Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
nidl.losses.DCLLoss¶
- class nidl.losses.DCLLoss(temperature=0.1, pos_weight_fn=None)[source]¶
Bases:
ModuleImplementation of the Decoupled Contrastive Learning loss [1]
This loss function implements the decoupled contrastive learning loss as described in [1]. It builds upon the classic InfoNCE loss but removes the positive-negative coupling that biases training in small batch sizes.
Given a mini-batch of size
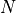 , we obtain two embeddings
, we obtain two embeddings
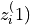 and
and 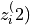 representing two different
augmented views of the same sample. The DCL loss is defined as:
representing two different
augmented views of the same sample. The DCL loss is defined as:![\mathcal{L}_i^{(k)}
= - \big(\operatorname{sim}(z_i^{(1)}, z_i^{(2)})/\tau\big)
+ \log
\sum\limits_{l \in \{1,2\}, j \in \![1,N\!]}
\mathbf{1}_{[j \ne i]},
\exp\!\big(\operatorname{sim}(z_i^{(k)}, z_j^{(l)})/\tau\big)](../../_images/math/b3ee4cfb31b08d23eb79b52e97c0f07fda0d7870.png)
where
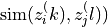 denotes the cosine
similarity between the normalized embeddings
denotes the cosine
similarity between the normalized embeddings 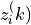 and
and
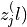 , and
, and 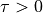 is a temperature parameter
controlling the concentration of the distribution.
is a temperature parameter
controlling the concentration of the distribution.
![\mathbf{1}_{[j \ne i]}](../../_images/math/01c2cfb0d00fb1132ac748d4d5c272ecc6462ad0.png) ensures decoupling.
ensures decoupling.Additionnaly, a weighting function
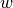 can be added to modulate the
contribution of the positive pairs’ similarity to the loss. The intuition
is that when the embedding of the positive sample
can be added to modulate the
contribution of the positive pairs’ similarity to the loss. The intuition
is that when the embedding of the positive sample 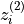 is
close to the anchor
is
close to the anchor 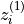 , there is less learning signal than
when the two embeddings are less similar. The weighted loss is:
, there is less learning signal than
when the two embeddings are less similar. The weighted loss is:![\mathcal{L}_i^{(k)}
= - w(z_i^{(1)}, z_i^{(2)})
\big(\operatorname{sim}(z_i^{(1)}, z_i^{(2)})/\tau\big)
+ \log
\sum\limits_{l \in \{1,2\}, j \in \![1,N\!]}
\mathbf{1}_{[j \ne i]},
\exp\!\big(\operatorname{sim}(z_i^{(k)}, z_j^{(l)})/\tau\big)](../../_images/math/63d92bf7799ce30bf1894e0f92880336029c4aa9.png)
See the class
DCLWLossfor an implementation with a negative von Mises-Fisher weighting function such as proposed in [1].- Parameters:
- temperature: float, default=0.1
Scale logits by the inverse of the temperature.
- pos_weight_fn: Optional[callable], default=None
Weighting function of the positive pairs (
in [1]).
It is a callable that takes two tensors 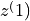 and
and 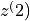 as inputs and returns the weights
as inputs and returns the weights 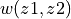 as a tensor.
If None, a DCL loss without weighting is returned.
as a tensor.
If None, a DCL loss without weighting is returned.
References
[1] (1,2,3,4)Yeh, Chun-Hsiao, et al. “Decoupled contrastive learning.” European conference on computer vision. Cham: Springer Nature Switzerland, https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136860653.pdf