Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
nidl.estimators.BaseEstimator¶
- class nidl.estimators.BaseEstimator(callbacks=None, check_val_every_n_epoch=1, val_check_interval=None, num_sanity_val_steps=None, max_epochs=None, min_epochs=None, max_steps=-1, min_steps=None, enable_checkpointing=None, enable_progress_bar=None, enable_model_summary=None, accelerator='auto', strategy='auto', devices='auto', num_nodes=1, precision=None, save_hparams=True, ignore=None, random_state=None, **kwargs)[source]¶
Bases:
LightningModuleBase class for all estimators in the NIDL framework designed for scalability.
Inherits from PyTorch Lightning’s LightningModule. This class provides a common interface for training, validation, and prediction/transformation in a distributed setting (multi-node multi-GPU) inheriting from the Lightning’s Trainer capabilities.
It also provides a common interface for logging metrics, saving hyperparameters and handling callbacks, which are modular pieces of code that hook into the training loop without modifying your model code. They can be used for a variety of purposes, such as early stopping, model checkpointing, model’s probing, metrics computations, etc.
This class provides:
a
fitmethod.a
transformif the child class inherits fromTransformerMixina
transform_with_targetsmethod if the child class inherits fromTransformerMixina
predictmethod if the child class inherits fromRegressorMixin(for regression) orClassifierMixin(for classification) orClusterMixin(for clustering)
- Parameters:
- callbacks: list of Callback or Callback, default=None
add a callback or list of callbacks.
- check_val_every_n_epoch: int, default=1
perform a validation loop after every N training epochs. If
None, validation will be done solely based on the number of training batches, requiringval_check_intervalto be an integer value.- val_check_interval: int or float, default=None
how often to check the validation set. Pass a
floatin the range [0.0, 1.0] to check after a fraction of the training epoch. Pass anintto check after a fixed number of training batches. Anintvalue can only be higher than the number of training batches whencheck_val_every_n_epoch=None, which validates after everyNtraining batches across epochs or during iteration-based training. Default:1.0.- num_sanity_val_steps: int, default=None
Sanity check runs n validation batches before starting the training routine. Set it to -1 to run all batches in all validation dataloaders. Default:
2.- max_epochs: int, default=None
stop training once this number of epochs is reached. If both max_epochs and max_steps are not specified, defaults to
max_epochs = 1000. To enable infinite training, setmax_epochs = -1.- min_epochs: int, default=None
force training for at least these many epochs. Disabled by default.
- max_steps: int, default -1
stop training after this number of steps. If
max_steps = -1andmax_epochs = None, will default tomax_epochs = 1000. To enable infinite training, setmax_epochsto-1.- min_steps: int, default=None
force training for at least these number of steps. Disabled by default.
- enable_checkpointing: bool, default=None
if
True, enable checkpointing. It will configure a default ModelCheckpoint callback if there is no user-defined ModelCheckpoint in trainer callbacks. Default:True.- enable_progress_bar: bool, default=None
whether to enable to progress bar by default. Default:
True.- enable_model_summary: bool, default=None
whether to enable model summarization by default. Default:
True.- accelerator: str or Accelerator, default=”auto”
supports passing different accelerator types (“cpu”, “gpu”, “tpu”, “hpu”, “mps”, “auto”) as well as custom accelerator instances.
- strategy: str or Strategy, default=”auto”
supports different training strategies with aliases as well custom strategies.
- devices: listof int, str, int, default=”auto”
the devices to use. Can be set to a positive number (int or str), a sequence of device indices (list or str), the value
-1to indicate all available devices should be used, or"auto"for automatic selection based on the chosen accelerator.- num_nodes: int, default=1
number of GPU nodes for distributed training.
- precision: int or str, default=”32-true”
double precision (64, ‘64’ or ‘64-true’), full precision (32, ‘32’ or ‘32-true’), 16bit mixed precision (16, ‘16’, ‘16-mixed’) or bfloat16 mixed precision (‘bf16’, ‘bf16-mixed’). Can be used on CPU, GPU, TPUs, or HPUs.
- save_hparams: bool, default=True
Whether to save the hyper-parameters of this estimator or not.
- ignore: list of str, default=None
Attributes to be ignored when saving the hyperparameters of the estimator. This is particularly useful for ignoring
Moduleattributes and callbacks.- random_state: int, default=None
when shuffling is used, random_state affects the ordering of the indices, which controls the randomness of each batch. Pass an int for reproducible output across multiple function calls.
- kwargs: dict
lightning’s trainer extra parameters.
- Attributes:
- fitted
a boolean that is True if the estimator has been fitted, and is False otherwise.
- hparams:
contains the estimator hyperparameters.
- trainer
the current lightning trainer.
- trainer_params
a dictionaray with the trainer parameters.
Notes
Callbacks can help you to tune, monitor or debug an estimator. For instance you can check the type of the input batches using BatchTypingCallback callback.
- __init__(callbacks=None, check_val_every_n_epoch=1, val_check_interval=None, num_sanity_val_steps=None, max_epochs=None, min_epochs=None, max_steps=-1, min_steps=None, enable_checkpointing=None, enable_progress_bar=None, enable_model_summary=None, accelerator='auto', strategy='auto', devices='auto', num_nodes=1, precision=None, save_hparams=True, ignore=None, random_state=None, **kwargs)[source]¶
- fit(train_dataloader, val_dataloader=None)[source]¶
The fit method.
In the child class you will need to define:
a training_step method for defining the training instructions at each step.
a validation_step method for defining the validation instructions at each step.
- Parameters:
- train_dataloader: torch DataLoader
training samples.
- val_dataloader: torch DataLoader, default None
validation samples.
- Returns:
- self: object
fitted estimator.
- property fitted¶
- log(name, value, prog_bar=False, logger=None, on_step=None, on_epoch=None, reduce_fx='mean', enable_graph=False, sync_dist=False, sync_dist_group=None, add_dataloader_idx=True, batch_size=None, metric_attribute=None, rank_zero_only=False)[source]¶
Log a key, value pair.
- Parameters:
- name: str
key to log. Must be identical across all processes if using DDP or any other distributed strategy.
- value: object
value to log. Can be a
float,Tensor, or aMetric.- prog_bar: bool, default=False
if
Truelogs to the progress bar.- logger: bool, default=None
if
Truelogs to the logger.- on_step: bool, default=None
if
Truelogs at this step. The default value is determined by the hook.- on_epoch: bool, default=None
if
Truelogs epoch accumulated metrics. The default value is determined by the hook.- reduce_fx: str of callable, default=’mean’
reduction function over step values for end of epoch.
torch.meanby default.- enable_graph: bool, default=False
if
True, will not auto detach the graph.- sync_dist: bool, default=False
if
True, reduces the metric across devices. Use with care as this may lead to a significant communication overhead.- sync_dist_group: object, default=None
the DDP group to sync across.
- add_dataloader_idx: bool, default=True
if
True, appends the index of the current dataloader to the name (when using multiple dataloaders). IfFalse, user needs to give unique names for each dataloader to not mix the values.- batch_size: int, default=None
current batch_size. This will be directly inferred from the loaded batch, but for some data structures you might need to explicitly provide it.
- metric_attribute: str, default=None
to restore the metric state, Lightning requires the reference of the
torchmetrics.Metricin your model. This is found automatically if it is a model attribute.- rank_zero_only: bool, default=False
tells Lightning if you are calling
self.logfrom every process (default) or only from rank 0. IfTrue, you won’t be able to use this metric as a monitor in callbacks (e.g., early stopping). Warning: Improper use can lead to deadlocks!
Examples
>>> self.log('train_loss', loss)
- log_dict(dictionary, prog_bar=False, logger=None, on_step=None, on_epoch=None, reduce_fx='mean', enable_graph=False, sync_dist=False, sync_dist_group=None, add_dataloader_idx=True, batch_size=None, rank_zero_only=False)[source]¶
Log a dictionary of values at once.
- Parameters:
- dictionary: dict
key value pairs. Keys must be identical across all processes if using DDP or any other distributed strategy. The values can be a
float,Tensor,Metric, orMetricCollection.- prog_bar: bool, default=False
if
Truelogs to the progress bar.- logger: bool, default=None
if
Truelogs to the logger.- on_step: bool, default=None
Noneauto-logs for training_step but not validation/test_step. The default value is determined by the hook.- on_epoch: bool, default=None
Noneauto-logs for val/test step but nottraining_step. The default value is determined by the hook.- reduce_fx: str of callable, default=’mean’
reduction function over step values for end of epoch.
torch.meanby default.- enable_graph: bool, default=False
if
True, will not auto detach the graph.- sync_dist: bool, default=False
if
True, reduces the metric across devices. Use with care as this may lead to a significant communication overhead.- sync_dist_group: object, default=None
the DDP group to sync across.
- add_dataloader_idx: bool, default=True
if
True, appends the index of the current dataloader to the name (when using multiple dataloaders). IfFalse, user needs to give unique names for each dataloader to not mix the values.- batch_size: int, default=None
current batch_size. This will be directly inferred from the loaded batch, but for some data structures you might need to explicitly provide it.
- rank_zero_only: bool, default=False
tells Lightning if you are calling
self.logfrom every process (default) or only from rank 0. IfTrue, you won’t be able to use this metric as a monitor in callbacks (e.g., early stopping). Warning: Improper use can lead to deadlocks!
Examples
>>> values = {'loss': loss, 'acc': acc, ..., 'metric_n': metric_n} >>> self.log_dict(values)
- on_load_checkpoint(checkpoint)[source]¶
Hook that is called when using the load_from_checkpoint method.
- predict(test_dataloader)[source]¶
The predict method for regression, classification and clustering.
In the child class you will need to define:
a predict_step method for defining the predict instructions at each step.
- Parameters:
- test_dataloader: torch DataLoader
testing samples.
- Returns:
- out: torch Tensor
returns predicted samples.
- predict_step(batch, batch_idx, dataloader_idx=0)[source]¶
Step function called during
predict. By default, it callsforward. Override to add any processing logic.The
predict_stepis used to scale inference on multi-devices.To prevent an OOM error, it is possible to use
BasePredictionWritercallback to write the predictions to disk or database after each batch or on epoch end.The
BasePredictionWritershould be used while using a spawn based accelerator. This happens for training strategystrategy="ddp_spawn"or training on 8 TPU cores withaccelerator="tpu", devices=8as predictions won’t be returned.- Parameters:
- batch: iterable, normally a :class:`~torch.utils.data.DataLoader`
the current data.
- batch_idx: int
the index of this batch.
- dataloader_idx: int, default=0
the index of the dataloader that produced this batch (only if multiple dataloaders are used).
- Returns:
- out: Any
the predicted output.
- property trainer_params¶
- training_step(batch, batch_idx, dataloader_idx=0)[source]¶
Here you compute and return the training loss and some additional metrics for e.g. the progress bar or logger.
- Parameters:
- batch: Any
Output of your training loader iterable, normally a
DataLoader- batch_idx: int
the index of this batch.
- dataloader_idx: int, default=0
the index of the dataloader that produced this batch (only if multiple dataloaders are used).
- Returns:
- loss: STEP_OUTPUT
the computed loss:
Tensor- the loss tensor.dict- a dictionary which can include any keys, but must include the key'loss'in the case of automatic optimization.None- in automatic optimization, this will skip to the next batch (but is not supported for multi-GPU, TPU, or DeepSpeed). For manual optimization, this has no special meaning, as returning the loss is not required.
- To use multiple optimizers, you can switch to ‘manual optimization’
- and control their stepping:
Notes
When
accumulate_grad_batches> 1, the loss returned here will be automatically normalized byaccumulate_grad_batchesinternally.Examples
>>> def __init__(self): >>> super().__init__() >>> self.automatic_optimization = False >>> >>> >>> # Multiple optimizers (e.g.: GANs) >>> def training_step(self, batch, batch_idx): >>> opt1, opt2 = self.optimizers() >>> >>> # do training_step with encoder >>> ... >>> opt1.step() >>> # do training_step with decoder >>> ... >>> opt2.step()
- transform(test_dataloader)[source]¶
The transform method for transformer.
In the child class you will need to define:
a transform_step method for defining the transform instructions at each step.
- Parameters:
- test_dataloader: torch DataLoader
testing samples.
- Returns:
- out: torch Tensor
returns transformed samples.
Notes
Since we expect a tensor as output of the model, it is gathered across GPUs in the multi-gpu distributed case and the output is stored on the relevant device defined by the trainer’s strategy (cpu or gpu).
- abstractmethod transform_step(batch, batch_idx, dataloader_idx=0)[source]¶
Define a transform step.
Share the same API as
BaseEstimator.predict_step.
- transform_step_with_targets(batch, batch_idx, dataloader_idx=0)[source]¶
Step function called during
transform_with_targets.transform_with_targetsis used to scale the inference step of embedding estimators to multi-devices.- Parameters:
- batch: Any
Output of your test loader iterable, normally a
DataLoader. It expects batches of the form(x, y)where onlyxis processed by thetransform_stepandyis returned as-is.- batch_idx: int
the index of this batch.
- dataloader_idx: int, default=0
the index of the dataloader that produced this batch (only if multiple dataloaders are used).
- Returns:
- dict[str, Any]
Dictionary with keys
"features"and"targets"and values should betorch.Tensor.
- transform_with_targets(test_dataloader)[source]¶
Return transformed samples and associated targets.
A default
transform_step_with_targetsmethod is available but it can be overrides to define your own logic.- Parameters:
- test_dataloader: torch DataLoader
Testing samples. By default, the form expected is
(x, y)whereyis the target andxthe input. This logic can be overrides by rewriting your owntransform_step_with_targets.
- Returns:
- features, targets: torch Tensor, torch.Tensor
Transformed samples and associated targets.
Notes
Outputs are gathered across GPUs in distributed settings, similarly to
transform.
- validation_step(batch, batch_idx, dataloader_idx=0)[source]¶
Operates on a single batch of data from the validation set. In this step you’d might generate examples or calculate anything of interest like accuracy.
- Parameters:
- batch: Any
Output of your validation loader iterable, normally a
DataLoader- batch_idx: int
the index of this batch.
- dataloader_idx: int, default=0
the index of the dataloader that produced this batch (only if multiple dataloaders are used).
- Returns:
- loss: STEP_OUTPUT
the computed loss:
Tensor- the loss tensor.dict- a dictionary. can include any keys, but must include the key'loss'.None- skip to the next batch.
Notes
If you don’t need to validate you don’t need to implement this method.
When the
validation_stepis called, the model has been put in eval mode and PyTorch gradients have been disabled. At the end of validation, the model goes back to training mode and gradients are enabled.
Examples using nidl.estimators.BaseEstimator¶
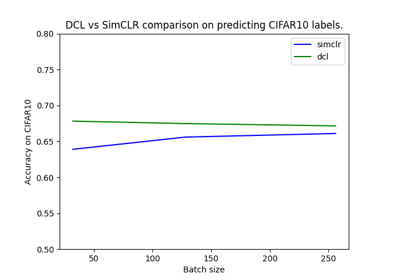

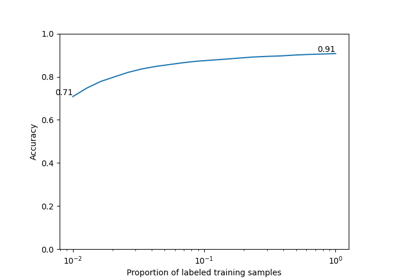
Self-Supervised Contrastive Learning with SimCLR on MNIST
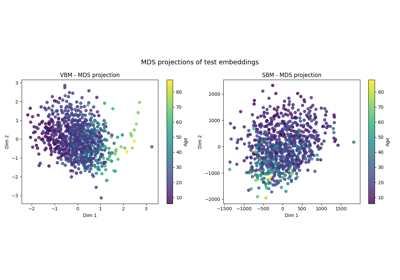
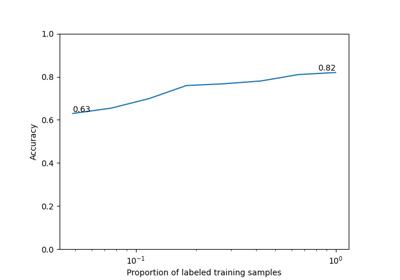
Self-Supervised Learning with I-JEPA on MedMNIST3D

Visualization of metrics during training of PyTorch-Lightning models
Weakly Supervised Contrastive Learning with y-Aware