Note
Go to the end to download the full example code.
Model probing of embedding estimators¶
This notebook will show you how to investigate the data representation given by an embedding estimator (such as SimCLR, y-Aware Contrastive Learning or Barlow Twins) during training and inference using the notion of “probing”. A standard machine learning model (e.g. linear or SVM) is trained and evaluated on the data embedding for a given task as the model is being fitted (for training monitoring) or at inference. It allows the user to understand what concepts are learned by the model.
This has been first introduced by Guillaume Alain and Yoshua Bengio in 2017 [1] to understand the internal behavior of a deep neural network along the different layers. This technique aimed at answering questions like: what is the intermediate representation of a neural network? What information is contained for a given layer ?
Then, it has been adapted to benchmark self-supervised vision models (like SimCLR, Barlow Twins, DINO, DINOv2, DINOv3) on classical datasets (ImageNet, CIFAR, …) by implementing linear probing and K-Nearest Neighbors probing on model’s output representation.
Setup¶
This notebook requires some packages besides nidl. Let’s first start with importing our standard libraries below:
import os
import re
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as func
from sklearn.base import BaseEstimator as sk_BaseEstimator
from sklearn.base import clone
from sklearn.linear_model import LogisticRegression, Ridge
from sklearn.metrics import (
accuracy_score,
f1_score,
make_scorer,
r2_score,
)
from tensorboard.backend.event_processing import event_accumulator
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.ops import MLP
from torchvision.utils import make_grid
from nidl.callbacks import ModelProbingCallback
from nidl.estimators.probes import ModelProbing
from nidl.datasets import OpenBHB
from nidl.estimators.ssl import SimCLR, YAwareContrastiveLearning
from nidl.metrics import pearson_r
from nidl.transforms.transforms import MultiViewsTransform
We define some global parameters that will be used throughout the notebook:
data_dir = "/tmp/mnist"
batch_size = 128
num_workers = 10
latent_size = 32
Unsupervised Contrastive Learning on MNIST¶
For illustration purposes on how to use the probing callback, we will focus on the handwritten digits dataset MNIST. It contains 60k training images and 10k test images of size 28x28 pixels. Each image contains a digit from 0 to 9. It is rather small-scale compared to modern datasets like ImageNet but sufficient to illustrate the probing technique. We will train a SimCLR model on these data and probe the learned representation using a logistic regression classifier on the digit classification task. It will show how the data embedding evolves during training to become more linearly separable for each digit class.
We start by loading the MNIST dataset dataset with standard scaling transforms. These datasets are used for training and testing the probing.
scale_transforms = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
train_xy_dataset = MNIST(data_dir, download=True, transform=scale_transforms)
test_xy_dataset = MNIST(
data_dir, download=True, train=False, transform=scale_transforms
)
0%| | 0.00/9.91M [00:00<?, ?B/s]
86%|████████▌ | 8.49M/9.91M [00:00<00:00, 82.8MB/s]
100%|██████████| 9.91M/9.91M [00:00<00:00, 83.5MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 5.92MB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 38.1MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 13.8MB/s]
Dataset and data augmentations for contrastive learning¶
To perform contrastive learning, we need to define a set of data augmentations to create multiple views of the same image. Since we work with grayscale images, we will use random resized crop and Gaussian blur. We reduce the size of the Gaussian kernel to 3x3 since MNIST images are only 28x28 pixels.
contrast_transforms = transforms.Compose(
[
transforms.RandomResizedCrop(size=28, scale=(0.8, 1.0)),
transforms.GaussianBlur(kernel_size=3),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
]
)
We create the datasets returning the augmented views for training the SSL models.
ssl_dataset = MNIST(
data_dir,
download=True,
transform=MultiViewsTransform(contrast_transforms, n_views=2),
)
test_ssl_dataset = MNIST(
data_dir,
download=True,
train=False,
transform=MultiViewsTransform(contrast_transforms, n_views=2),
)
And finally we create the data loaders for training and testing the models.
train_xy_loader = DataLoader(
train_xy_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=False,
pin_memory=True,
num_workers=num_workers,
)
test_xy_loader = DataLoader(
test_xy_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=num_workers,
)
train_ssl_loader = DataLoader(
ssl_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=num_workers,
)
test_ssl_loader = DataLoader(
test_ssl_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=num_workers,
)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:424: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
Before starting training the SimCLR model, let’s visualize some examples of the dataset.
def show_images(images, title=None, nrow=8):
grid = make_grid(images, nrow=nrow, normalize=True, pad_value=1)
plt.figure(figsize=(10, 5))
plt.imshow(grid.permute(1, 2, 0).cpu())
if title:
plt.title(title)
plt.axis("off")
plt.show()
# Original and augmented images
images, labels = next(iter(test_xy_loader))
augmented_views, _ = next(iter(test_ssl_loader))
view1, view2 = augmented_views[0], augmented_views[1]
fig, axes = plt.subplots(2, 3, figsize=(6, 4))
for i in range(2):
axes[i, 0].imshow(images[i][0].cpu(), cmap="gray")
axes[i, 0].set_title(f"Original (label={labels[i].item()})")
axes[i, 0].axis("off")
axes[i, 1].imshow(view1[i][0].cpu(), cmap="gray")
axes[i, 1].set_title("Augmented View 1")
axes[i, 1].axis("off")
axes[i, 2].imshow(view2[i][0].cpu(), cmap="gray")
axes[i, 2].set_title("Augmented View 2")
axes[i, 2].axis("off")
plt.tight_layout()
plt.show()

/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
SimCLR training with classification probing callback¶
We can now create the probing callback that will train a logistic regression classifier on the learned representation during SimCLR training. The probing is performed every 2 epochs on the training and test sets. The classification metrics (accuracy and f1-weighted) are logged to TensorBoard by default.
callback = ModelProbingCallback(
train_xy_loader,
test_xy_loader,
probe=LogisticRegression(max_iter=200),
scoring=["accuracy", "f1_weighted"],
every_n_train_epochs=3,
)
Since MNIST images are small, we can use a simple LeNet-like architecture as encoder for SimCLR, with few parameters. The output dimension of the encoder is set to 32, which is approximately 30 times smaller that the input, but larger than the number of input classes (10).
class LeNetEncoder(nn.Module):
def __init__(self, latent_size=32):
super().__init__()
self.latent_size = latent_size
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=2)
self.pool1 = nn.AvgPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.pool2 = nn.AvgPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, latent_size)
def forward(self, x):
x = func.relu(self.conv1(x))
x = self.pool1(x)
x = func.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = func.relu(self.fc1(x))
x = func.relu(self.fc2(x))
return self.fc3(x)
encoder = LeNetEncoder(latent_size)
We can now create the SimCLR model with the encoder and the probing callback. We limit the training to 10 epochs for the sake of time and because it is enough for checking the evolution of the embedding geometry across training.
model = SimCLR(
encoder=encoder,
limit_train_batches=100,
proj_input_dim=latent_size,
proj_hidden_dim=64,
proj_output_dim=32,
max_epochs=10,
temperature=0.1,
learning_rate=3e-4,
weight_decay=5e-5,
enable_checkpointing=False,
callbacks=callback, # <-- key part for probing
)
model.fit(train_ssl_loader, test_ssl_loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
┏━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃
┡━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━┩
│ 0 │ encoder │ LeNetEncoder │ 63.6 K │ train │ 0 │
│ 1 │ projection_head │ SimCLRProjectionHead │ 4.2 K │ train │ 0 │
│ 2 │ loss │ InfoNCE │ 0 │ train │ 0 │
└───┴─────────────────┴──────────────────────┴────────┴───────┴───────┘
Trainable params: 67.8 K
Non-trainable params: 0
Total params: 67.8 K
Total estimated model params size (MB): 0.271
Modules in train mode: 14
Modules in eval mode: 0
Total FLOPs: 0
Extracting features: 0it [00:00, ?it/s]
Extracting features: 2it [00:00, 10.43it/s]
Extracting features: 15it [00:00, 55.94it/s]
Extracting features: 25it [00:00, 71.27it/s]
Extracting features: 34it [00:00, 76.83it/s]
Extracting features: 45it [00:00, 85.62it/s]
Extracting features: 55it [00:00, 88.50it/s]
Extracting features: 67it [00:00, 95.33it/s]
Extracting features: 79it [00:00, 98.99it/s]
Extracting features: 90it [00:01, 97.85it/s]
Extracting features: 100it [00:01, 97.61it/s]
Extracting features: 110it [00:01, 98.07it/s]
Extracting features: 121it [00:01, 100.70it/s]
Extracting features: 132it [00:01, 99.45it/s]
Extracting features: 142it [00:01, 98.34it/s]
Extracting features: 153it [00:01, 99.75it/s]
Extracting features: 163it [00:01, 99.69it/s]
Extracting features: 173it [00:01, 98.32it/s]
Extracting features: 183it [00:02, 98.22it/s]
Extracting features: 195it [00:02, 101.69it/s]
Extracting features: 206it [00:02, 98.72it/s]
Extracting features: 217it [00:02, 99.29it/s]
Extracting features: 228it [00:02, 101.55it/s]
Extracting features: 239it [00:02, 99.04it/s]
Extracting features: 250it [00:02, 99.58it/s]
Extracting features: 261it [00:02, 102.44it/s]
Extracting features: 272it [00:02, 98.64it/s]
Extracting features: 283it [00:03, 100.26it/s]
Extracting features: 294it [00:03, 98.37it/s]
Extracting features: 304it [00:03, 97.92it/s]
Extracting features: 314it [00:03, 97.06it/s]
Extracting features: 325it [00:03, 99.21it/s]
Extracting features: 336it [00:03, 102.20it/s]
Extracting features: 347it [00:03, 103.58it/s]
Extracting features: 358it [00:03, 99.15it/s]
Extracting features: 368it [00:03, 97.58it/s]
Extracting features: 379it [00:03, 99.32it/s]
Extracting features: 389it [00:04, 97.04it/s]
Extracting features: 400it [00:04, 100.59it/s]
Extracting features: 411it [00:04, 101.18it/s]
Extracting features: 422it [00:04, 100.32it/s]
Extracting features: 433it [00:04, 102.63it/s]
Extracting features: 444it [00:04, 102.69it/s]
Extracting features: 459it [00:04, 115.99it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:00, 6.20it/s]
Extracting features: 12it [00:00, 52.28it/s]
Extracting features: 22it [00:00, 70.24it/s]
Extracting features: 31it [00:00, 76.83it/s]
Extracting features: 42it [00:00, 87.37it/s]
Extracting features: 52it [00:00, 86.57it/s]
Extracting features: 69it [00:00, 111.25it/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:00, 7.53it/s]
Extracting features: 8it [00:00, 39.10it/s]
Extracting features: 19it [00:00, 67.40it/s]
Extracting features: 29it [00:00, 77.61it/s]
Extracting features: 40it [00:00, 87.98it/s]
Extracting features: 51it [00:00, 95.04it/s]
Extracting features: 61it [00:00, 90.31it/s]
Extracting features: 71it [00:00, 92.28it/s]
Extracting features: 81it [00:00, 91.71it/s]
Extracting features: 91it [00:01, 91.15it/s]
Extracting features: 101it [00:01, 92.75it/s]
Extracting features: 111it [00:01, 93.96it/s]
Extracting features: 122it [00:01, 94.95it/s]
Extracting features: 133it [00:01, 98.14it/s]
Extracting features: 143it [00:01, 96.96it/s]
Extracting features: 153it [00:01, 94.86it/s]
Extracting features: 163it [00:01, 94.63it/s]
Extracting features: 173it [00:01, 94.30it/s]
Extracting features: 184it [00:02, 98.03it/s]
Extracting features: 194it [00:02, 98.17it/s]
Extracting features: 204it [00:02, 96.99it/s]
Extracting features: 215it [00:02, 99.20it/s]
Extracting features: 225it [00:02, 97.42it/s]
Extracting features: 236it [00:02, 99.32it/s]
Extracting features: 246it [00:02, 96.94it/s]
Extracting features: 256it [00:02, 96.46it/s]
Extracting features: 266it [00:02, 96.22it/s]
Extracting features: 276it [00:03, 94.05it/s]
Extracting features: 287it [00:03, 96.48it/s]
Extracting features: 297it [00:03, 95.81it/s]
Extracting features: 308it [00:03, 98.81it/s]
Extracting features: 319it [00:03, 97.32it/s]
Extracting features: 330it [00:03, 95.84it/s]
Extracting features: 341it [00:03, 97.88it/s]
Extracting features: 351it [00:03, 94.53it/s]
Extracting features: 361it [00:03, 92.81it/s]
Extracting features: 372it [00:04, 94.54it/s]
Extracting features: 382it [00:04, 93.35it/s]
Extracting features: 392it [00:04, 95.09it/s]
Extracting features: 403it [00:04, 96.55it/s]
Extracting features: 413it [00:04, 96.78it/s]
Extracting features: 424it [00:04, 98.60it/s]
Extracting features: 434it [00:04, 96.58it/s]
Extracting features: 444it [00:04, 96.05it/s]
Extracting features: 459it [00:04, 110.94it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:00, 9.60it/s]
Extracting features: 6it [00:00, 30.79it/s]
Extracting features: 16it [00:00, 60.87it/s]
Extracting features: 27it [00:00, 77.23it/s]
Extracting features: 37it [00:00, 84.86it/s]
Extracting features: 48it [00:00, 92.72it/s]
Extracting features: 59it [00:00, 95.93it/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 200 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=200).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:00, 9.73it/s]
Extracting features: 5it [00:00, 24.75it/s]
Extracting features: 16it [00:00, 60.60it/s]
Extracting features: 27it [00:00, 77.06it/s]
Extracting features: 36it [00:00, 79.46it/s]
Extracting features: 49it [00:00, 91.77it/s]
Extracting features: 59it [00:00, 93.23it/s]
Extracting features: 70it [00:00, 96.00it/s]
Extracting features: 80it [00:00, 95.01it/s]
Extracting features: 90it [00:01, 96.46it/s]
Extracting features: 100it [00:01, 95.16it/s]
Extracting features: 111it [00:01, 98.36it/s]
Extracting features: 121it [00:01, 96.60it/s]
Extracting features: 131it [00:01, 92.00it/s]
Extracting features: 142it [00:01, 96.38it/s]
Extracting features: 153it [00:01, 98.62it/s]
Extracting features: 163it [00:01, 89.44it/s]
Extracting features: 173it [00:01, 91.24it/s]
Extracting features: 183it [00:02, 92.91it/s]
Extracting features: 193it [00:02, 91.81it/s]
Extracting features: 203it [00:02, 92.50it/s]
Extracting features: 213it [00:02, 92.05it/s]
Extracting features: 223it [00:02, 93.00it/s]
Extracting features: 233it [00:02, 89.82it/s]
Extracting features: 243it [00:02, 91.59it/s]
Extracting features: 253it [00:02, 91.92it/s]
Extracting features: 263it [00:02, 92.68it/s]
Extracting features: 273it [00:03, 92.65it/s]
Extracting features: 283it [00:03, 92.63it/s]
Extracting features: 293it [00:03, 93.29it/s]
Extracting features: 303it [00:03, 93.96it/s]
Extracting features: 313it [00:03, 91.70it/s]
Extracting features: 323it [00:03, 93.57it/s]
Extracting features: 333it [00:03, 93.37it/s]
Extracting features: 343it [00:03, 92.22it/s]
Extracting features: 353it [00:03, 92.74it/s]
Extracting features: 363it [00:04, 93.35it/s]
Extracting features: 374it [00:04, 97.48it/s]
Extracting features: 384it [00:04, 98.00it/s]
Extracting features: 394it [00:04, 96.71it/s]
Extracting features: 404it [00:04, 96.55it/s]
Extracting features: 414it [00:04, 94.86it/s]
Extracting features: 424it [00:04, 93.85it/s]
Extracting features: 434it [00:04, 95.23it/s]
Extracting features: 445it [00:04, 95.70it/s]
Extracting features: 462it [00:04, 116.33it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:00, 7.35it/s]
Extracting features: 9it [00:00, 43.52it/s]
Extracting features: 19it [00:00, 66.58it/s]
Extracting features: 29it [00:00, 77.66it/s]
Extracting features: 38it [00:00, 81.40it/s]
Extracting features: 49it [00:00, 88.12it/s]
Extracting features: 59it [00:00, 89.40it/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 200 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=200).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 2it [00:00, 15.31it/s]
Extracting features: 7it [00:00, 30.30it/s]
Extracting features: 18it [00:00, 62.40it/s]
Extracting features: 29it [00:00, 77.40it/s]
Extracting features: 41it [00:00, 90.69it/s]
Extracting features: 52it [00:00, 96.44it/s]
Extracting features: 62it [00:00, 95.90it/s]
Extracting features: 72it [00:00, 96.20it/s]
Extracting features: 82it [00:00, 94.82it/s]
Extracting features: 92it [00:01, 96.22it/s]
Extracting features: 102it [00:01, 96.64it/s]
Extracting features: 112it [00:01, 95.32it/s]
Extracting features: 122it [00:01, 94.23it/s]
Extracting features: 132it [00:01, 95.26it/s]
Extracting features: 143it [00:01, 96.94it/s]
Extracting features: 153it [00:01, 97.16it/s]
Extracting features: 163it [00:01, 96.24it/s]
Extracting features: 173it [00:01, 97.27it/s]
Extracting features: 183it [00:02, 97.17it/s]
Extracting features: 193it [00:02, 96.84it/s]
Extracting features: 204it [00:02, 99.34it/s]
Extracting features: 214it [00:02, 96.68it/s]
Extracting features: 224it [00:02, 95.23it/s]
Extracting features: 235it [00:02, 95.87it/s]
Extracting features: 245it [00:02, 94.74it/s]
Extracting features: 256it [00:02, 97.60it/s]
Extracting features: 266it [00:02, 96.40it/s]
Extracting features: 276it [00:02, 94.60it/s]
Extracting features: 286it [00:03, 95.31it/s]
Extracting features: 296it [00:03, 96.41it/s]
Extracting features: 307it [00:03, 99.40it/s]
Extracting features: 319it [00:03, 101.09it/s]
Extracting features: 330it [00:03, 101.80it/s]
Extracting features: 341it [00:03, 101.76it/s]
Extracting features: 352it [00:03, 98.06it/s]
Extracting features: 364it [00:03, 103.27it/s]
Extracting features: 375it [00:03, 101.37it/s]
Extracting features: 386it [00:04, 101.87it/s]
Extracting features: 397it [00:04, 98.87it/s]
Extracting features: 407it [00:04, 96.93it/s]
Extracting features: 418it [00:04, 97.96it/s]
Extracting features: 429it [00:04, 97.13it/s]
Extracting features: 440it [00:04, 98.83it/s]
Extracting features: 450it [00:04, 99.12it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:00, 8.37it/s]
Extracting features: 6it [00:00, 30.13it/s]
Extracting features: 17it [00:00, 63.05it/s]
Extracting features: 28it [00:00, 77.51it/s]
Extracting features: 39it [00:00, 83.79it/s]
Extracting features: 50it [00:00, 88.72it/s]
Extracting features: 63it [00:00, 100.96it/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 200 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=200).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
Epoch 9/9 ━━━━━━━━━━━━━━━━ 100/100 0:00:08 • 12.99it/s v_num: 0.000
0:00:00 loss/train: 0.632
loss/val: 1.087
test_accuracy:
0.885
test_f1_weighted:
0.885
SimCLR(
(encoder): LeNetEncoder(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(pool1): AvgPool2d(kernel_size=2, stride=2, padding=0)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool2): AvgPool2d(kernel_size=2, stride=2, padding=0)
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=32, bias=True)
)
(projection_head): SimCLRProjectionHead(
(layers): Sequential(
(0): Linear(in_features=32, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
)
)
(loss): InfoNCE(temperature=0.1)
)
Visualization of the classification metrics during training¶
After training, we can visualize the classification metrics logged by the linear probe using TensorBoard. The logged metrics are stored in the lightning_logs folder by default. They contain the accuracy, and f1-weighted scores.
def get_last_log_version(logs_dir="lightning_logs"):
versions = []
for d in os.listdir(logs_dir):
match = re.match(r"version_(\d+)", d)
if match:
versions.append(int(match.group(1)))
return max(versions) if versions else None
log_dir = f"lightning_logs/version_{get_last_log_version()}/"
ea = event_accumulator.EventAccumulator(log_dir)
ea.Reload()
metrics = [
"test_accuracy",
"test_f1_weighted",
]
scalars = {m: ea.Scalars(m) for m in metrics}
Once all the metrics are loaded, we plot them as the number of training steps increases:
plt.figure(figsize=(5, 3))
for m, events in scalars.items():
steps = [e.step for e in events]
values = [e.value for e in events]
plt.plot(steps, values, label=m)
plt.xlabel(f"Nb steps (batch size={batch_size})")
plt.ylabel("Metric score")
plt.title("Classification metrics during SimCLR training")
plt.legend()
plt.tight_layout()
plt.show()
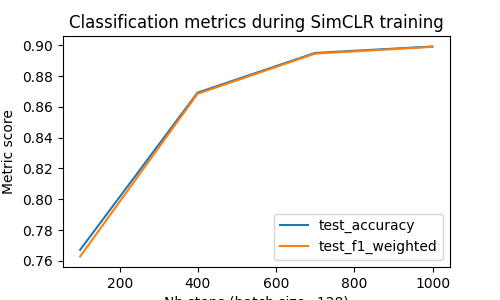
Observations: we can see that the classification metrics increase steadily during training, showing that the learned representation becomes more and more linearly separable for the digit classes. The accuracy reaches more than 80% after 10 epochs, which is quite good for such a simple model trained without supervision and a small number of epochs.
Classification metrics at inference¶
In addition to monitoring the classification metrics during training, we can also evaluate the linear probe at inference after training the SimCLR model.
probing = ModelProbing(
embedding_estimator=model, # <-- pass the trained SimCLR model as embedding estimator
probe=LogisticRegression(max_iter=200),
scoring=["accuracy", "f1_weighted"],
)
probing.fit(train_xy_loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:485: Your `predict_dataloader`'s sampler has shuffling enabled, it is strongly recommended that you turn shuffling off for val/test dataloaders.
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:424: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 469/469 0:00:04 • 0:00:00 105.30it/s
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 200 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=200).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
ModelProbing(
(embedding_estimator): SimCLR(
(encoder): LeNetEncoder(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(pool1): AvgPool2d(kernel_size=2, stride=2, padding=0)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool2): AvgPool2d(kernel_size=2, stride=2, padding=0)
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=32, bias=True)
)
(projection_head): SimCLRProjectionHead(
(layers): Sequential(
(0): Linear(in_features=32, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
)
)
(loss): InfoNCE(temperature=0.1)
)
)
We can now evaluate the probe on the test set and print the classification metrics:
scores = probing.score(test_xy_loader)
print("Classification metrics at inference:")
for metric, score in scores.items():
print(f"{metric}: {score:.4f}")
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:424: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
Predicting ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 79/79 0:00:00 • 0:00:00 107.02it/s
Classification metrics at inference:
accuracy: 0.8849
f1_weighted: 0.8845
Probing of y-Aware representation on age and sex prediction¶
We have previously seen a simple case where only one classification task is being monitored during training. We can also monitor a mixed of classification and regression tasks at the same time during training of an embedding model. This could be useful if several target variables should be monitored from the representation. We will show how to perform this with nidl using the ModelProbing callback on the OpenBHB dataset to monitor age and sex decoding from brain imaging data. We refer to the example on OpenBHB for more details on this neuroimaging dataset.
We define the relevant global parameters for this example:
data_dir = "/tmp/openBHB"
batch_size = 128
num_workers = 10
latent_size = 32
OpenBHB dataset and data augmentations¶
We consider the gray matter and CSF volumes on some regions of interests in the Neuromorphometrics atlas across subjects in OpenBHB (“vbm_roi” modality). These data are tabular (not images) but they are still well suited for contrastive learning and they are very light compared to the raw images (284-d vector for each subject). We start by loading these data for training and testing the probing callback. The target variables are age (regression) and sex (classification).
def target_transforms(labels):
return np.array([labels["age"], labels["sex"] == "female"])
train_xy_dataset = OpenBHB(
data_dir,
modality="vbm_roi",
target=["age", "sex"],
transforms=lambda x: x.flatten(),
target_transforms=target_transforms,
streaming=False,
)
test_xy_dataset = OpenBHB(
data_dir,
modality="vbm_roi",
split="val",
target=["age", "sex"],
transforms=lambda x: x.flatten(),
target_transforms=target_transforms,
streaming=False,
)
Fetching ... files: 0it [00:00, ?it/s]
Fetching ... files: 1it [00:00, 7557.30it/s]
Fetching ... files: 0it [00:00, ?it/s]
Fetching ... files: 1it [00:00, 15033.35it/s]
To perform contrastive learning, we will use random masking and Gaussian noise as data augmentations. These are well suited for tabular data. We will train a y-Aware Contrastive Learning model on these data, using age as auxiliary variable.
mask_prob = 0.8
noise_std = 0.5
contrast_transforms = transforms.Compose(
[
lambda x: x.flatten(),
lambda x: (np.random.rand(*x.shape) > mask_prob).astype(np.float32)
* x, # random masking
lambda x: x
+ (
(np.random.rand() > 0.5) * np.random.randn(*x.shape) * noise_std
).astype(np.float32), # random Gaussian noise
]
)
ssl_dataset = OpenBHB(
data_dir,
modality="vbm_roi",
target="age",
transforms=MultiViewsTransform(contrast_transforms, n_views=2),
)
test_ssl_dataset = OpenBHB(
data_dir,
modality="vbm_roi",
target="age",
split="val",
transforms=MultiViewsTransform(contrast_transforms, n_views=2),
)
As before, we create the data loaders for training and testing the models.
train_xy_loader = DataLoader(
train_xy_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=False,
pin_memory=True,
num_workers=num_workers,
)
test_xy_loader = DataLoader(
test_xy_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=num_workers,
)
train_ssl_loader = DataLoader(
ssl_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=num_workers,
)
test_ssl_loader = DataLoader(
test_ssl_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=num_workers,
)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:424: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
y-Aware CL training with multitask probing callback¶
Next, we create the multitask probing callback that will train a ridge regression on age and a logistic regression classifier on sex. The probing is performed every epoch on the training and test sets. The metrics are logged to TensorBoard by default.
To do so, we need to create a meta-estimator (compatible with scikit-learn) that wraps the two estimators (ridge and logistic regression) and handles the mixed regression/classification tasks. We provide such a meta-estimator called MultiTaskEstimator below.
class MultiTaskEstimator(sk_BaseEstimator):
"""
A meta-estimator that wraps a list of sklearn estimators
for multi-task problems (mixed regression/classification).
"""
def __init__(self, estimators):
self.estimators = estimators
def fit(self, X, y):
"""Fit each estimator on its corresponding column in y."""
y = np.asarray(y)
if y.ndim == 1:
y = y.reshape(-1, 1)
self.estimators_ = []
for i, est in enumerate(self.estimators):
fitted = clone(est).fit(X, y[:, i])
self.estimators_.append(fitted)
return self
def predict(self, X):
"""Predict for each task."""
preds = [est.predict(X).reshape(-1, 1) for est in self.estimators_]
return np.hstack(preds)
def score(self, X, y):
"""Average score across all tasks."""
y = np.asarray(y)
scores = []
for i, est in enumerate(self.estimators_):
scores.append(est.score(X, y[:, i]))
return np.mean(scores)
def __len__(self):
return len(self.estimators)
Then, we define a scorer specific for each task:
def make_task_scorer(metric_fn, task_index, **kwargs):
"""Returns a scorer evaluating on y or y[:, task_index]."""
def scorer(y_true, y_pred):
if task_index is None:
return metric_fn(y_true, y_pred)
else:
return metric_fn(y_true[:, task_index], y_pred[:, task_index])
return make_scorer(scorer, **kwargs)
Finally, we create the multitask probing callback with the relevant estimators and scorers for age and sex.
callback = ModelProbingCallback(
train_xy_loader,
test_xy_loader,
probe=MultiTaskEstimator([Ridge(), LogisticRegression(max_iter=200)]),
scoring={
"age/r2": make_task_scorer(r2_score, task_index=0),
"age/pearsonr": make_task_scorer(pearson_r, task_index=0),
"sex/accuracy": make_task_scorer(accuracy_score, task_index=1),
"sex/f1": make_task_scorer(f1_score, task_index=1),
},
every_n_train_epochs=3,
)
Since we work with tabular data, we can use a simple MLP as encoder for y-Aware Contrastive Learning. The input dimension is 284 and we compress the data to a 32-d latent space.
encoder = MLP(in_channels=284, hidden_channels=[64, latent_size])
We can now create the y-Aware Contrastive Learning model with the MLP encoder and the multitask probing callback. We limit the training to 10 epochs for the sake of time and we use a small bandwidth for the Gaussian kernel in the y-Aware model compared to the variance of the age in OpenBHB (sigma=4).
sigma = 4
model = YAwareContrastiveLearning(
encoder=encoder,
proj_input_dim=latent_size,
proj_hidden_dim=2 * latent_size,
proj_output_dim=latent_size,
bandwidth=sigma**2,
max_epochs=10,
temperature=0.1,
learning_rate=1e-3,
enable_checkpointing=False,
callbacks=callback, # <-- add callback to monitor the training
)
model.fit(train_ssl_loader, test_ssl_loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/pytorch_lightning/loops/fit_loop.py:321: The number of training batches (26) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
┏━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃
┡━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━┩
│ 0 │ encoder │ MLP │ 20.3 K │ train │ 0 │
│ 1 │ projection_head │ YAwareProjectionHead │ 4.2 K │ train │ 0 │
│ 2 │ loss │ YAwareInfoNCE │ 0 │ train │ 0 │
└───┴─────────────────┴──────────────────────┴────────┴───────┴───────┘
Trainable params: 24.5 K
Non-trainable params: 0
Total params: 24.5 K
Total estimated model params size (MB): 0.098
Modules in train mode: 13
Modules in eval mode: 0
Total FLOPs: 0
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:04, 4.15s/it]
Extracting features: 2it [00:04, 1.89s/it]
Extracting features: 4it [00:06, 1.38s/it]
Extracting features: 6it [00:06, 1.31it/s]
Extracting features: 14it [00:09, 2.41it/s]
Extracting features: 15it [00:09, 2.59it/s]
Extracting features: 17it [00:09, 3.28it/s]
Extracting features: 22it [00:09, 5.40it/s]
Extracting features: 24it [00:10, 4.93it/s]
Extracting features: 26it [00:10, 5.58it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:02, 2.55s/it]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:05, 5.23s/it]
Extracting features: 2it [00:06, 2.67s/it]
Extracting features: 7it [00:06, 1.79it/s]
Extracting features: 11it [00:07, 2.28it/s]
Extracting features: 13it [00:07, 2.81it/s]
Extracting features: 14it [00:08, 2.63it/s]
Extracting features: 17it [00:08, 3.68it/s]
Extracting features: 18it [00:08, 3.87it/s]
Extracting features: 21it [00:09, 3.49it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:02, 2.63s/it]
Extracting features: 2it [00:02, 1.26s/it]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:06, 6.75s/it]
Extracting features: 7it [00:06, 1.39it/s]
Extracting features: 11it [00:09, 1.53it/s]
Extracting features: 21it [00:10, 3.27it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:02, 2.77s/it]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 200 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=200).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:430: UserWarning: This DataLoader will create 10 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
self.check_worker_number_rationality()
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/torch/utils/data/dataloader.py:1095: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used.
super().__init__(loader)
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:06, 6.45s/it]
Extracting features: 11it [00:08, 1.58it/s]
Extracting features: 21it [00:09, 2.91it/s]
Extracting features: 0it [00:00, ?it/s]
Extracting features: 1it [00:01, 1.80s/it]
Extracting features: 2it [00:02, 1.17s/it]
Extracting features: 6it [00:02, 3.48it/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:456: OptimizeWarning: Unknown solver options: iprint
opt_res = optimize.minimize(
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:470: ConvergenceWarning: lbfgs failed to converge after 200 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=200).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
Epoch 9/9 ━━━━━━━━━━━━━━━━━ 26/26 0:00:11 • 0:00:00 3.59it/s v_num: 3.000
loss/train: 7.944
loss/val: 11.054
test_age/r2: 0.621
test_age/pearsonr:
0.793
test_sex/accuracy:
0.761 test_sex/f1:
0.743
YAwareContrastiveLearning(
(encoder): MLP(
(0): Linear(in_features=284, out_features=64, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=64, out_features=32, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
(projection_head): YAwareProjectionHead(
(layers): Sequential(
(0): Linear(in_features=32, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=32, bias=True)
)
)
(loss): YAwareInfoNCE(
(sim_metric): PairwiseCosineSimilarity()
)
)
Visualization of the classification and regression metrics during training¶
After training, we can visualize the classification and regression metrics logged by the model probing using TensorBoard. The logged metrics are stored in the lightning_logs folder by default.
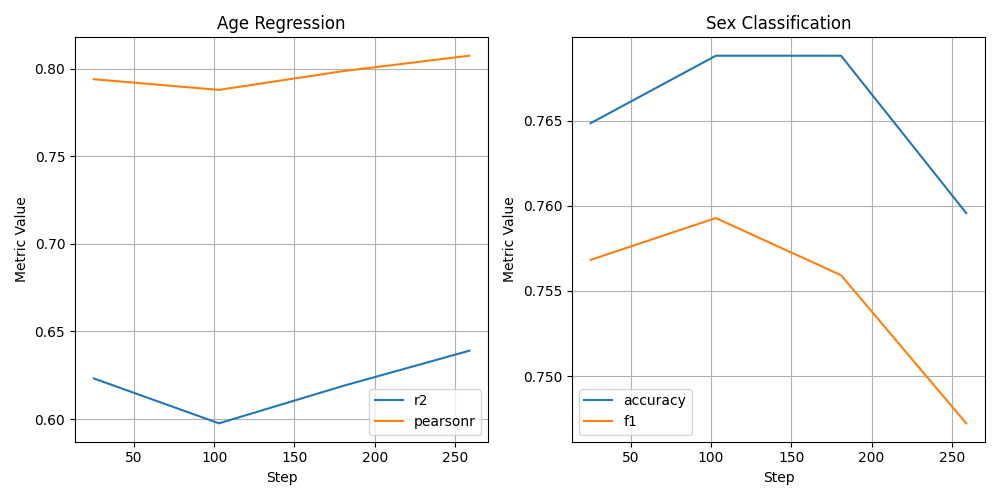
Once all the metrics are loaded, we plot them as the number of training steps increases. We create two subplots, one for each task (age regression and sex classification).
def plot_task(ax, task_metrics, title):
for m in task_metrics:
steps = [s.step for s in scalars[m]]
values = [s.value for s in scalars[m]]
ax.plot(steps, values, label=m.split("/")[1])
ax.set_title(title)
ax.set_xlabel("Step")
ax.set_ylabel("Metric Value")
ax.legend()
ax.grid(True)
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
plot_task(axes[0], ["test_age/r2", "test_age/pearsonr"], "Age Regression")
plot_task(axes[1], ["test_sex/accuracy", "test_sex/f1"], "Sex Classification")
plt.tight_layout()
plt.show()
Conclusions¶
In this notebook, we have shown how to use the model probing callbacks available in nidl to monitor the evolution of the data representation during training of embedding models such as SimCLR and y-Aware Contrastive Learning. We have seen how to use the ModelProbing callback for single-task probing and multi-task probing. These callbacks allow to train standard machine learning models (e.g. logistic regression, ridge regression, SVM) on the learned representation at regular intervals during training and log the relevant metrics to TensorBoard. This provides insights on what concepts are being learned by the model and how the representation evolves to become more suitable for downstream tasks.
Total running time of the script: (7 minutes 26.526 seconds)
Estimated memory usage: 263 MB