04:33, 1.18MB/s]
11%|█ | 38.5M/361M [00:32<04:31, 1.19MB/s]
11%|█ | 38.7M/361M [00:32<04:31, 1.19MB/s]
11%|█ | 38.9M/361M [00:32<04:42, 1.14MB/s]
11%|█ | 39.1M/361M [00:32<04:38, 1.16MB/s]
11%|█ | 39.5M/361M [00:33<04:03, 1.32MB/s]
11%|█ | 39.7M/361M [00:33<03:52, 1.38MB/s]
11%|█ | 40.0M/361M [00:33<04:02, 1.33MB/s]
11%|█ | 40.2M/361M [00:33<04:09, 1.29MB/s]
11%|█ | 40.5M/361M [00:33<04:04, 1.31MB/s]
11%|█▏ | 40.7M/361M [00:34<04:12, 1.27MB/s]
11%|█▏ | 40.9M/361M [00:34<04:00, 1.34MB/s]
11%|█▏ | 41.0M/361M [00:34<04:32, 1.18MB/s]
11%|█▏ | 41.3M/361M [00:34<04:22, 1.22MB/s]
11%|█▏ | 41.5M/361M [00:34<04:25, 1.20MB/s]
12%|█▏ | 41.8M/361M [00:34<04:15, 1.25MB/s]
12%|█▏ | 41.9M/361M [00:35<04:42, 1.13MB/s]
12%|█▏ | 42.1M/361M [00:35<05:04, 1.05MB/s]
12%|█▏ | 42.3M/361M [00:35<04:52, 1.09MB/s]
12%|█▏ | 42.7M/361M [00:35<03:59, 1.33MB/s]
12%|█▏ | 42.9M/361M [00:35<04:06, 1.29MB/s]
12%|█▏ | 43.2M/361M [00:36<04:12, 1.26MB/s]
12%|█▏ | 43.5M/361M [00:36<03:56, 1.35MB/s]
12%|█▏ | 43.7M/361M [00:36<04:04, 1.30MB/s]
12%|█▏ | 43.9M/361M [00:36<04:00, 1.32MB/s]
12%|█▏ | 44.2M/361M [00:36<03:50, 1.38MB/s]
12%|█▏ | 44.4M/361M [00:37<04:09, 1.27MB/s]
12%|█▏ | 44.7M/361M [00:37<04:03, 1.30MB/s]
12%|█▏ | 44.9M/361M [00:37<04:32, 1.16MB/s]
12%|█▏ | 45.1M/361M [00:37<04:18, 1.22MB/s]
13%|█▎ | 45.4M/361M [00:37<04:20, 1.22MB/s]
13%|█▎ | 45.6M/361M [00:37<04:01, 1.31MB/s]
13%|█▎ | 46.0M/361M [00:38<03:41, 1.43MB/s]
13%|█▎ | 46.1M/361M [00:38<04:10, 1.26MB/s]
13%|█▎ | 46.4M/361M [00:38<03:54, 1.34MB/s]
13%|█▎ | 46.7M/361M [00:38<04:03, 1.29MB/s]
13%|█▎ | 46.9M/361M [00:38<04:09, 1.26MB/s]
13%|█▎ | 47.1M/361M [00:39<04:24, 1.19MB/s]
13%|█▎ | 47.8M/361M [00:39<02:21, 2.22MB/s]
13%|█▎ | 48.7M/361M [00:39<01:42, 3.05MB/s]
14%|█▍ | 50.9M/361M [00:39<00:45, 6.88MB/s]
15%|█▍ | 52.6M/361M [00:39<00:40, 7.69MB/s]
16%|█▌ | 56.3M/361M [00:39<00:22, 13.9MB/s]
16%|█▌ | 58.6M/361M [00:39<00:19, 15.9MB/s]
17%|█▋ | 60.5M/361M [00:39<00:18, 16.7MB/s]
17%|█▋ | 62.4M/361M [00:40<00:35, 8.38MB/s]
18%|█▊ | 63.9M/361M [00:40<00:47, 6.30MB/s]
18%|█▊ | 65.0M/361M [00:41<00:58, 5.09MB/s]
18%|█▊ | 65.9M/361M [00:41<00:59, 4.93MB/s]
18%|█▊ | 66.6M/361M [00:41<01:02, 4.69MB/s]
19%|█▊ | 67.3M/361M [00:41<01:06, 4.42MB/s]
19%|█▉ | 67.8M/361M [00:41<01:04, 4.56MB/s]
19%|█▉ | 68.4M/361M [00:42<01:10, 4.13MB/s]
19%|█▉ | 68.9M/361M [00:42<01:08, 4.24MB/s]
19%|█▉ | 69.4M/361M [00:42<01:18, 3.74MB/s]
19%|█▉ | 69.9M/361M [00:42<01:11, 4.07MB/s]
19%|█▉ | 70.5M/361M [00:42<01:18, 3.72MB/s]
20%|█▉ | 71.0M/361M [00:42<01:11, 4.07MB/s]
20%|█▉ | 71.6M/361M [00:43<01:18, 3.71MB/s]
20%|█▉ | 72.0M/361M [00:43<01:16, 3.80MB/s]
20%|██ | 72.5M/361M [00:43<01:14, 3.89MB/s]
20%|██ | 72.9M/361M [00:43<01:24, 3.42MB/s]
20%|██ | 73.5M/361M [00:43<01:15, 3.82MB/s]
20%|██ | 74.0M/361M [00:43<01:14, 3.87MB/s]
21%|██ | 74.4M/361M [00:43<01:21, 3.53MB/s]
21%|██ | 74.9M/361M [00:43<01:16, 3.75MB/s]
21%|██ | 75.4M/361M [00:44<01:22, 3.47MB/s]
21%|██ | 76.1M/361M [00:44<01:11, 3.97MB/s]
21%|██ | 76.6M/361M [00:44<01:17, 3.70MB/s]
21%|██▏ | 77.1M/361M [00:44<01:12, 3.92MB/s]
21%|██▏ | 77.7M/361M [00:44<01:18, 3.61MB/s]
22%|██▏ | 78.2M/361M [00:44<01:12, 3.91MB/s]
22%|██▏ | 78.6M/361M [00:45<01:49, 2.59MB/s]
22%|██▏ | 79.1M/361M [00:45<01:33, 3.01MB/s]
22%|██▏ | 79.5M/361M [00:45<01:43, 2.71MB/s]
22%|██▏ | 80.2M/361M [00:45<01:33, 3.00MB/s]
22%|██▏ | 80.7M/361M [00:45<01:23, 3.36MB/s]
22%|██▏ | 81.3M/361M [00:45<01:27, 3.21MB/s]
23%|██▎ | 81.6M/361M [00:45<01:25, 3.28MB/s]
23%|██▎ | 82.3M/361M [00:46<01:17, 3.61MB/s]
24%|██▍ | 86.3M/361M [00:46<00:24, 11.2MB/s]
25%|██▍ | 90.1M/361M [00:46<00:15, 17.3MB/s]
26%|██▌ | 93.7M/361M [00:46<00:12, 21.7MB/s]
27%|██▋ | 97.4M/361M [00:46<00:10, 25.3MB/s]
28%|██▊ | 101M/361M [00:46<00:08, 29.0MB/s]
29%|██▉ | 105M/361M [00:46<00:08, 30.3MB/s]
30%|███ | 109M/361M [00:46<00:07, 32.2MB/s]
31%|███ | 112M/361M [00:47<00:24, 10.1MB/s]
32%|███▏ | 115M/361M [00:48<00:30, 8.11MB/s]
32%|███▏ | 117M/361M [00:48<00:28, 8.48MB/s]
33%|███▎ | 121M/361M [00:48<00:19, 12.4MB/s]
34%|███▍ | 124M/361M [00:48<00:15, 14.9MB/s]
35%|███▌ | 127M/361M [00:48<00:13, 17.9MB/s]
36%|███▋ | 131M/361M [00:48<00:10, 21.9MB/s]
37%|███▋ | 135M/361M [00:48<00:08, 25.5MB/s]
39%|███▊ | 139M/361M [00:49<00:07, 28.4MB/s]
40%|███▉ | 143M/361M [00:49<00:06, 31.2MB/s]
41%|████ | 148M/361M [00:49<00:06, 33.8MB/s]
42%|████▏ | 151M/361M [00:49<00:14, 14.5MB/s]
43%|████▎ | 154M/361M [00:50<00:23, 8.88MB/s]
43%|████▎ | 156M/361M [00:51<00:28, 7.29MB/s]
44%|████▎ | 158M/361M [00:51<00:31, 6.43MB/s]
44%|████▍ | 159M/361M [00:51<00:31, 6.43MB/s]
44%|████▍ | 160M/361M [00:51<00:32, 6.27MB/s]
45%|████▍ | 161M/361M [00:52<00:37, 5.40MB/s]
45%|████▍ | 162M/361M [00:52<00:38, 5.15MB/s]
45%|████▍ | 163M/361M [00:53<01:08, 2.92MB/s]
45%|████▌ | 163M/361M [00:53<00:59, 3.30MB/s]
45%|████▌ | 164M/361M [00:53<01:01, 3.23MB/s]
46%|████▌ | 165M/361M [00:53<00:58, 3.39MB/s]
46%|████▌ | 165M/361M [00:53<00:53, 3.65MB/s]
46%|████▌ | 166M/361M [00:53<00:48, 4.04MB/s]
46%|████▋ | 167M/361M [00:54<00:40, 4.82MB/s]
46%|████▋ | 168M/361M [00:54<00:45, 4.29MB/s]
47%|████▋ | 169M/361M [00:54<00:46, 4.12MB/s]
47%|████▋ | 169M/361M [00:54<00:46, 4.16MB/s]
47%|████▋ | 170M/361M [00:54<00:43, 4.35MB/s]
47%|████▋ | 171M/361M [00:55<00:46, 4.06MB/s]
47%|████▋ | 172M/361M [00:55<00:45, 4.15MB/s]
48%|████▊ | 172M/361M [00:55<00:41, 4.60MB/s]
48%|████▊ | 173M/361M [00:55<00:40, 4.64MB/s]
48%|████▊ | 173M/361M [00:55<00:40, 4.62MB/s]
48%|████▊ | 174M/361M [00:55<00:43, 4.27MB/s]
48%|████▊ | 175M/361M [00:55<00:39, 4.70MB/s]
48%|████▊ | 175M/361M [00:55<00:42, 4.38MB/s]
49%|████▊ | 176M/361M [00:56<00:37, 4.94MB/s]
49%|████▉ | 177M/361M [00:56<00:41, 4.46MB/s]
49%|████▉ | 177M/361M [00:56<00:36, 5.00MB/s]
49%|████▉ | 178M/361M [00:56<00:42, 4.31MB/s]
49%|████▉ | 179M/361M [00:56<00:38, 4.73MB/s]
50%|████▉ | 179M/361M [00:56<00:45, 3.99MB/s]
50%|████▉ | 180M/361M [00:56<00:46, 3.90MB/s]
50%|████▉ | 180M/361M [00:57<00:46, 3.93MB/s]
50%|████▉ | 181M/361M [00:57<00:48, 3.74MB/s]
50%|█████ | 181M/361M [00:57<00:43, 4.15MB/s]
50%|█████ | 182M/361M [00:57<00:42, 4.19MB/s]
51%|█████ | 183M/361M [00:57<00:40, 4.39MB/s]
51%|█████ | 184M/361M [00:57<00:40, 4.41MB/s]
51%|█████ | 185M/361M [00:58<00:39, 4.48MB/s]
51%|█████▏ | 186M/361M [00:58<00:37, 4.63MB/s]
52%|█████▏ | 187M/361M [00:58<00:37, 4.62MB/s]
52%|█████▏ | 187M/361M [00:58<00:36, 4.76MB/s]
52%|█████▏ | 188M/361M [00:58<00:37, 4.67MB/s]
52%|█████▏ | 189M/361M [00:59<00:38, 4.44MB/s]
52%|█████▏ | 190M/361M [00:59<00:37, 4.59MB/s]
53%|█████▎ | 190M/361M [00:59<00:36, 4.68MB/s]
53%|█████▎ | 191M/361M [00:59<00:42, 4.04MB/s]
53%|█████▎ | 191M/361M [00:59<00:42, 4.01MB/s]
53%|█████▎ | 192M/361M [00:59<00:37, 4.52MB/s]
53%|█████▎ | 192M/361M [00:59<00:40, 4.20MB/s]
53%|█████▎ | 193M/361M [00:59<00:38, 4.39MB/s]
54%|█████▎ | 193M/361M [01:00<00:40, 4.19MB/s]
54%|█████▎ | 194M/361M [01:00<00:38, 4.32MB/s]
54%|█████▍ | 195M/361M [01:00<00:37, 4.42MB/s]
54%|█████▍ | 195M/361M [01:00<00:35, 4.62MB/s]
54%|█████▍ | 196M/361M [01:00<00:37, 4.44MB/s]
55%|█████▍ | 197M/361M [01:00<00:35, 4.63MB/s]
55%|█████▍ | 198M/361M [01:01<00:34, 4.74MB/s]
55%|█████▍ | 199M/361M [01:01<00:32, 4.97MB/s]
55%|█████▌ | 199M/361M [01:01<00:34, 4.66MB/s]
55%|█████▌ | 200M/361M [01:01<00:33, 4.78MB/s]
55%|█████▌ | 200M/361M [01:01<00:37, 4.33MB/s]
56%|█████▌ | 201M/361M [01:01<00:37, 4.33MB/s]
56%|█████▌ | 201M/361M [01:01<00:35, 4.51MB/s]
56%|█████▌ | 202M/361M [01:01<00:35, 4.48MB/s]
56%|█████▌ | 203M/361M [01:02<00:36, 4.39MB/s]
56%|█████▌ | 203M/361M [01:02<00:36, 4.30MB/s]
56%|█████▋ | 204M/361M [01:02<00:34, 4.58MB/s]
57%|█████▋ | 204M/361M [01:02<00:36, 4.30MB/s]
57%|█████▋ | 205M/361M [01:02<00:32, 4.76MB/s]
57%|█████▋ | 206M/361M [01:02<00:34, 4.56MB/s]
57%|█████▋ | 206M/361M [01:02<00:34, 4.54MB/s]
57%|█████▋ | 207M/361M [01:03<00:34, 4.48MB/s]
57%|█████▋ | 208M/361M [01:03<00:33, 4.53MB/s]
58%|█████▊ | 209M/361M [01:03<00:28, 5.31MB/s]
58%|█████▊ | 209M/361M [01:03<00:33, 4.51MB/s]
58%|█████▊ | 210M/361M [01:03<00:30, 4.95MB/s]
58%|█████▊ | 211M/361M [01:03<00:34, 4.42MB/s]
58%|█████▊ | 211M/361M [01:03<00:34, 4.38MB/s]
59%|█████▊ | 211M/361M [01:04<00:33, 4.47MB/s]
59%|█████▊ | 212M/361M [01:04<00:36, 4.07MB/s]
59%|█████▉ | 213M/361M [01:04<00:33, 4.44MB/s]
59%|█████▉ | 213M/361M [01:04<00:31, 4.69MB/s]
59%|█████▉ | 214M/361M [01:04<00:36, 4.07MB/s]
59%|█████▉ | 215M/361M [01:04<00:28, 5.18MB/s]
60%|█████▉ | 215M/361M [01:04<00:33, 4.37MB/s]
60%|█████▉ | 216M/361M [01:05<00:32, 4.45MB/s]
60%|██████ | 217M/361M [01:05<00:32, 4.45MB/s]
60%|██████ | 218M/361M [01:05<00:32, 4.45MB/s]
61%|██████ | 219M/361M [01:05<00:41, 3.41MB/s]
61%|██████ | 219M/361M [01:05<00:40, 3.48MB/s]
61%|██████ | 220M/361M [01:06<00:35, 4.01MB/s]
61%|██████ | 220M/361M [01:06<00:38, 3.67MB/s]
61%|██████ | 221M/361M [01:06<00:39, 3.54MB/s]
61%|██████▏ | 222M/361M [01:06<00:37, 3.72MB/s]
61%|██████▏ | 222M/361M [01:06<00:35, 3.88MB/s]
62%|██████▏ | 223M/361M [01:06<00:36, 3.85MB/s]
62%|██████▏ | 223M/361M [01:06<00:35, 3.92MB/s]
62%|██████▏ | 224M/361M [01:07<00:33, 4.15MB/s]
62%|██████▏ | 225M/361M [01:07<00:33, 4.12MB/s]
62%|██████▏ | 226M/361M [01:07<00:30, 4.51MB/s]
63%|██████▎ | 226M/361M [01:07<00:27, 4.91MB/s]
63%|██████▎ | 227M/361M [01:07<00:29, 4.54MB/s]
63%|██████▎ | 228M/361M [01:07<00:27, 4.89MB/s]
63%|██████▎ | 228M/361M [01:08<00:29, 4.52MB/s]
63%|██████▎ | 229M/361M [01:08<00:26, 5.09MB/s]
64%|██████▎ | 230M/361M [01:08<00:30, 4.39MB/s]
64%|██████▎ | 230M/361M [01:08<00:27, 4.84MB/s]
64%|██████▍ | 231M/361M [01:08<00:27, 4.69MB/s]
64%|██████▍ | 232M/361M [01:08<00:27, 4.72MB/s]
64%|██████▍ | 233M/361M [01:08<00:28, 4.56MB/s]
65%|██████▍ | 233M/361M [01:09<00:27, 4.62MB/s]
65%|██████▍ | 234M/361M [01:09<00:28, 4.53MB/s]
65%|██████▍ | 235M/361M [01:09<00:29, 4.33MB/s]
65%|██████▌ | 235M/361M [01:09<00:26, 4.82MB/s]
65%|██████▌ | 236M/361M [01:09<00:26, 4.77MB/s]
66%|██████▌ | 237M/361M [01:09<00:25, 4.82MB/s]
66%|██████▌ | 238M/361M [01:10<00:26, 4.69MB/s]
66%|██████▌ | 239M/361M [01:10<00:24, 4.94MB/s]
66%|██████▋ | 240M/361M [01:10<00:25, 4.79MB/s]
67%|██████▋ | 241M/361M [01:10<00:25, 4.79MB/s]
67%|██████▋ | 242M/361M [01:10<00:25, 4.79MB/s]
67%|██████▋ | 242M/361M [01:10<00:24, 4.80MB/s]
67%|██████▋ | 243M/361M [01:11<00:26, 4.49MB/s]
67%|██████▋ | 244M/361M [01:11<00:27, 4.28MB/s]
68%|██████▊ | 246M/361M [01:11<00:14, 7.89MB/s]
69%|██████▉ | 250M/361M [01:11<00:07, 14.5MB/s]
70%|███████ | 254M/361M [01:11<00:05, 20.4MB/s]
71%|███████ | 258M/361M [01:11<00:04, 24.0MB/s]
72%|███████▏ | 262M/361M [01:11<00:03, 27.5MB/s]
73%|███████▎ | 265M/361M [01:11<00:03, 29.5MB/s]
74%|███████▍ | 269M/361M [01:12<00:03, 30.5MB/s]
75%|███████▌ | 273M/361M [01:12<00:02, 32.1MB/s]
77%|███████▋ | 277M/361M [01:12<00:02, 34.2MB/s]
78%|███████▊ | 281M/361M [01:12<00:02, 35.9MB/s]
79%|███████▉ | 285M/361M [01:12<00:02, 37.3MB/s]
80%|███████▉ | 289M/361M [01:13<00:04, 15.6MB/s]
81%|████████ | 292M/361M [01:13<00:06, 10.2MB/s]
81%|████████ | 294M/361M [01:14<00:09, 7.41MB/s]
82%|████████▏ | 295M/361M [01:14<00:10, 6.49MB/s]
82%|████████▏ | 297M/361M [01:14<00:10, 6.02MB/s]
82%|████████▏ | 298M/361M [01:15<00:11, 5.42MB/s]
83%|████████▎ | 298M/361M [01:15<00:11, 5.27MB/s]
83%|████████▎ | 299M/361M [01:15<00:12, 5.10MB/s]
83%|████████▎ | 300M/361M [01:15<00:11, 5.26MB/s]
83%|████████▎ | 301M/361M [01:15<00:13, 4.48MB/s]
83%|████████▎ | 301M/361M [01:16<00:13, 4.47MB/s]
83%|████████▎ | 302M/361M [01:16<00:14, 4.03MB/s]
84%|████████▎ | 302M/361M [01:16<00:14, 4.05MB/s]
84%|████████▎ | 303M/361M [01:16<00:14, 4.08MB/s]
84%|████████▍ | 303M/361M [01:16<00:13, 4.40MB/s]
84%|████████▍ | 304M/361M [01:16<00:14, 4.00MB/s]
84%|████████▍ | 304M/361M [01:16<00:13, 4.13MB/s]
84%|████████▍ | 305M/361M [01:17<00:13, 4.09MB/s]
85%|████████▍ | 306M/361M [01:17<00:13, 4.26MB/s]
85%|████████▍ | 306M/361M [01:17<00:13, 4.16MB/s]
85%|████████▍ | 307M/361M [01:17<00:12, 4.41MB/s]
85%|████████▌ | 307M/361M [01:17<00:12, 4.31MB/s]
85%|████████▌ | 308M/361M [01:17<00:11, 4.47MB/s]
85%|████████▌ | 309M/361M [01:17<00:12, 4.33MB/s]
86%|████████▌ | 309M/361M [01:18<00:11, 4.56MB/s]
86%|████████▌ | 310M/361M [01:18<00:11, 4.33MB/s]
86%|████████▌ | 311M/361M [01:18<00:11, 4.56MB/s]
86%|████████▌ | 311M/361M [01:18<00:11, 4.34MB/s]
86%|████████▋ | 312M/361M [01:18<00:10, 4.63MB/s]
86%|████████▋ | 313M/361M [01:18<00:11, 4.38MB/s]
87%|████████▋ | 313M/361M [01:18<00:10, 4.80MB/s]
87%|████████▋ | 314M/361M [01:19<00:11, 4.03MB/s]
87%|████████▋ | 314M/361M [01:19<00:10, 4.34MB/s]
87%|████████▋ | 315M/361M [01:19<00:10, 4.26MB/s]
87%|████████▋ | 315M/361M [01:19<00:12, 3.55MB/s]
87%|████████▋ | 316M/361M [01:19<00:11, 3.87MB/s]
88%|████████▊ | 317M/361M [01:19<00:10, 4.06MB/s]
88%|████████▊ | 318M/361M [01:20<00:11, 3.96MB/s]
88%|████████▊ | 319M/361M [01:20<00:10, 4.00MB/s]
88%|████████▊ | 319M/361M [01:20<00:10, 4.14MB/s]
89%|████████▊ | 320M/361M [01:20<00:09, 4.21MB/s]
89%|████████▊ | 321M/361M [01:20<00:09, 4.33MB/s]
89%|████████▉ | 321M/361M [01:20<00:09, 4.38MB/s]
89%|████████▉ | 322M/361M [01:21<00:09, 4.10MB/s]
89%|████████▉ | 323M/361M [01:21<00:08, 4.43MB/s]
89%|████████▉ | 323M/361M [01:21<00:09, 4.20MB/s]
90%|████████▉ | 324M/361M [01:21<00:08, 4.51MB/s]
90%|████████▉ | 324M/361M [01:21<00:08, 4.18MB/s]
90%|████████▉ | 325M/361M [01:21<00:07, 4.56MB/s]
90%|█████████ | 326M/361M [01:21<00:08, 4.19MB/s]
90%|█████████ | 326M/361M [01:21<00:07, 4.59MB/s]
90%|█████████ | 327M/361M [01:22<00:08, 4.18MB/s]
91%|█████████ | 328M/361M [01:22<00:07, 4.63MB/s]
91%|█████████ | 328M/361M [01:22<00:07, 4.21MB/s]
91%|█████████ | 329M/361M [01:22<00:07, 4.65MB/s]
91%|█████████ | 330M/361M [01:22<00:07, 4.22MB/s]
91%|█████████▏| 330M/361M [01:22<00:06, 4.67MB/s]
92%|█████████▏| 331M/361M [01:23<00:07, 4.23MB/s]
92%|█████████▏| 331M/361M [01:23<00:06, 4.68MB/s]
92%|█████████▏| 332M/361M [01:23<00:07, 4.19MB/s]
92%|█████████▏| 333M/361M [01:23<00:06, 4.69MB/s]
92%|█████████▏| 333M/361M [01:23<00:07, 4.01MB/s]
92%|█████████▏| 334M/361M [01:23<00:07, 3.51MB/s]
92%|█████████▏| 334M/361M [01:23<00:07, 3.65MB/s]
93%|█████████▎| 335M/361M [01:24<00:07, 3.63MB/s]
93%|█████████▎| 335M/361M [01:24<00:07, 3.71MB/s]
93%|█████████▎| 336M/361M [01:24<00:06, 3.98MB/s]
93%|█████████▎| 336M/361M [01:24<00:05, 4.42MB/s]
93%|█████████▎| 337M/361M [01:24<00:06, 3.99MB/s]
93%|█████████▎| 338M/361M [01:24<00:05, 3.96MB/s]
94%|█████████▎| 339M/361M [01:25<00:05, 3.94MB/s]
94%|█████████▍| 339M/361M [01:25<00:05, 4.11MB/s]
94%|█████████▍| 340M/361M [01:25<00:05, 4.21MB/s]
94%|█████████▍| 341M/361M [01:25<00:04, 4.28MB/s]
95%|█████████▍| 342M/361M [01:25<00:04, 4.27MB/s]
95%|█████████▍| 343M/361M [01:25<00:04, 4.38MB/s]
95%|█████████▌| 344M/361M [01:26<00:04, 4.16MB/s]
95%|█████████▌| 344M/361M [01:26<00:04, 4.31MB/s]
95%|█████████▌| 345M/361M [01:26<00:04, 4.01MB/s]
96%|█████████▌| 345M/361M [01:26<00:04, 3.87MB/s]
96%|█████████▌| 346M/361M [01:26<00:03, 4.14MB/s]
96%|█████████▌| 346M/361M [01:26<00:03, 3.80MB/s]
96%|█████████▌| 347M/361M [01:26<00:03, 4.52MB/s]
96%|█████████▌| 348M/361M [01:27<00:03, 4.11MB/s]
96%|█████████▋| 348M/361M [01:27<00:03, 3.81MB/s]
96%|█████████▋| 348M/361M [01:27<00:03, 3.77MB/s]
97%|█████████▋| 349M/361M [01:27<00:03, 3.72MB/s]
97%|█████████▋| 350M/361M [01:27<00:03, 3.53MB/s]
97%|█████████▋| 350M/361M [01:27<00:02, 3.85MB/s]
97%|█████████▋| 351M/361M [01:28<00:02, 4.05MB/s]
97%|█████████▋| 352M/361M [01:28<00:02, 4.12MB/s]
98%|█████████▊| 353M/361M [01:28<00:02, 4.22MB/s]
98%|█████████▊| 354M/361M [01:28<00:01, 4.29MB/s]
98%|█████████▊| 355M/361M [01:28<00:01, 4.34MB/s]
98%|█████████▊| 355M/361M [01:29<00:01, 4.37MB/s]
99%|█████████▊| 356M/361M [01:29<00:01, 4.39MB/s]
99%|█████████▊| 357M/361M [01:29<00:01, 4.10MB/s]
99%|█████████▉| 358M/361M [01:29<00:00, 4.15MB/s]
99%|█████████▉| 358M/361M [01:29<00:00, 4.57MB/s]
99%|█████████▉| 359M/361M [01:30<00:01, 2.49MB/s]
99%|█████████▉| 359M/361M [01:30<00:00, 2.68MB/s]
100%|█████████▉| 360M/361M [01:30<00:00, 3.19MB/s]
100%|█████████▉| 361M/361M [01:30<00:00, 3.30MB/s]
100%|█████████▉| 361M/361M [01:30<00:00, 3.83MB/s]
100%|██████████| 361M/361M [01:30<00:00, 3.98MB/s]
Finally, we create the data loaders.
train_ssl_loader = DataLoader(
ssl_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
pin_memory=True,
num_workers=num_workers,
)
train_xy_loader = DataLoader(
train_xy_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False,
pin_memory=True,
num_workers=num_workers,
)
test_xy_loader = DataLoader(
test_xy_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False,
pin_memory=True,
num_workers=num_workers,
)
Model architecture¶
We use the 3D vision transformer from nidl as backbone.
encoder = VisionTransformer3D(
img_size=img_size,
patch_size=8,
in_chans=1,
embed_dim=256,
depth=6,
num_heads=8,
mlp_ratio=4.0,
)
Training the I-JEPA model¶
We either train a compact I-JEPA model directly, or load a pretrained checkpoint from the Hugging Face Hub (which was trained with the same configuration).
model = IJEPA(
encoder=encoder,
dim=3,
context_block_scale=(0.85, 1.0),
target_block_scale=(0.15, 0.2),
aspect_ratio=(0.75, 1.5),
num_target_blocks=4,
min_keep=4,
allow_overlap=False,
predictor_embed_dim=256,
predictor_depth_pred=6,
learning_rate=learning_rate,
optimizer="adamW",
weight_decay=weight_decay,
max_epochs=max_epochs,
check_val_every_n_epoch=1,
use_distributed_sampler=False,
enable_checkpointing=False,
accelerator=accelerator,
devices=1,
random_state=random_seed,
)
if not load_pretrained:
model.fit(train_ssl_loader)
else:
weights = Weights(
f"hf-hub:{hf_repo_id}",
data_dir=model_dir,
filepath=hf_checkpoint,
)
weights.load_pretrained(model)
model.fitted_ = True
Evaluation with a linear probe¶
Once pretraining is complete, we extract frozen representations and fit a logistic regression classifier on top of them.
X_train, y_train = model.transform_with_targets(train_xy_loader)
X_test, y_test = model.transform_with_targets(test_xy_loader)
X_train = X_train.cpu().numpy()
y_train = y_train.cpu().numpy().reshape(-1)
X_test = X_test.cpu().numpy()
y_test = y_test.cpu().numpy().reshape(-1)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61/61 0:00:53 • 0:00:00 1.16it/s
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 39/39 0:00:33 • 0:00:00 1.18it/s
We train linear probes on increasing fractions of the labeled training set to assess sample efficiency.
estimator = LogisticRegression(
max_iter=1000, random_state=random_seed, n_jobs=1
)
train_sizes = np.unique(
np.logspace(
np.log10(max(10, len(X_train) // 20)),
np.log10(len(X_train)),
8,
dtype=int,
)
)
accs = []
for size in train_sizes:
estimator.fit(X_train[:size], y_train[:size])
y_pred = estimator.predict(X_test)
accs.append(accuracy_score(y_test, y_pred))
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
We plot the scaling curve.
plt.plot(train_sizes / len(X_train), accs)
plt.ylim(0, 1)
plt.ylabel("Accuracy")
plt.xlabel("Proportion of labeled training samples")
plt.xscale("log")
plt.text(
train_sizes[-1] / len(X_train),
accs[-1],
f"{accs[-1]:.2f}",
ha="right",
va="bottom",
)
plt.text(
train_sizes[0] / len(X_train),
accs[0],
f"{accs[0]:.2f}",
ha="left",
va="bottom",
)
plt.show()
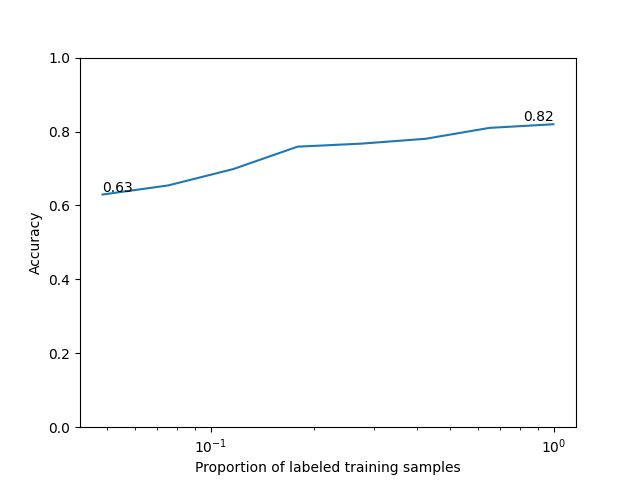
This example shows how to train and evaluate the I-JEPA model on MedMNIST3D
using nidl. The same pipeline can be applied to other 3D medical imaging
datasets, and you can also expand it to include more complex training setups
with logging and callbacks.
Total running time of the script: (3 minutes 24.986 seconds)
Estimated memory usage: 656 MB