Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
nidl.losses.InfoNCE¶
- class nidl.losses.InfoNCE(temperature=0.1)[source]¶
Bases:
ModuleImplementation of the InfoNCE loss [1], [2].
This loss function encourages the model to maximize the similarity between positive pairs while minimizing the similarity between negative pairs.
Given a mini-batch of size
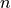 , we obtain two embeddings
, we obtain two embeddings
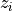 and
and 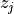 representing two different augmented
views of the same sample. The InfoNCE (or NT-Xent) loss used in
is defined as:
representing two different augmented
views of the same sample. The InfoNCE (or NT-Xent) loss used in
is defined as:![\mathcal{L}_i
= -\log
\frac{
\exp\!\big(\operatorname{sim}(z_i, z_j)/\tau\big)
}{
\sum\limits_{k=1}^{2N}
\mathbf{1}_{[k \ne i]}\,
\exp\!\big(\operatorname{sim}(z_i, z_k)/\tau\big)
}](../../_images/math/ab5b0b7ea2133f9c61419fa9277c49540468e324.png)
where
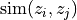 denotes the cosine similarity
between the normalized embeddings
denotes the cosine similarity
between the normalized embeddings 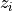 and
and 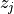 , and
, and
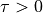 is a temperature parameter controlling the concentration
of the distribution.
is a temperature parameter controlling the concentration
of the distribution.- Parameters:
- temperature: float, default=0.1
Scale logits by the inverse of the temperature.
References
[1]Aaron van den Oord, Yazhe Li, and Oriol Vinyals. “Representation learning with contrastive predictive coding.” arXiv preprint arXiv:1807.03748 (2018).
[2]Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. “A simple framework for contrastive learning of visual representations.” In ICML 2020.