Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
nidl.estimators.ssl.DCL¶
- class nidl.estimators.ssl.DCL(encoder, encoder_kwargs=None, proj_input_dim=2048, proj_hidden_dim=2048, proj_output_dim=128, temperature=0.1, optimizer='adamW', learning_rate=0.0003, weight_decay=0.0005, exclude_bias_and_norm_wd=True, optimizer_kwargs=None, lr_scheduler='warmup_cosine', lr_scheduler_kwargs=None, **kwargs)[source]¶
Bases:
TransformerMixin,BaseEstimatorDecoupled Contrastive Learning [1].
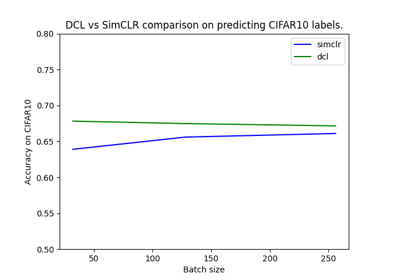
Decoupled Contrastive Learning (DCL) is a contrastive learning framework for self-supervised representation learning. It builds upon SimCLR [2] but removes the positive-negative coupling in InfoNCE loss that biases training in small batch sizes. See
SimCLR. for an introduction on contrastive learning.- Parameters:
- encodernn.Module or class of nn.Module
The encoder architecture. It can be given as an already instantiated module or as a class of module (in which case it will be instantiated with encoder_kwargs). It must be compatible with its projection head, i.e. its output dimension.
- encoder_kwargsdict or None, default=None
Options for building the encoder (depends on each architecture). Ignored if encoder is instantiated.
- proj_input_dimint, default=2048
Projector input dimension. It must be consistent with encoder’s output dimension.
- proj_hidden_dimint, default=2048
Projector hidden dimension.
- proj_output_dimint, default=128
Projector output dimension.
- temperaturefloat, default=0.1
The DCL loss temperature parameter.
- optimizer{‘sgd’, ‘adam’, ‘adamW’} or torch.optim.Optimizer or type,
default=”adamW” Optimizer for training the model. If a string is given, it can be:
‘sgd’: Stochastic Gradient Descent (with optional momentum).
‘adam’: First-order gradient-based optimizer.
‘adamW’ (default): Adam with decoupled weight decay regularization (see “Decoupled Weight Decay Regularization”, Loshchilov and Hutter, ICLR 2019).
- learning_ratefloat, default=3e-4
Initial learning rate.
- weight_decayfloat, default=5e-4
Weight decay in the optimizer.
- exclude_bias_and_norm_wdbool, default=True
Whether the bias terms and normalization layers get weight decay during optimization or not.
- optimizer_kwargsdict or None, default=None
Extra named arguments for the optimizer.
- lr_scheduler{“none”, “warmup_cosine”}, LRSchedulerPLType or None,
default=”warmup_cosine” Learning rate scheduler to use.
- lr_scheduler_kwargsdict or None, default=None
Extra named arguments for the scheduler. By default, it is set to {“warmup_epochs”: 10, “warmup_start_lr”: 1e-6, “min_lr”: 0.0, “interval”: “step”}
- **kwargsdict, optional
Additional keyword arguments for the BaseEstimator class, such as max_epochs, max_steps, num_sanity_val_steps, check_val_every_n_epoch, callbacks, etc.
- Attributes:
- encodertorch.nn.Module
Deep neural network mapping input data to low-dimensional vectors.
- projection_headtorch.nn.Module
Projector that maps encoder output to latent space for loss optimization.
- lossDCLLoss
The DCL loss function used for training.
- optimizertorch.optim.Optimizer
Optimizer used for training.
- lr_schedulerLRSchedulerPLType or None
Learning rate scheduler used for training.
References
[1]Yeh, Chun-Hsiao, et al. “Decoupled contrastive learning.” European conference on computer vision. Cham: Springer Nature Switzerland, https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136860653.pdf
[2]Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton, “A Simple Framework for Contrastive Learning of Visual Representations”, ICML 2020.
- __init__(encoder, encoder_kwargs=None, proj_input_dim=2048, proj_hidden_dim=2048, proj_output_dim=128, temperature=0.1, optimizer='adamW', learning_rate=0.0003, weight_decay=0.0005, exclude_bias_and_norm_wd=True, optimizer_kwargs=None, lr_scheduler='warmup_cosine', lr_scheduler_kwargs=None, **kwargs)[source]¶
- training_step(batch, batch_idx, dataloader_idx=0)[source]¶
Perform one training step and computes training loss.
- Parameters:
- batch: Sequence[Any]
A batch of data from the train dataloader. Supported formats are
[X1, X2]or([X1, X2], y), whereX1andX2are tensors representing two augmented views of the same samples.- batch_idx: int
The index of the current batch (ignored).
- dataloader_idx: int, default=0
The index of the dataloader (ignored).
- Returns:
- outputsdict
- Dictionary containing:
“loss”: the DCL loss computed on this batch (scalar);
“z1”: tensor of shape (batch_size, n_features);
“z2”: tensor of shape (batch_size, n_features);
“y”: eventual targets (returned as is).
- transform_step(batch, batch_idx, dataloader_idx=0)[source]¶
Encode the input data into the latent space.
Importantly, we do not apply the projection head here since it is not part of the final model at inference time (only used for training).
- Parameters:
- batch: torch.Tensor
A batch of data that has been generated from test_dataloader. This is given as is to the encoder.
- batch_idx: int
The index of the current batch (ignored).
- dataloader_idx: int, default=0
The index of the dataloader (ignored).
- Returns:
- features: torch.Tensor
The encoded features returned by the encoder.
- validation_step(batch, batch_idx, dataloader_idx=0)[source]¶
Perform one validation step and computes validation loss.
- Parameters:
- batch: Sequence[Any]
A batch of data from the validation dataloader. Supported formats are
[X1, X2]or([X1, X2], y).- batch_idx: int
The index of the current batch (ignored).
- dataloader_idx: int, default=0
The index of the dataloader (ignored).
- Returns:
- outputsdict
- Dictionary containing:
“loss”: the DCL loss computed on this batch (scalar);
“z1”: tensor of shape (batch_size, n_features);
“z2”: tensor of shape (batch_size, n_features);
“y”: eventual targets (returned as is).